Overview
The Amazon Rekognition connector for Bizagi is available for download at Bizagi Connectors Xchange.
Through this connector, you will be able to connect your Bizagi processes to a aws.amazon.com/rekognition account in order to use Amazon Rekognition's services API.
For more information about this connector's capabilities, visit Bizagi Connectors Xchange.
Before you start
In order to test and use this connector, you will need:
1.Bizagi Studio previously installed.
2.This connector previously installed, via the Connectors Xchange as described at https://help.bizagi.com/platform/en/index.html?Connectors_Xchange.htm, or through a manual installation as described at https://help.bizagi.com/platform/en/index.html?connectors_setup.htm
3.Follow the steps described below using your Amazon Web Services (AWS) account:
•Go to https://aws.amazon.com/free/ and log in using your account.
•On the left panel click the Users option and then click on Add user.
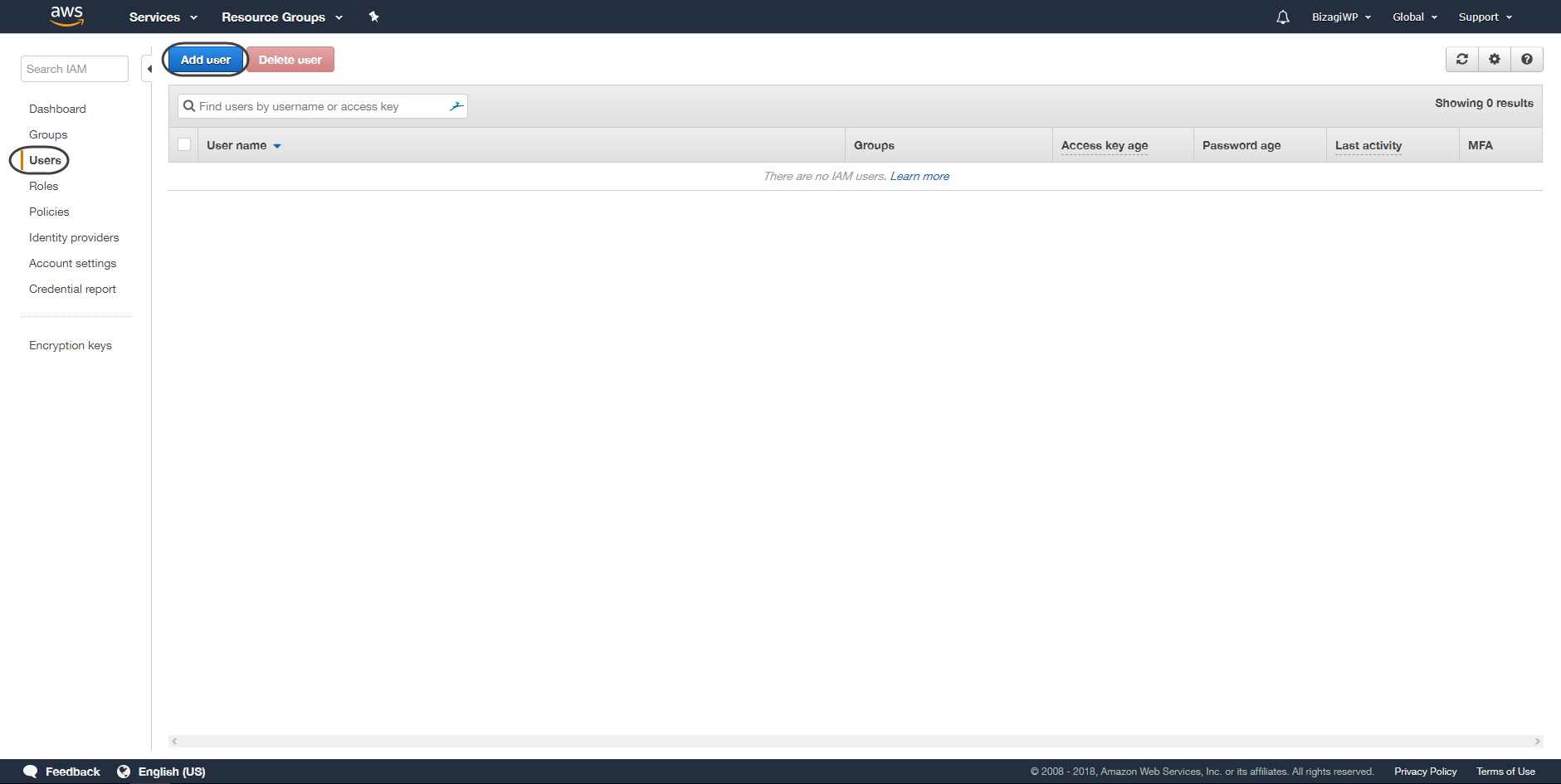
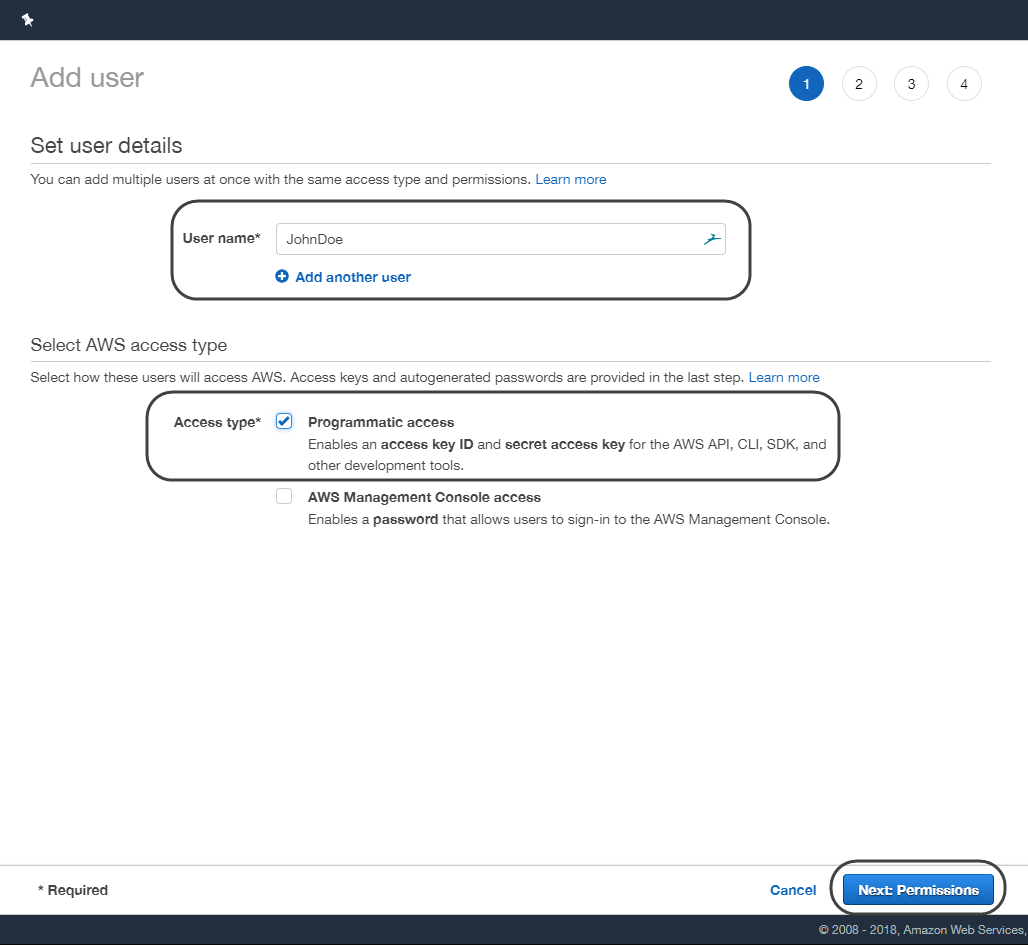
•Give a name to the user and make sure to tick the Programmatic access option, then click next.
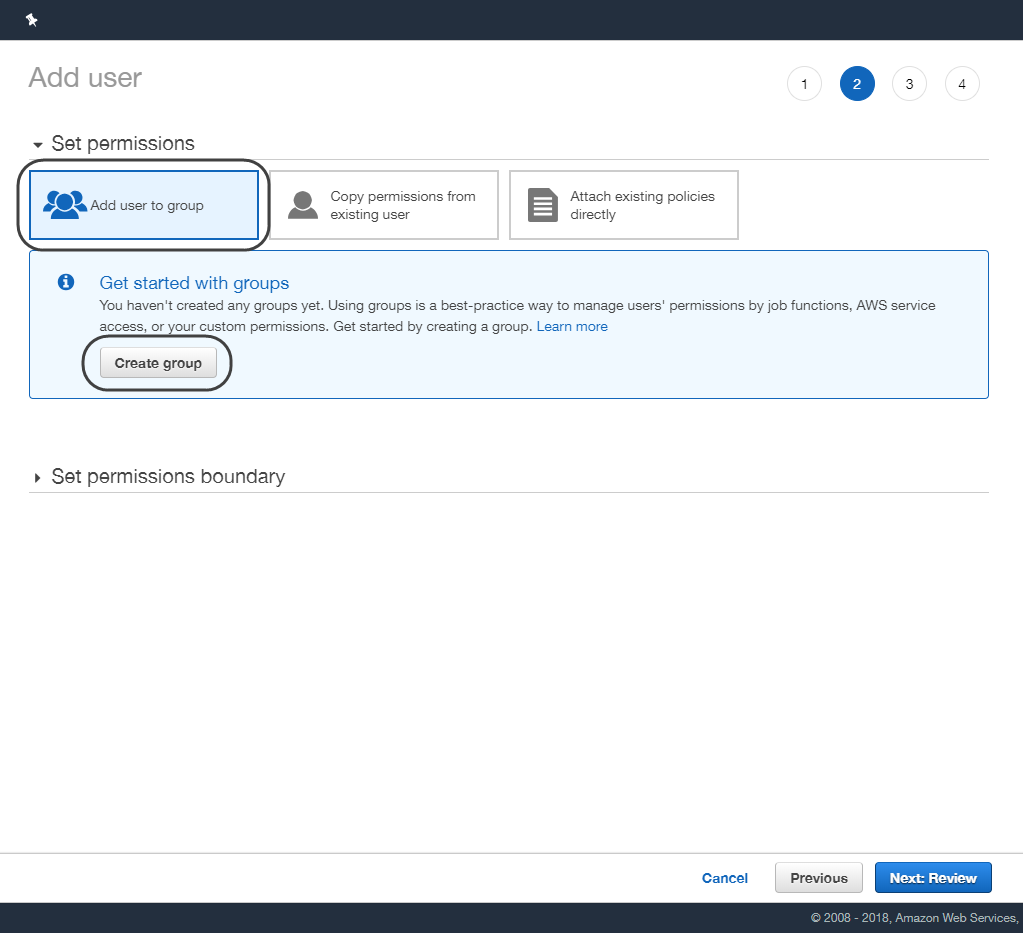
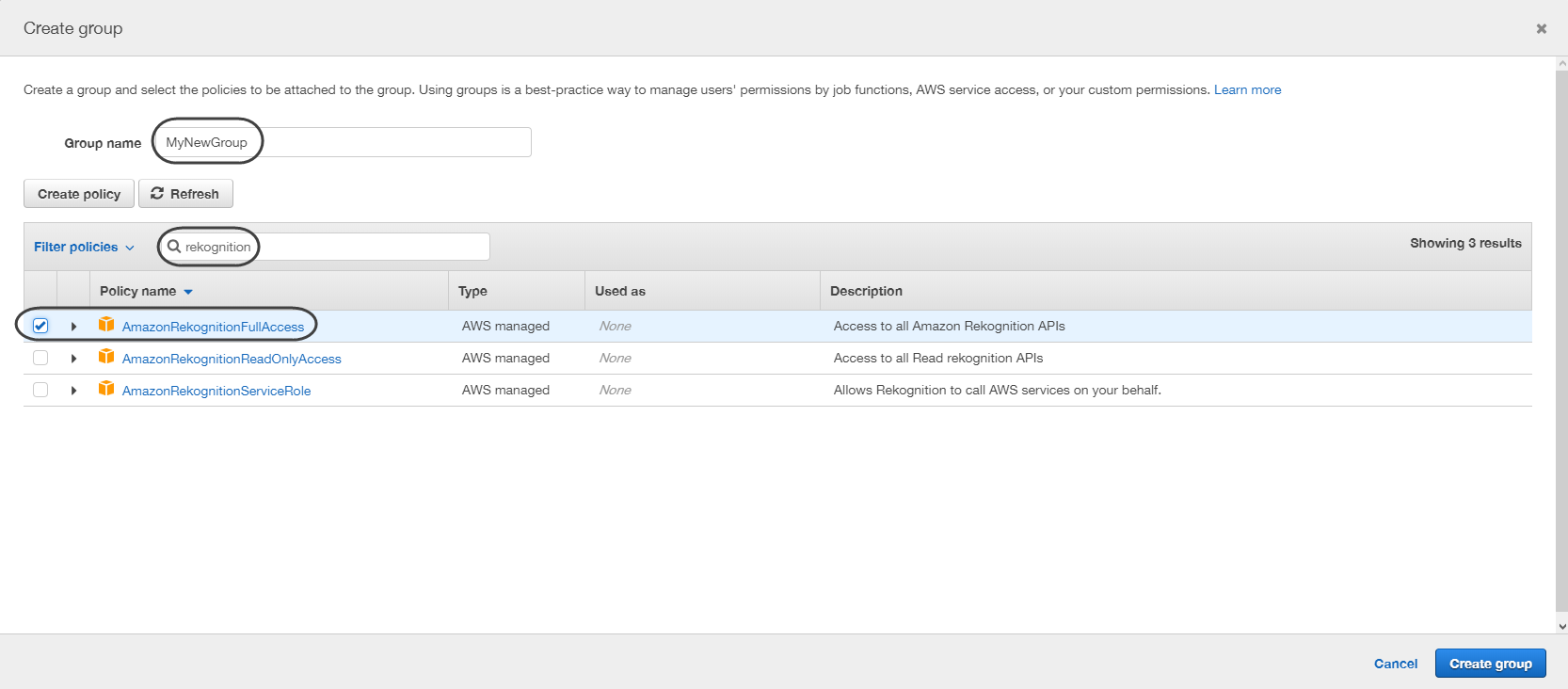
