Overview
The Text Analytics powered by Azure AI Services connector for Bizagi is available for download at Bizagi Connector XChange.
Through this connector, you will be able to connect your Bizagi processes to your Microsoft Azure AI Services account and services. This means that you can detect languages, identify entities, obtain links to get more information about said entities, recognize known entities and key phrases, and identify the sentiment of a text directly from Bizagi.
For more information about this connector's capabilities, visit the Xchange platform.
|
This Connector was developed according to the contents of the API and the information about it provided by Microsoft Cognitive Services. Bizagi and its subsidiaries will not provide any kind of guarantee over the content or error caused by calling the API services. Bizagi and its subsidiaries are not responsible for any loss, cost or damage consequence of the calls to Microsoft Cognitive Services' API. |

Before you start
To test and use this connector, you will need:
1.Bizagi Studio previously installed.
2.The connector installed, either through the Connectors Xchange or via manual installation as outlined in the Installing and managing connectors article.
3.Add Azure AI services to your Azure subscription.
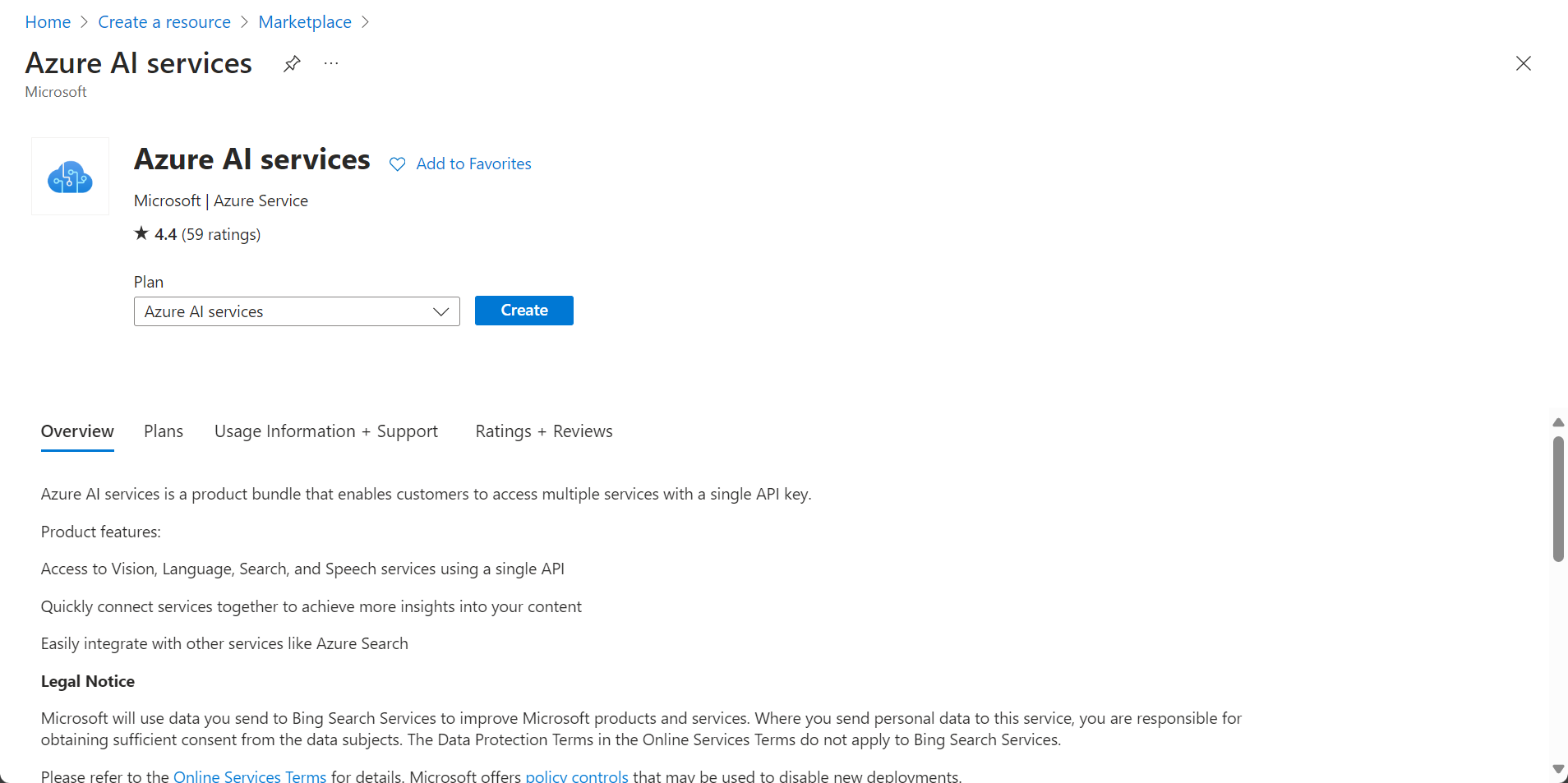
To configure Azure AI follow these steps:
1.Create the new service. Go to the Azure Portal and click the Create a resource button.
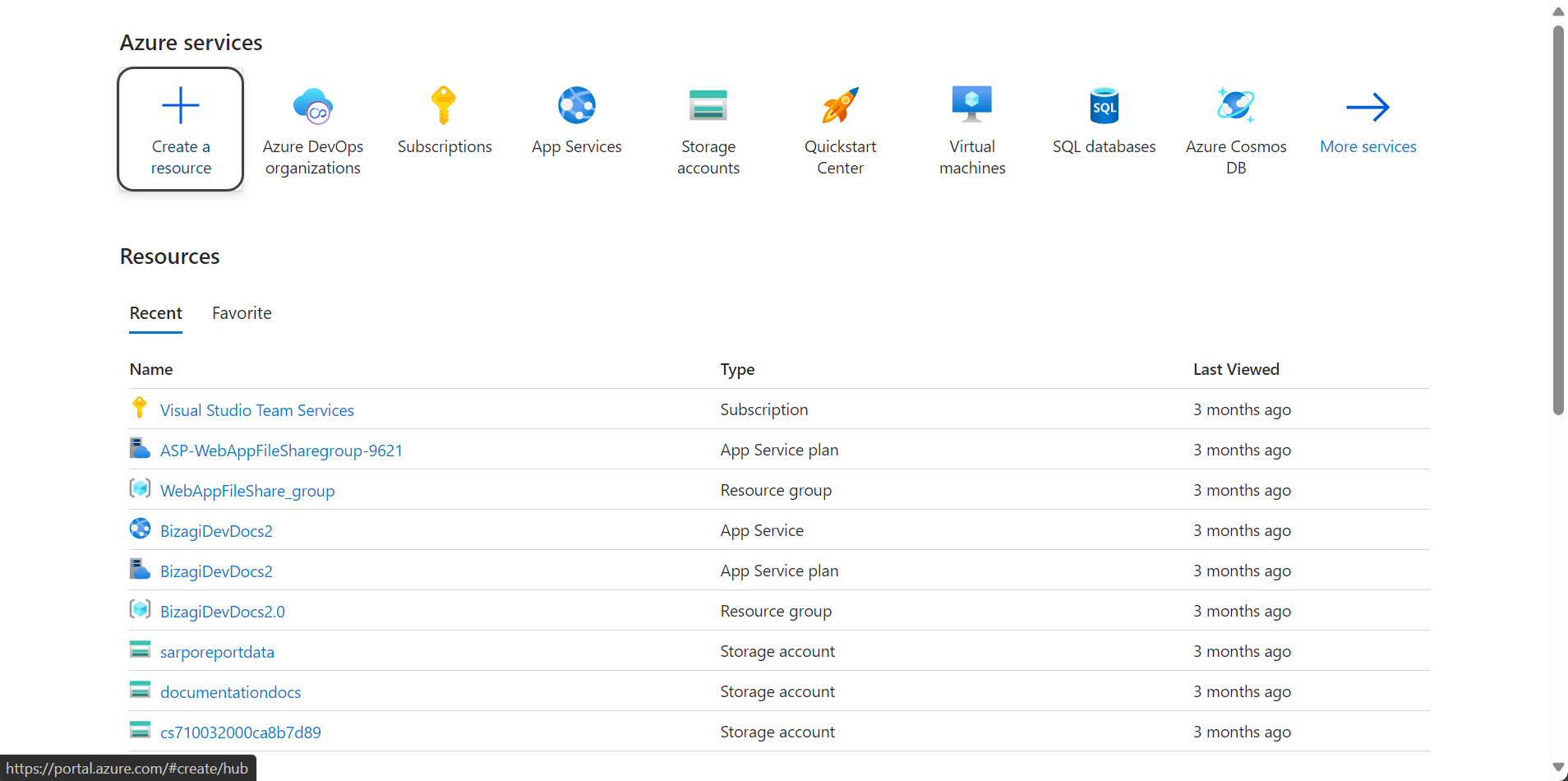
2.Search for "Azure AI Services": Find and select the option with the blue logo, as shown in the following image.
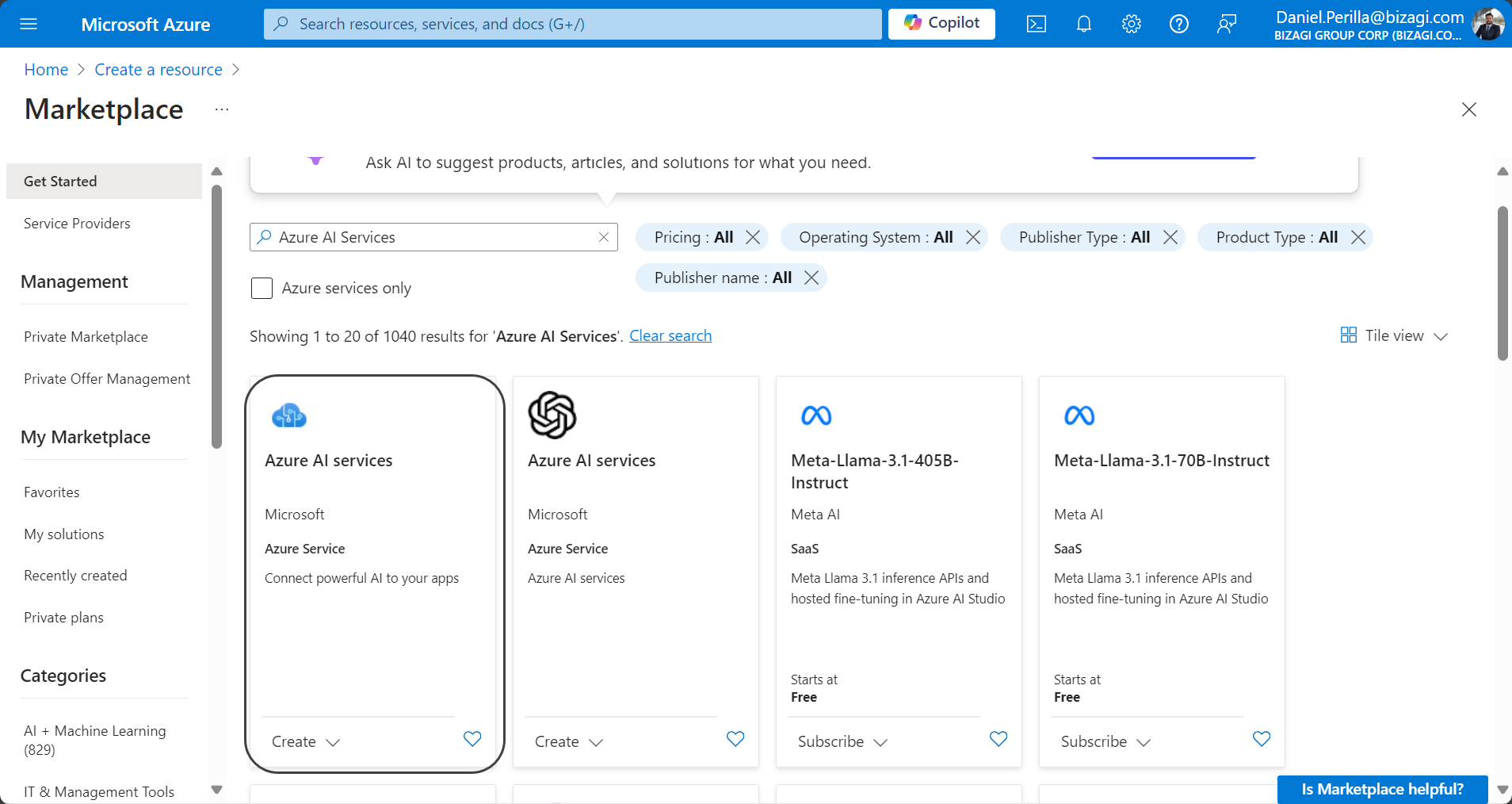
3.Select the plan that best suits your needs according to the options listed in the Plan dropdown menu, and click Create.