•Select the create group option, type a name for your new group and filter the rekognition options making sure to tick the AmazonRekognitionFullAccess item.
•At this point you are presented with a summary. Review all the information you just entered, click the Create user button once you are sure that no changes are needed.
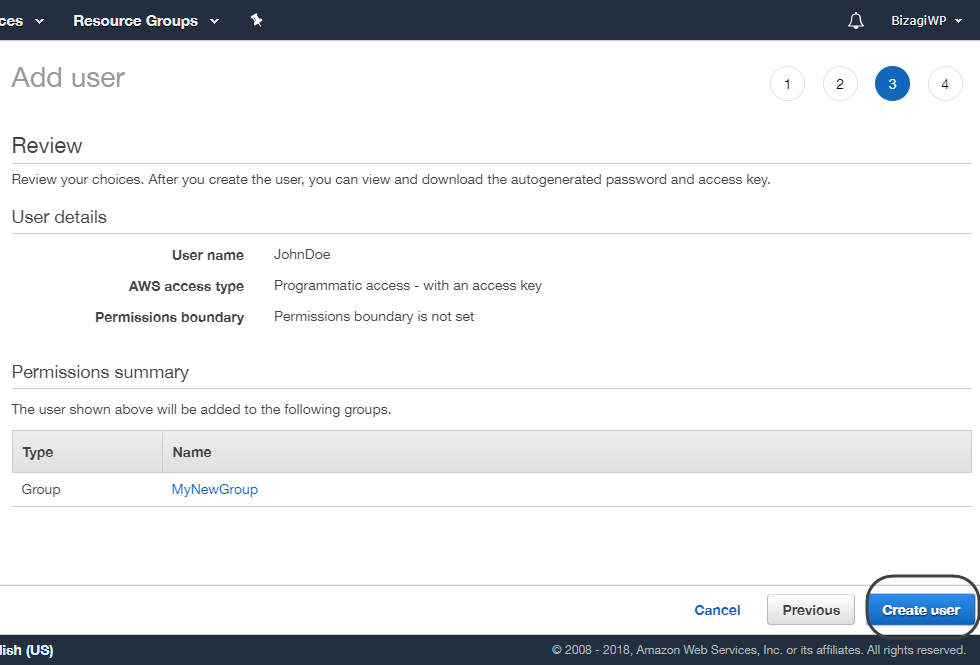
•The details of the created user are shown, including the Access key ID and the Secret Access Key. Make sure to keep that information safely for it will not be shown again, to do so you may take a screen shot of that information, write it down or use the Download .csv feature to obtain a file containing that information.