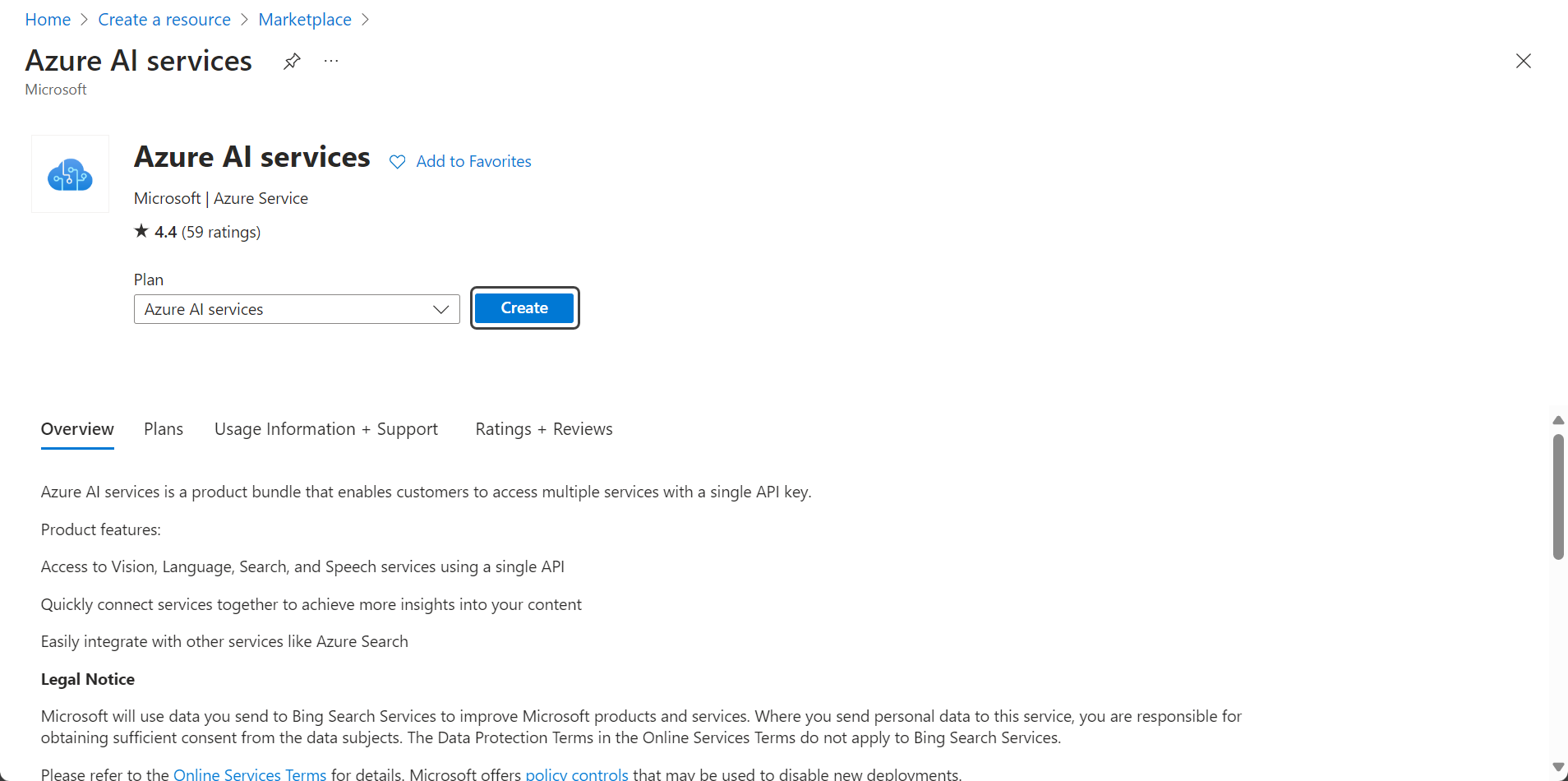
4.Then, configure the new service: Set it up according to your preferences. Keep in mind that the value you define in the Name text box is the value you will need to use in the "SERVICE_NAME" configuration property. Fill in the required fields and click the Review + create button.
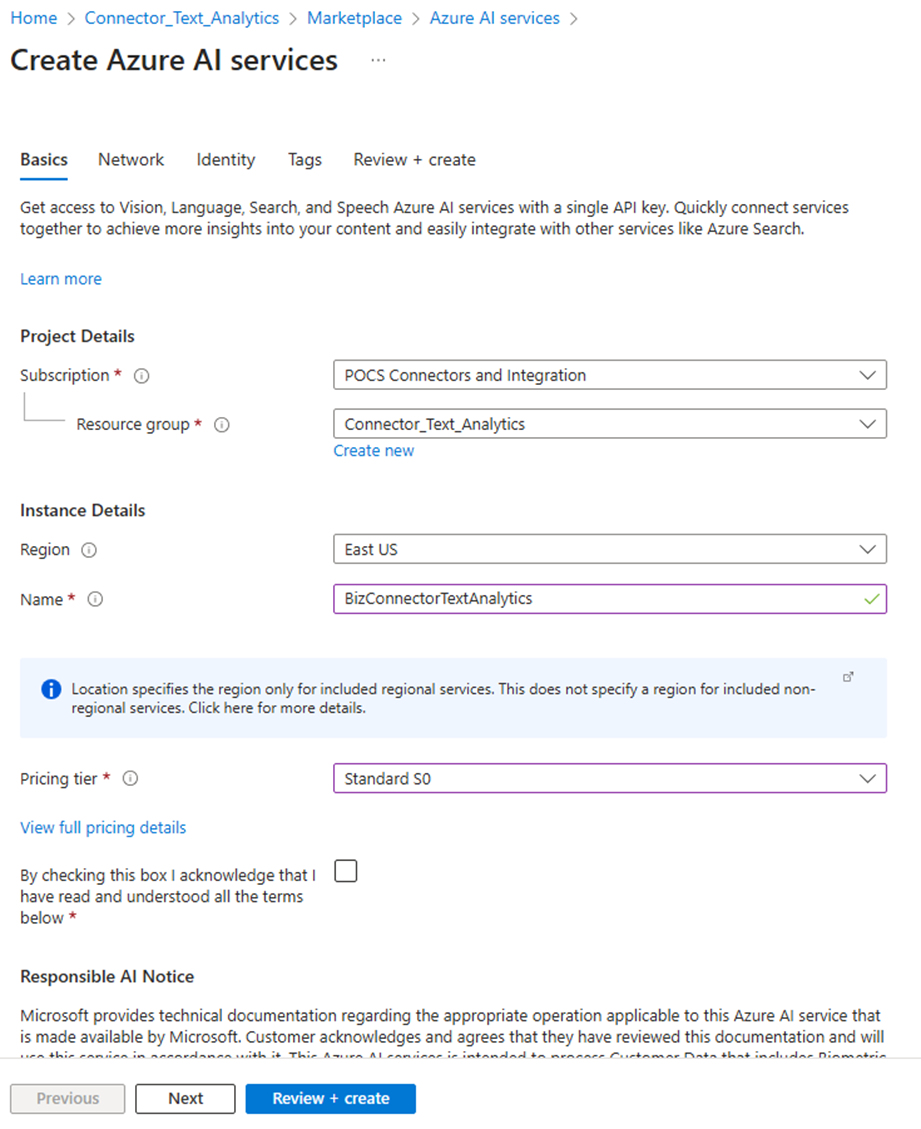
5.Click the Create button.
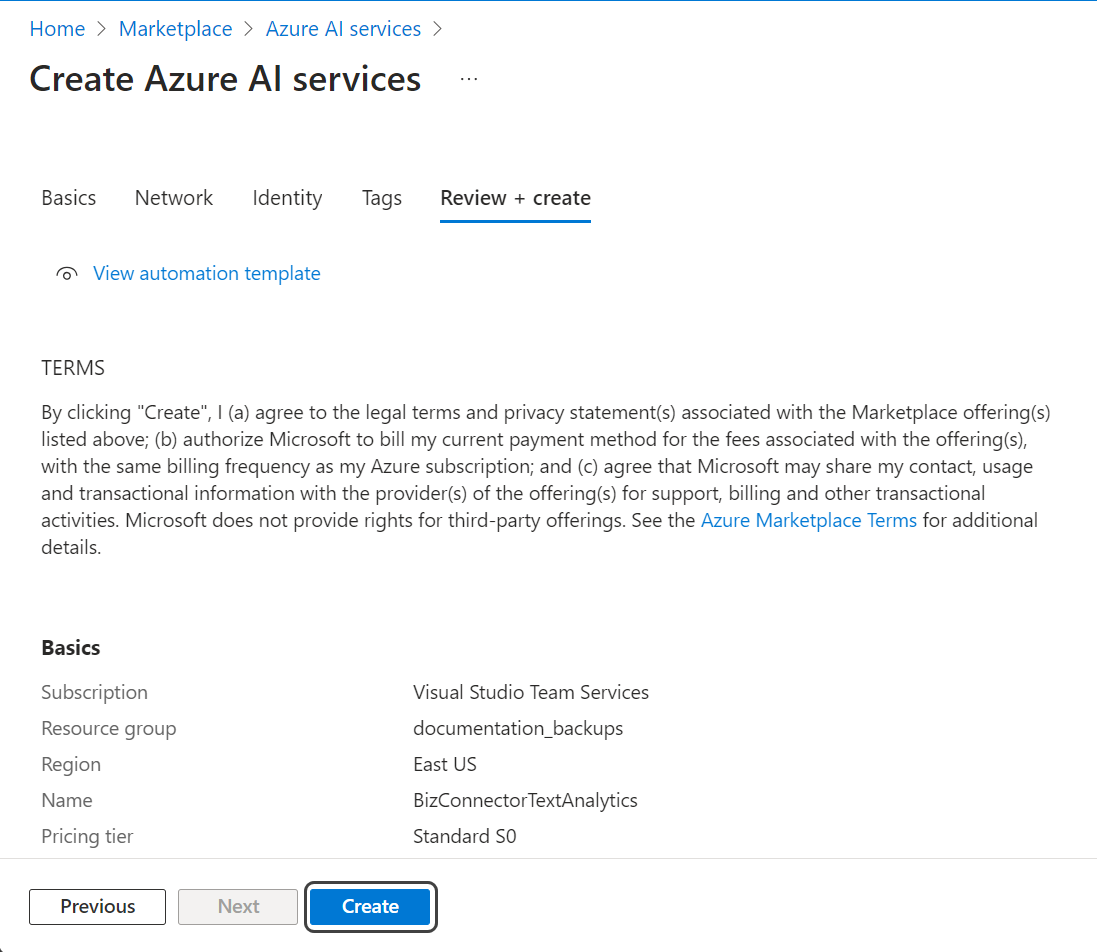
6.You will be automatically taken to the deployment details page. Under the Next steps title, click the Go to resource button.
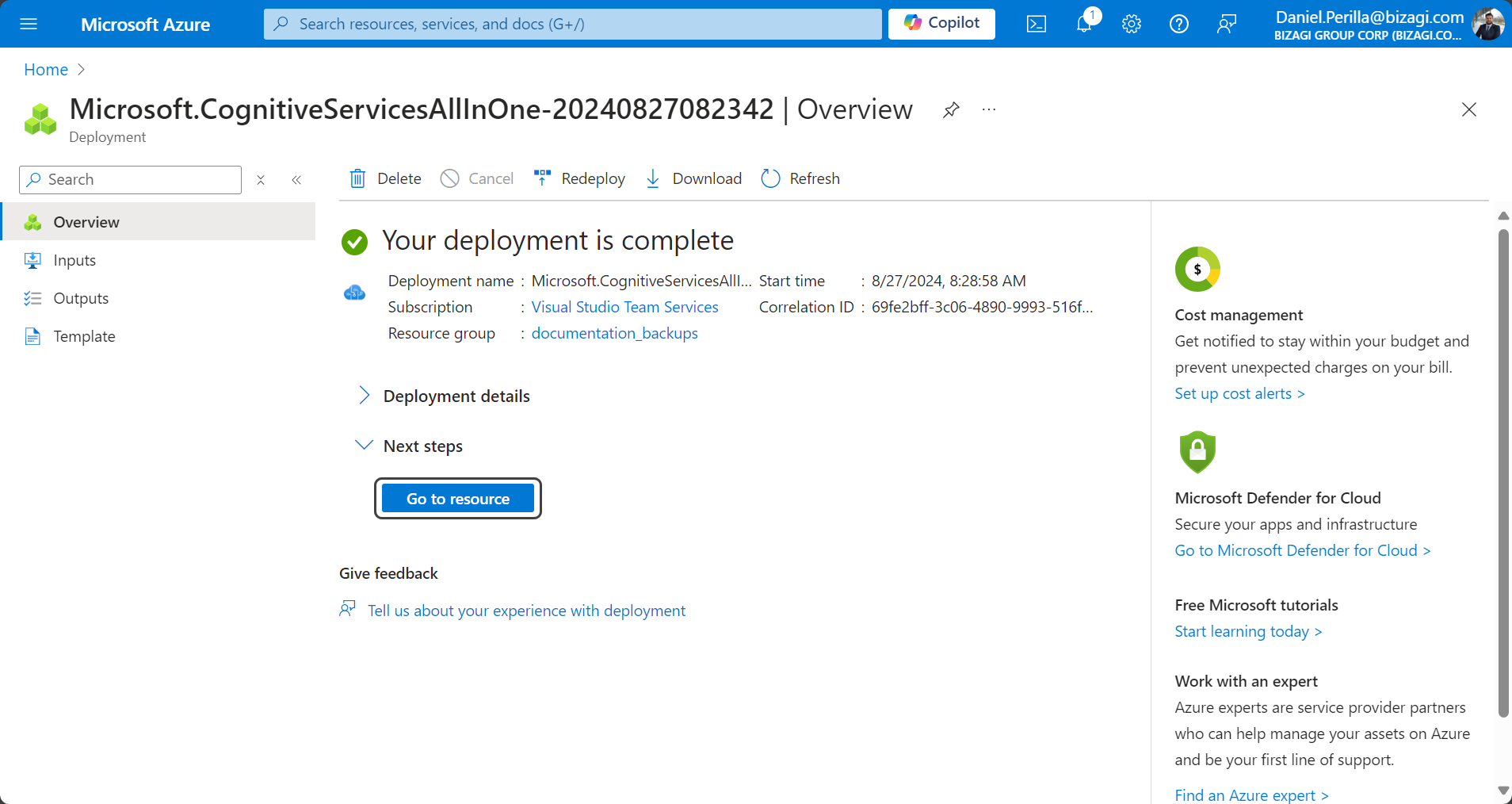
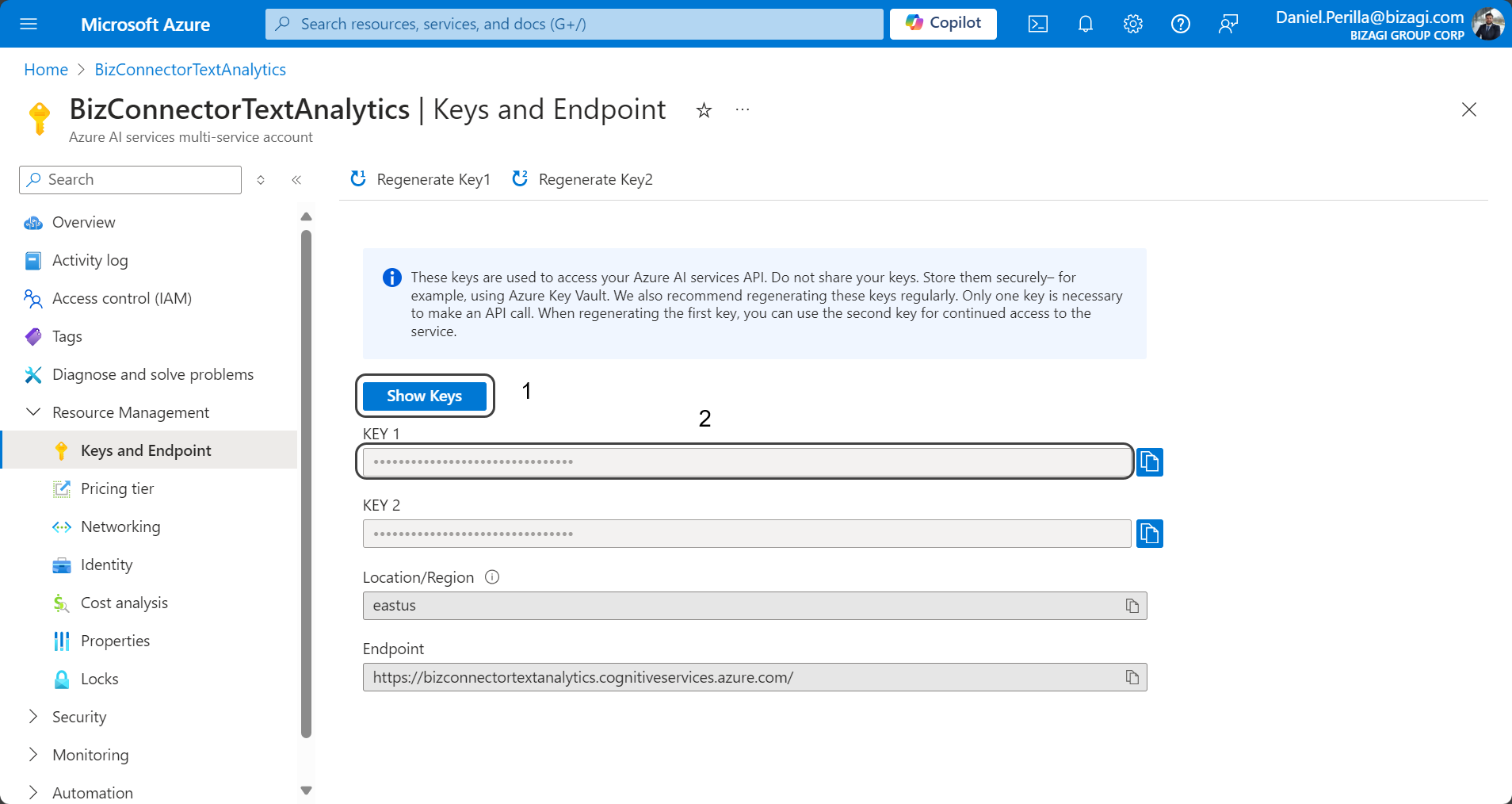