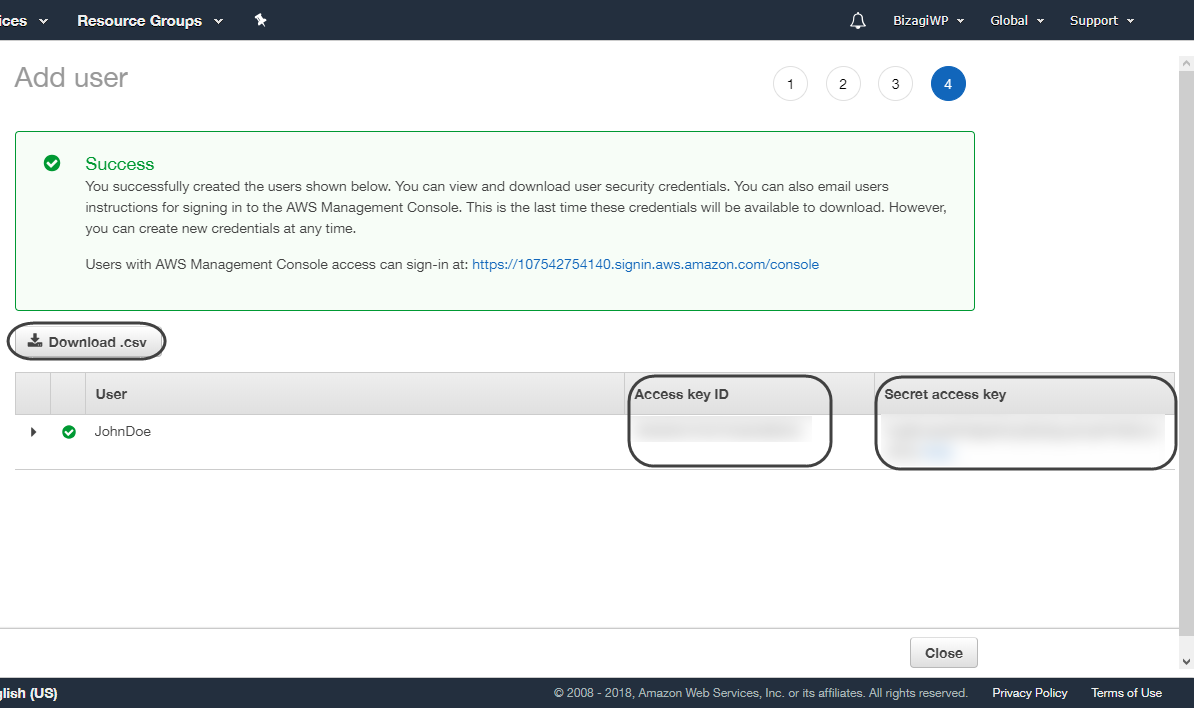
•You can now access AWS' console by accessing this link https://us-east-2.console.aws.amazon.com/console/home?region=us-east-2. There, you can review the result of the actions performed with the service.
Configuring the connector
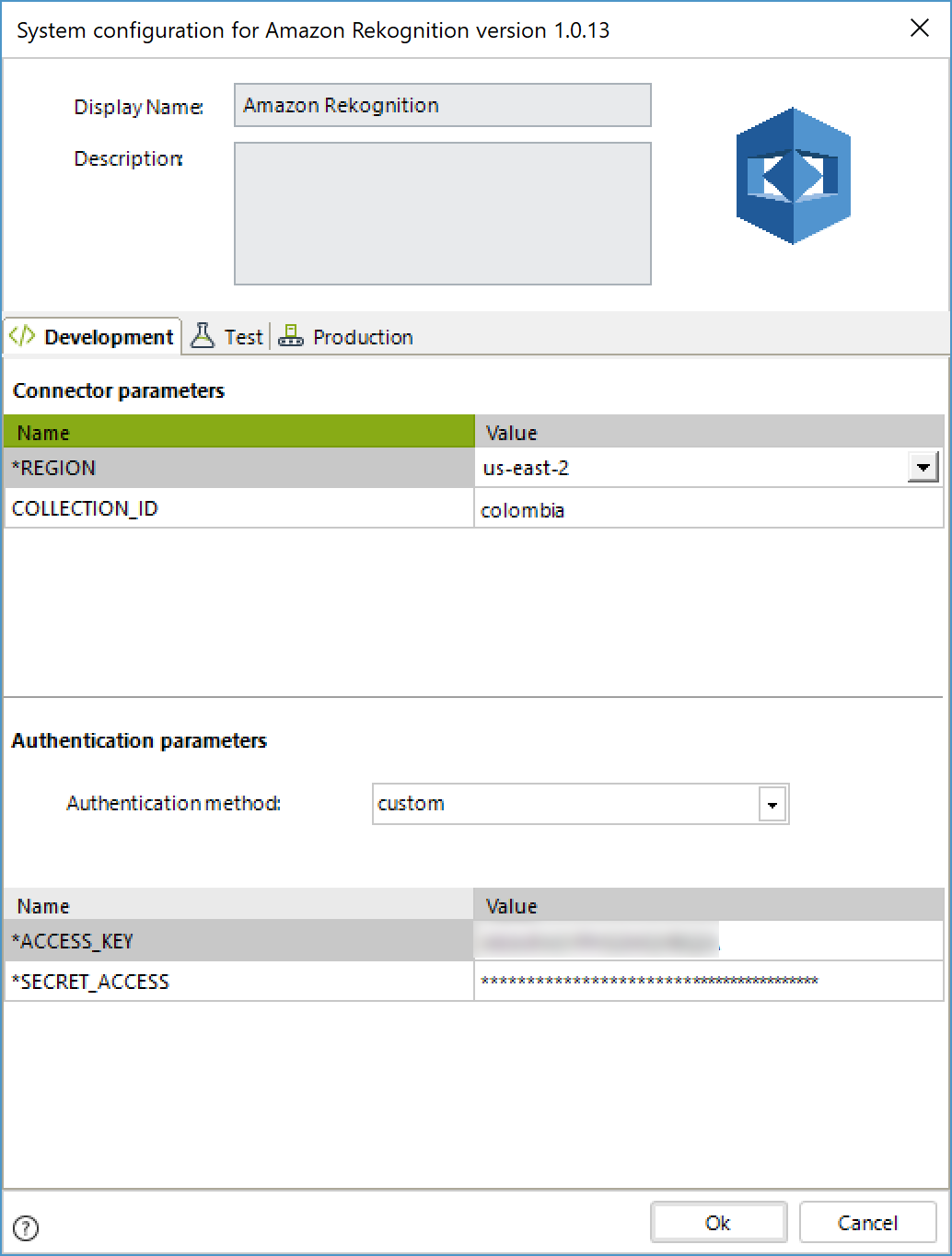
In order to configure the connector (i.e its authentication parameters), follow the steps presented at the Configuration chapter in https://help.bizagi.com/platform/en/index.html?connectors_setup.htm
For this configuration, consider the following authentication parameters:
•Authentication method: custom.