7.Under the Manage keys subtitle click the underlined phrase Click here to manage keys.
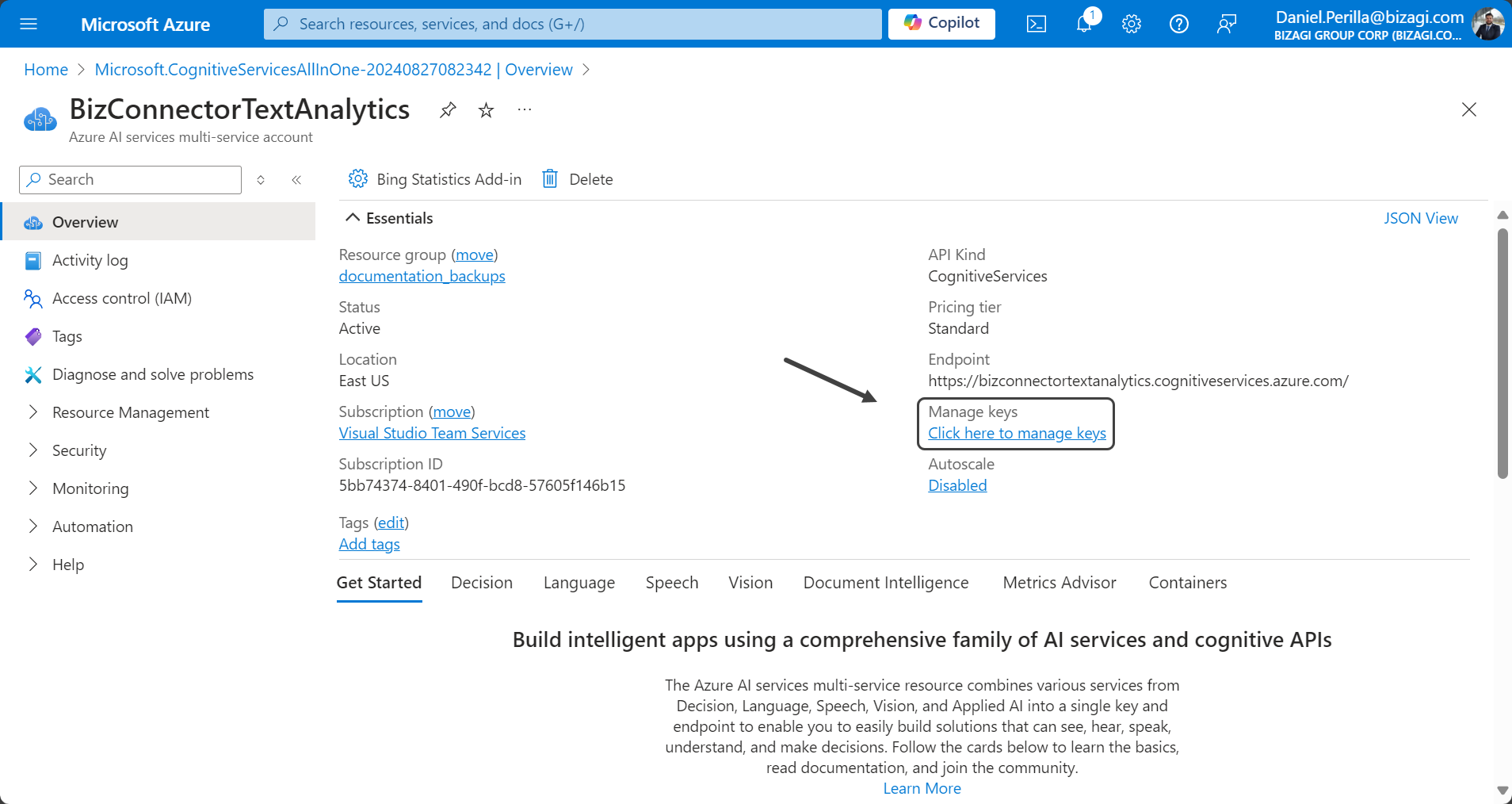
8.In the Keys and Endpoint section, retrieve the value from the KEY 1 field, which you will need to use in the SUBSCRIPTION_KEY property in the connector's authentication configuration.
Configuring the connector
To configure the connector (in particular its authentication parameters), follow the steps presented in the Configuration chapter in the Connectors Setup documentation.
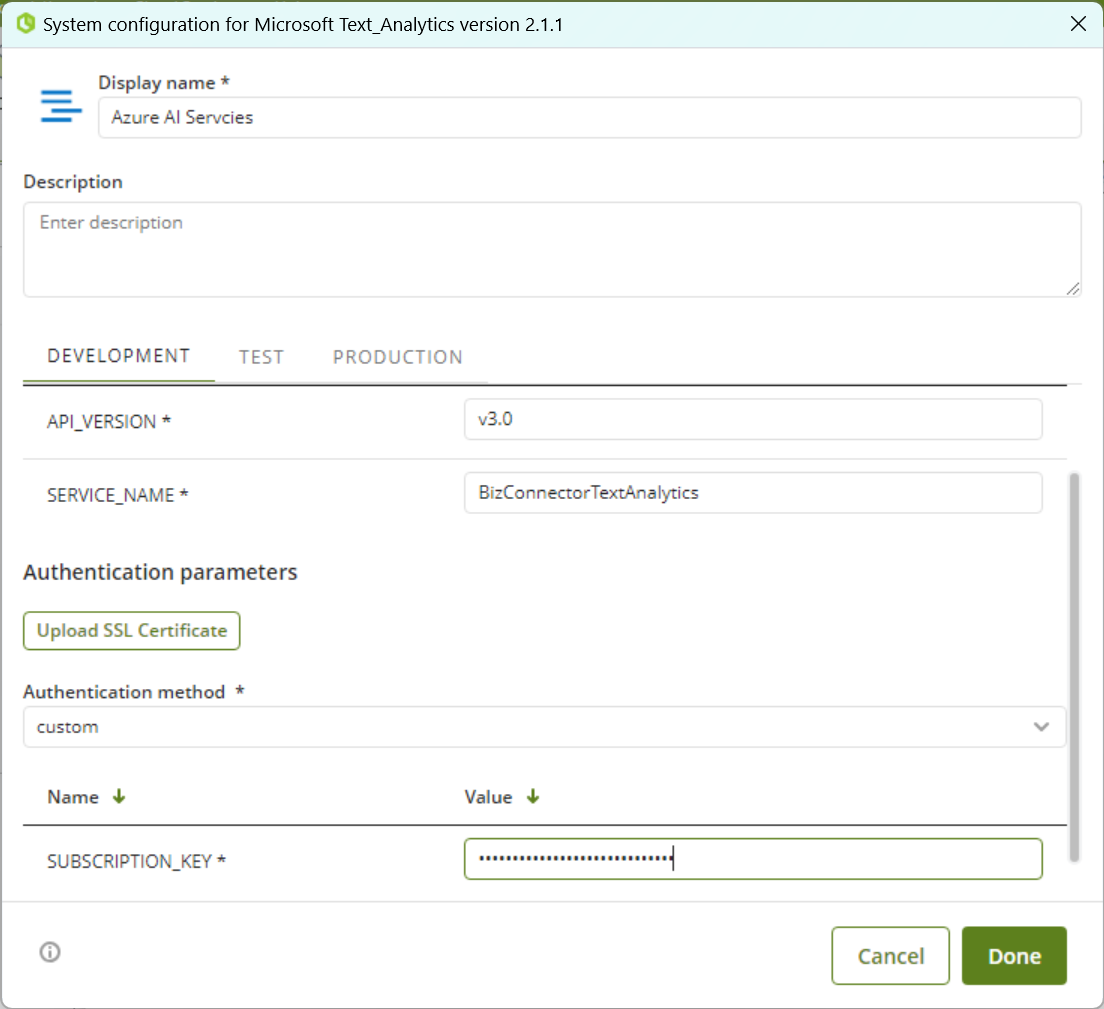
For this configuration, consider the following authentication parameters:
•SERVICE_NAME: The service name configured in of the Configuring Azure AI Services instructions.
•API_Version: v3.0
•Authentication method: Custom
•Subscription_key: The Cognitive Services key (KEY 1 copied in the step of the Configuring Azure AI Services instructions )
The configuration of the Connector should look like this:
Using the connector
This connector features a set of methods which let you use Azure Text Analytics's API services to take advantage of its capabilities.
To learn overall how/where to configure the use of a connector, refer to the Using Connectors documentation.
When using the connector, keep in mind they may need input or output configurations. The following images show examples of how to map the inputs or outputs of a method.