•ACCESS_KEY: String of characters provided when the user was created.
•SECRET_ACCESS: String of characters provided when the user was created.
•REGION: Region where the Amazon Rekognition service is hosted (it is usually us-east-2). It can be checked in the URL of the AWS console.
•COLLECTION_ID: Default collection to perform the connector's operations.
Using the connector
This connector features 13 available methods of Amazon's Rekognition services.
To learn overall how/where to configure the use of a connector, refer to https://help.bizagi.com/platform/en/index.html?Connectors_Studio.htm.
When using the connector, keep in mind they may need input or output configurations. The following images show examples of how to map the inputs or outputs of a method.
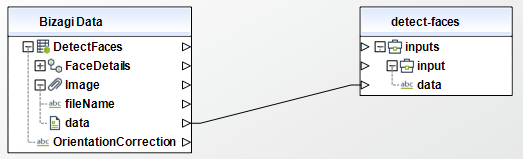
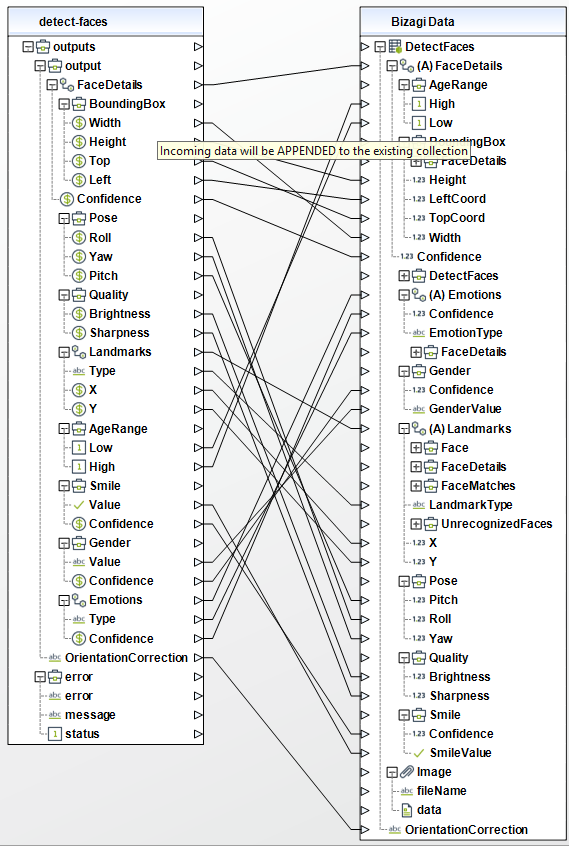
Available actions
Detect faces
Detects faces within an image that is provided as input.
To configure its inputs, take into account the following descriptions:
•Data (String - Required): input image encoded in base64 format.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•FaceDetails (array de Objects): collection of detected faces. If no face is detected, the array is empty.
oBoundingBox (Object): box that surrounds the detected face.
▪Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
▪Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
▪Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Confidence (float): confidence level that what the BoundingBox contains is a face.
oPose (Object): indicates the pose of the face
▪Roll (float): Value representing the face rotation on the roll axis.
▪Yaw (float): Value representing the face rotation on the yaw axis.
▪Pitch (float): Value representing the face rotation on the pitch axis.
oQuality (Object):
▪Brightness (float): face's brightness in a value between 0 and 100. A higher value indicates a brighter face.
▪Sharpness (float): face's sharpness in a value between 0 and 100. A higher value indicates a sharper face..
oLandmarks (array de Objects): location of the landmarks on the face
▪Type (string): landmark type. For example: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. These are the different parts found on a face.
▪X (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's x coordinate is positioned at 350px, this field would have as value 0.5.
▪Y (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's y coordinate is positioned at 350px, this field would have as value 0.5.
oAgeRange (Object): estimated age range, in years, for the face.
▪Low (integer): lowest estimated age
▪High (integer): highest estimated age
oSmile (Object): indicates whether or not the face is smiling.
▪Value (boolean): true if the face is smilent, false if it is not.
▪Confidence (float): confidence level in the smile's determination.
oGender (Object): predicted gender of the face.
▪Value (string): face's gender. Possible values include "Male", "Female".
▪Confidence (float): confidence level in the gender's determination.
oEmotions (array de Objects): emotions that appear on the face.