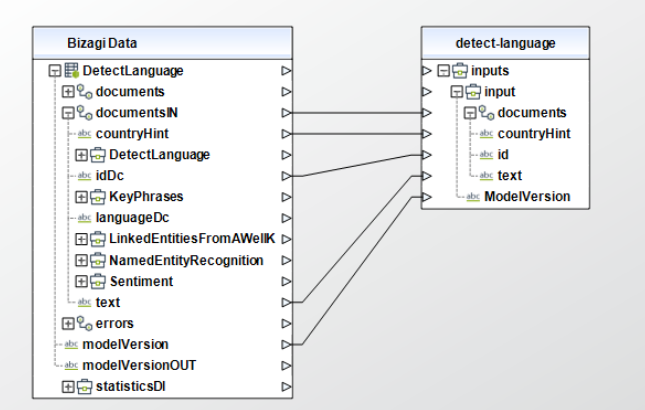
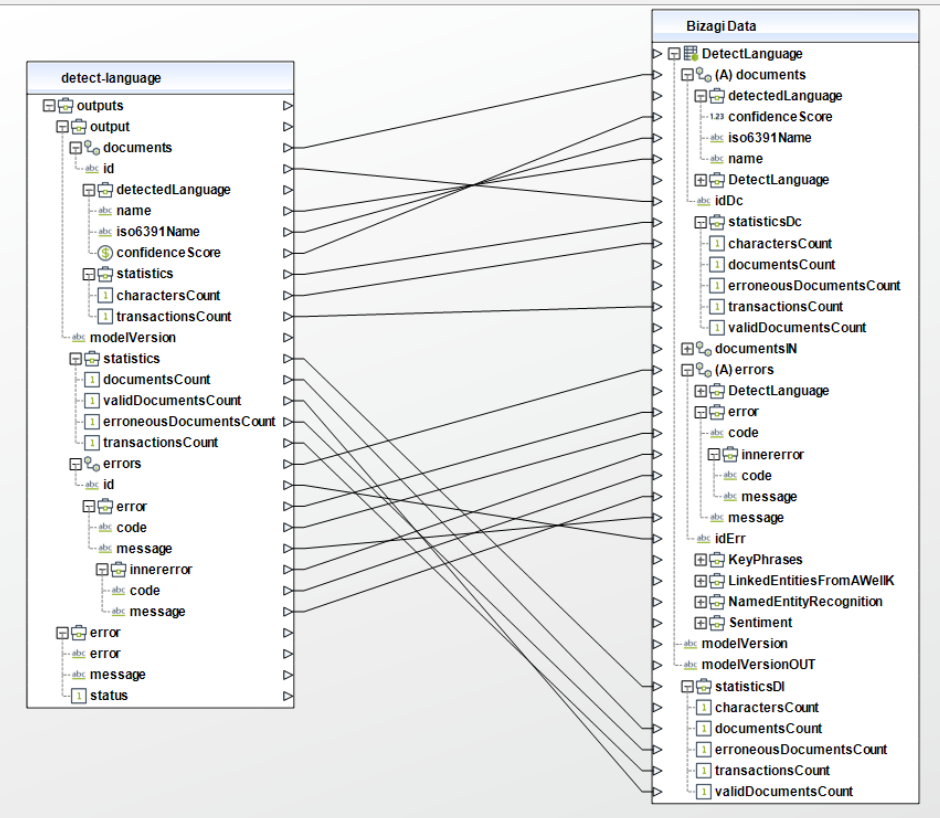
Available Actions
Detect Language
Detects a text's language.
To configure its inputs, take into account the following descriptions:
•documents (Required): Collection that has the following parameters:
oid (Required): The text identifyier. This parameter should be a String in your Bizagi model.
otext (Required): The text to analyze. This parameter should be a String in your Bizagi model.
•modelVersion: The model version you want to use, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
The outputs of this connector are the following:
•statistics (Object): represents an object with the following attributes:
odocumentsCount (Integer): the number of processed documents.
ovalidDocumentsCount (Integer): the number of valid processed documents.
oerroneousDocumentsCount (Integer): the number of documents with errors.
otransactionsCount (Integer): the number of successful transactions.
•documents (Object Collection): the list of analyzed documents.
oid (String): the input document identifier.
odetectedLanguages (Object): contains the following parameters.
▪name (String): language name.
▪iso6391Name (String): the short language name.
▪confidenceScore (Float): certainty of the detection, values closer to 1 have more certainty that the detected language is correct.
ostatistics (Object): document statistics
▪charactersCount (Integer): the number of characters in the document.
▪transactionsCount (Integer): the number of successful transactions in the document.
•error (Object Collection): lists the details if a document had errors during analysis.
•modelVersion (String): the model version used, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
For more information about this method's use, refer to Azure AI Services' official documentation at Microsoft's official documentation.
Named Entity Recognition
Detects entities such as Person, Organization or Location in the text. For more information about entity categories check the Microsoft documentation relating to Named Entity Recognition.
To configure its inputs, take into account the following descriptions:
•documents (Required): Collection that has the following parameters:
oid (Required): The text identifier. This parameter should be a String in your Bizagi model.
otext (Required): The text to analyze. This parameter should be a String in your Bizagi model.
olanguage: The text's language, common values are: de, en, es, fr, it, ja, ko, nl. For more information check Microsoft's documentation on language detection. This parameter should be a String in your Bizagi model.
•modelVersion:The model version you want to use, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
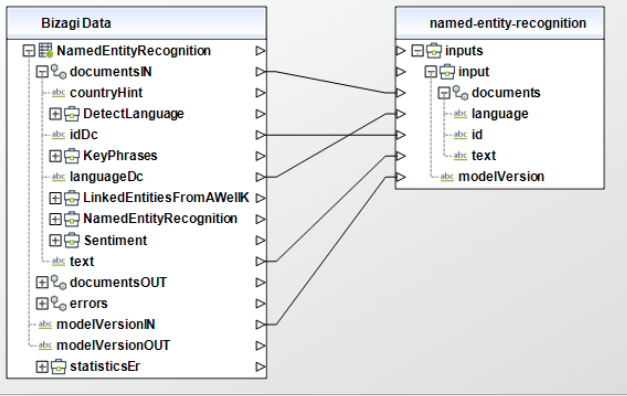
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
The outputs of this connector are the following:
•statistics (Object): represents an object with the following attributes:
odocumentsCount (Integer): the number of processed documents.
ovalidDocumentsCount (Integer): the number of valid processed documents.
oerroneousDocumentsCount (Integer): the number of documents with errors.
otransactionsCount (Integer): the number of successful transactions.
•documents (Object Collection): the list of analyzed documents.
oid (String): the input document identifier.
oentities (Object Collection): the list of found entities
▪text (String): the identified text in the document that belongs to an entity.
▪type (String): entity type.
▪subtype (String): describes what other entity the text can belong to.
▪offset (Integer): location of the identified text in the document. For more information about offset check the Multilingual and emoji support in Language service features documentation.
▪length (Integer): the length of the found word.
▪confidenceScore (Float): certainty of the detection, values closer to 1 have more certainty.
ostatistics (Object): document statistics
▪charactersCount (Integer): the number of characters in the document.
▪transactionsCount (Integer): the number of successful transactions in the document.
•error (Object Collection): lists the details if a document had errors during analysis.
•modelVersion (String): the model version used, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
Linked Entities from a well-known knowledge base
Returns a list of the detected entities along with links to a knowledge base such as Wikipedia.
To configure its inputs, take into account the following descriptions:
•documents (Required): Collection that has the following parameters:
oid (Required): The text identifier. This parameter should be a String in your Bizagi model.
otext (Required): The text to analyze. This parameter should be a String in your Bizagi model.
olanguage: The text's language, common values are: de, en, es, fr, it, ja, ko, nl. For more information check Microsoft's documentation on language detection. This parameter should be a String in your Bizagi model.