▪Type (string): type of emotion detected. Possible values include "HAPPY", "SAD", "ANGRY", "CONFUSED", "DISGUSTED", "SURPRISED", "CALM", "UNKNOWN".
▪Confidence (float): confidence level in the emotion's determination.
•OrientationCorrection (string): image's orientation. Possible values include "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". If the image metadata contains an orientation, Rekognition does not perform a correction for the orientation and the value of this attribute would be NULL.
Detect text
Detects text in the input image and converts it into machine-readable text.
To configure its inputs, take into account the following descriptions:
•Data (String - Required): input image encoded in base64 format.
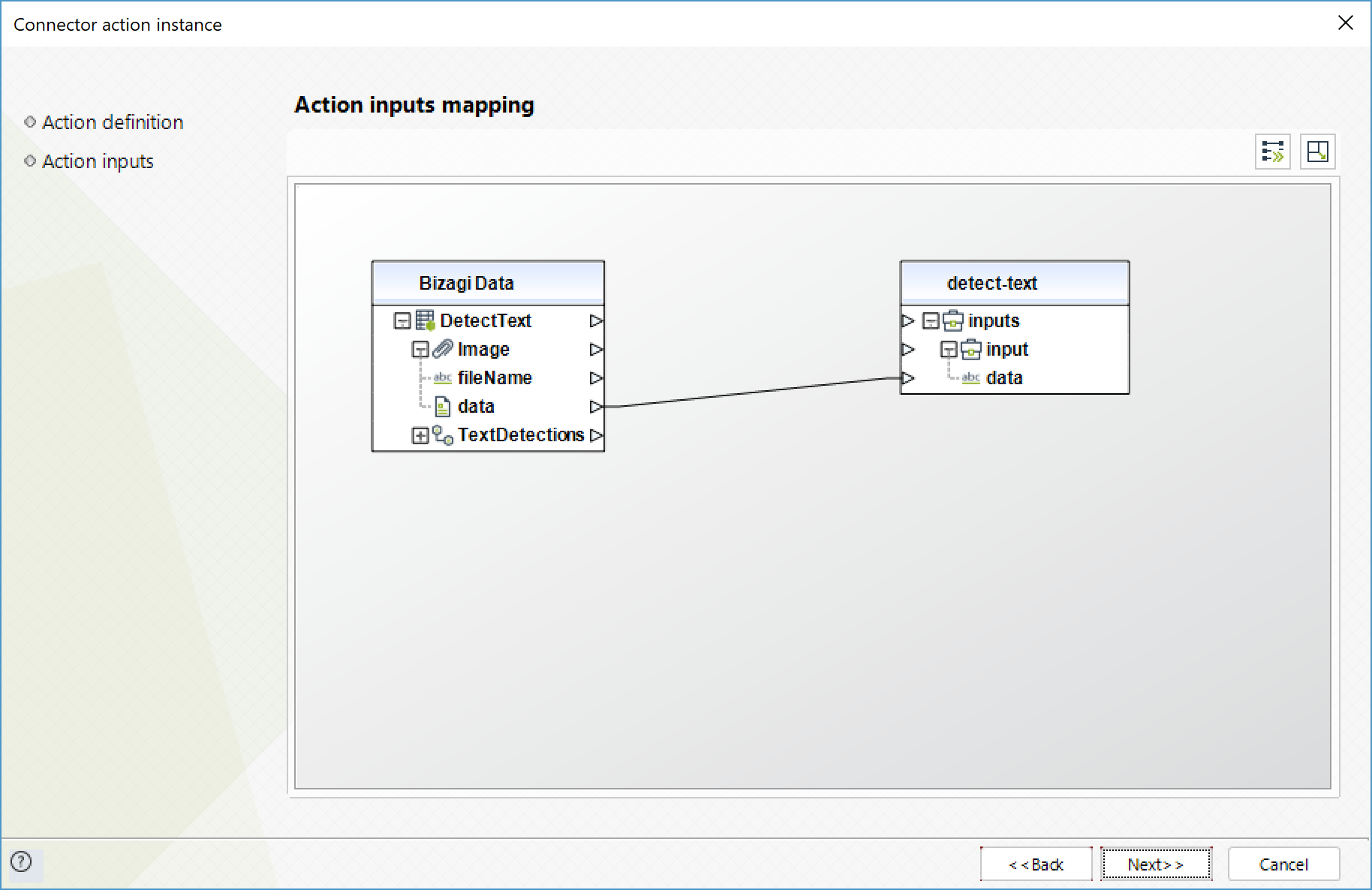
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•TextDetections (Colección): array of the texts found in the image.
oDetectedText (Texto): detected text.
oType (Texto): type of the text detected. Possible values include "LINE", "WORD".
oConfidence (Flotante): confidence level over the identified text.
oID (Entero): id of the detected text.
oParentId (Entero): parent identifier for the detected text, identified by the value of the ID.
oGeometry (Objeto): location of the text on the image.
▪BoundingBox (Object): box that surrounds the detected text.
•Width (float): box's width that surrounds the text, as a proportion of the total width of the image.
•Height (float): box's height that surrounds the text, as a proportion of the total height of the image.
•Left (float): left coordinate of the box that surrounds the text, as a proportion of the total width of the image.
•Top (float): top coordinate of the box that surrounds the text, as a proportion of the total width of the image
▪Polygon (Colección): polygon that surrounds the detected text within the bounding box.
•X (Flotante): x coordinate of a point of the polygon.
•Y (Flotante): y coordinate of a point of the polygon.
Detect labels
Detects instances of real-world entities within an image (JPEG or PNG) provided as input. Recognizes objects, events and concepts.
To configure its inputs, take into account the following descriptions:
•Data (String - Required): input image encoded in base64 format. This parameter is required for the service invocation to be successful.
•MaxLabels (Integer): Maximum number of labels to be returned.
•MinConfidence (Float): Minumum confidence level for a label to be returned. Its default value is 50%.
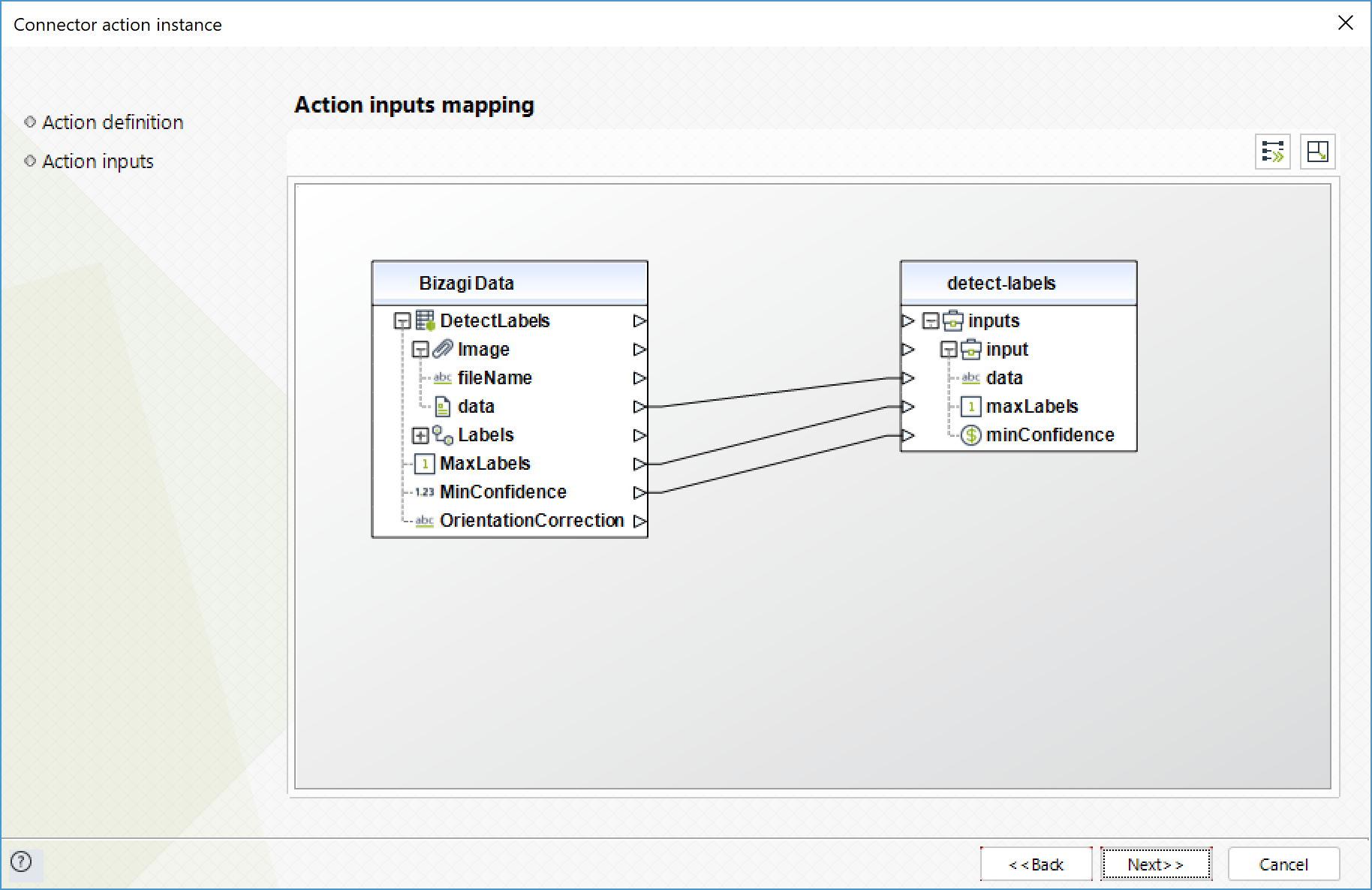
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•Labels (Colección): collection of the labels found.
oName (Texto): name (label) of the detected object.
oConfidence (Flotante): confidence level
•OrientationCorrection (Texto): image orientation. Possible values include "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". If the image metadata contains the orientation, Amazon Rekognition does not correct the orientation, and the value for this field is NULL.
Recognize celebrities
Returns an array of celebrities recognized in the input image.
To configure its inputs, take into account the following descriptions:
•Data (String - Required): input image encoded in base64 format. This parameter is required for the service invocation to be successful.