•modelVersion:The model version you want to use, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
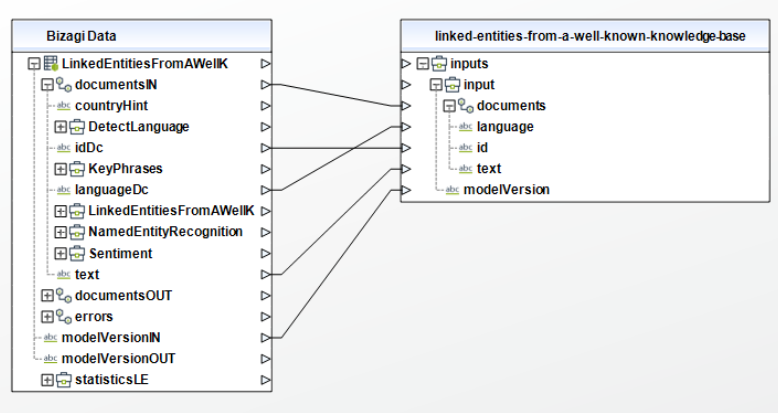
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
The outputs of this connector are the following:
•statistics (Object): represents an object with the following attributes:
odocumentsCount (Integer): the number of processed documents.
ovalidDocumentsCount (Integer): the number of valid processed documents.
oerroneousDocumentsCount (Integer): the number of documents with errors.
otransactionsCount (Integer): the number of successful transactions.
•documents (Object Collection): the list of analyzed documents.
oid (String): the input document identifier.
oentities (Object Collection): the list of found entities.
▪name (String): the identified text in the document that belongs to an entity.
▪matches (Object Collection): List of matches related to the name property.
•text (String): the identified text in the document that belongs to an entity.
•offset (Integer): location of the identified text in the document. For more information about offset check the Multilingual and emoji support in Language service features documentation.
•length (Integer): the length of the found word.
•confidenceScore (Float): certainty of the detection, values closer to 1 have more certainty.
▪language (String): the short language form for the identified name.
▪id (String): usually is the same value as the property name.
▪url (String): URL to the knowledge base that has information about the property name.
▪dataSource (String): Name of the linked knowledge base.
▪type (String): entity type.
▪subtype (String): describes what other entity the text can belong to.
ostatistics (Object): document statistics
▪charactersCount (Integer): the number of characters in the document.
▪transactionsCount (Integer): the number of successful transactions in the document.
•error (Object Collection): lists the details if a document had errors during analysis.
•modelVersion (String): the model version used, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
Key Phrases
Detects a list of strings with the key talking points of the input text.
To configure its inputs, take into account the following descriptions:
•documents (Required): Collection that has the following parameters:
oid (Required): The text identifier. This parameter should be a String in your Bizagi model.
otext (Required): The text to analyze. This parameter should be a String in your Bizagi model.
olanguage: The text's language, common values are: de, en, es, fr, it, ja, ko, nl. For more information check Microsoft's documentation on language detection. This parameter should be a String in your Bizagi model.
•modelVersion:The model version you want to use, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
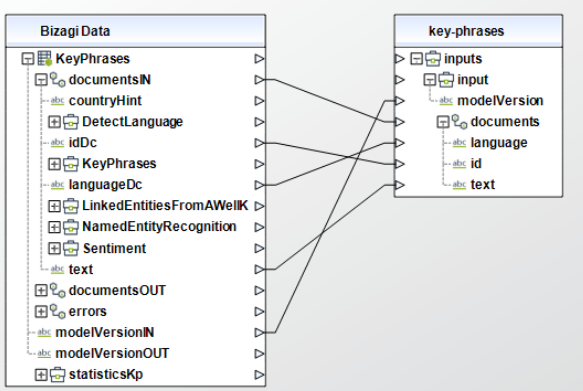
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
The outputs of this connector are the following:
•statistics (Object): represents an object with the following attributes:
odocumentsCount (Integer): the number of processed documents.
ovalidDocumentsCount (Integer): the number of valid processed documents.
oerroneousDocumentsCount (Integer): the number of documents with errors.
otransactionsCount (Integer): the number of successful transactions.
•documents (Object Collection): the list of analyzed documents.
oid (String): the input document identifier.
okeyPhrases (String collection): a list of the detected key phrases in the text.
ostatistics (Object): document statistics
▪charactersCount (Integer): the number of characters in the document.
▪transactionsCount (Integer): the number of successful transactions in the document.
•error (Object Collection): lists the details if a document had errors during analysis.
•modelVersion (String): the model version used, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
Sentiment
Detects a sentiment prediction, along with sentiment scores for the sentiment classes (Positive, Negative, and Neutral), for the text.
To configure its inputs, take into account the following descriptions:
•documents (Required): Collection that has the following parameters:
oid (Required): The text identifier. This parameter should be a String in your Bizagi model.
otext (Required): The text to analyze. This parameter should be a String in your Bizagi model.
olanguage: The text's language, common values are: de, en, es, fr, it, ja, ko, nl. For more information check Microsoft's documentation on language detection. This parameter should be a String in your Bizagi model.
•modelVersion:The model version you want to use, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
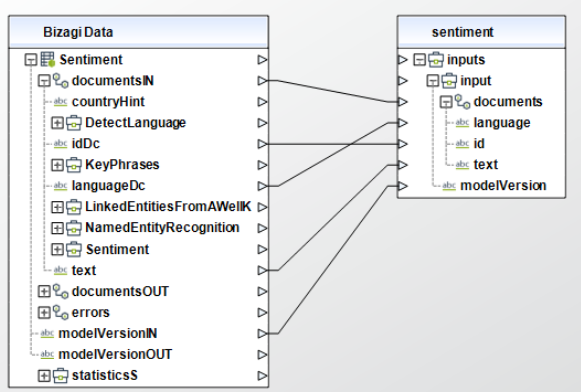
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
The outputs of this connector are the following:
•statistics (Object): represents an object with the following attributes:
odocumentsCount (Integer): the number of processed documents.
ovalidDocumentsCount (Integer): the number of valid processed documents.
oerroneousDocumentsCount (Integer): the number of documents with errors.
otransactionsCount (Integer): the number of successful transactions.
•documents (Object Collection): the list of analyzed documents.
oid (String): the input document identifier.
osentiment (String): the sentiment found in the analyzed document, values are: positive, negative, and neutral.
oconfidenceScores (Object): scores each of the sentiments for the document.
▪positive (Float): certainty of the detection, values closer to 1 have more certainty.
▪neutral (Float): certainty of the detection, values closer to 1 have more certainty.
▪negative (Float): certainty of the detection, values closer to 1 have more certainty.
osentences (Object Collection): Lists
▪sentiment (String): the sentiment found in the analyzed sentence, values are: positive, negative and neutral.
▪confidenceScores (Object): scores each of the sentiments for the sentence.
•positive (Float): certainty of the detection, values closer to 1 have more certainty.
•neutral (Float): certainty of the detection, values closer to 1 have more certainty.
• negative (Float): certainty of the detection, values closer to 1 have more certainty.
▪offset (Integer): location of the identified text in the document. For more information about offset check the Multilingual and emoji support in Language service features documentation.
▪length (Integer): the length of the sentence.
▪text (String): identified text
ostatistics (Object): document statistics
▪charactersCount (Integer): the number of characters in the document.
▪transactionsCount (Integer): the number of successful transactions in the document.
•error (Object Collection): lists the details if a document had errors during analysis.
•modelVersion (String): the model version used, either latest, 2021-10-01, 2022-06-01, 2022-10-01 or 2022-11-01. This parameter should be a String in your Bizagi model.
Last Updated 9/4/2024 1:52:25 PM