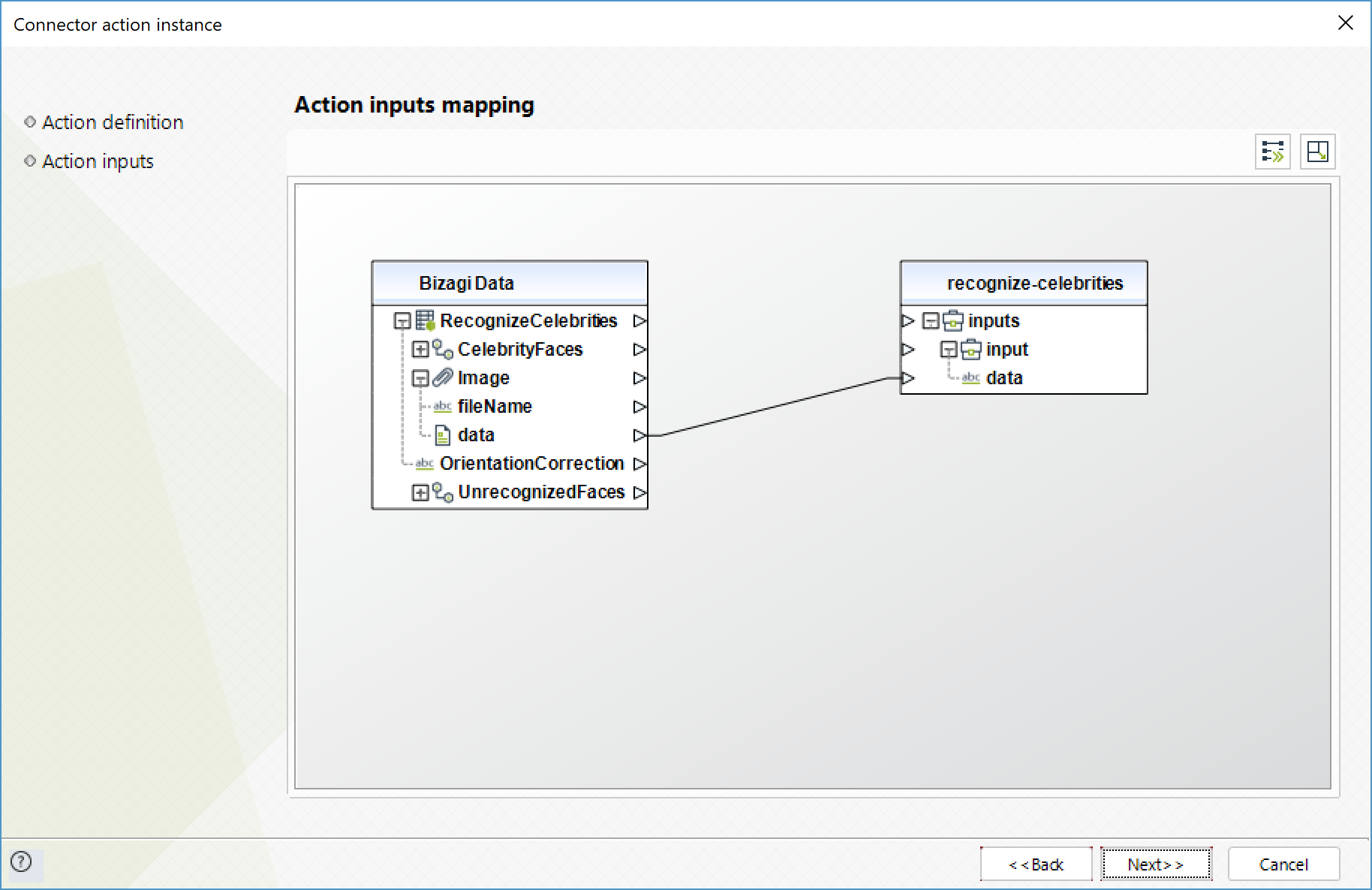
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•CelebrityFaces (Colección): collection of the celebrities identified. The action identifies maximum 15 celebrities.
oUrls (Colección): array of URLs with additional information about the celebrity. If there is no additional information about the celebrity, the list is empty.
oName (Texto): Celebrity's name.
oId (Texto): unique identifier for the celebrity.
oFace (Objeto): Celebrity's face.
▪BoundingBox (Object): box that surrounds the detected face.
•Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
•Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
•Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Confidence (float): confidence level that what the BoundingBox contains is a face.
▪Pose (Object): indicates the pose of the face
•Roll (float): Value representing the face rotation on the roll axis.
•Yaw (float): Value representing the face rotation on the yaw axis.
•Pitch (float): Value representing the face rotation on the pitch axis.
▪Quality (Object):
•Brightness (float): face's brightness in a value between 0 and 100. A higher value indicates a brighter face.
•Sharpness (float): face's sharpness in a value between 0 and 100. A higher value indicates a sharper face..
▪Landmarks (array de Objects): location of the landmarks on the face
•Type (string): landmark type. For example: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. These are the different parts found on a face.
•X (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's x coordinate is positioned at 350px, this field would have as value 0.5.
•Y (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's y coordinate is positioned at 350px, this field would have as value 0.5.
▪MatchConfidence (Flotante): confidence level over the celebrity identification.
•UnrecognizedFaces (Colección): collection of the faces that were not identified as celebrities.
oBoundingBox (Object): box that surrounds the detected face.
▪Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
▪Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
▪Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Confidence (float): confidence level that what the BoundingBox contains is a face.
oPose (Object): indicates the pose of the face
▪Roll (float): Value representing the face rotation on the roll axis.
▪Yaw (float): Value representing the face rotation on the yaw axis.
▪Pitch (float): Value representing the face rotation on the pitch axis.
oQuality (Object):
▪Brightness (float): face's brightness in a value between 0 and 100. A higher value indicates a brighter face.
▪Sharpness (float): face's sharpness in a value between 0 and 100. A higher value indicates a sharper face..
oLandmarks (array de Objects): location of the landmarks on the face
▪Type (string): landmark type. For example: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. These are the different parts found on a face.
▪X (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's x coordinate is positioned at 350px, this field would have as value 0.5.
▪Y (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's y coordinate is positioned at 350px, this field would have as value 0.5.
Compare faces
Compares a face in the source input image with each of the 100 largest faces detected in the target input image.
To configure its inputs, take into account the following descriptions:
•SourceImage (Collection - Required): input image of a face, encoded in base64 format. If there are two or more faces, the biggest one will be considered.
•TargetImage (Collection - Required): input image where the SourceImage will be searched for, encoded in base64 format.
•similarityThreshold (Float): Minimum confidence level for a face to be included in the response.
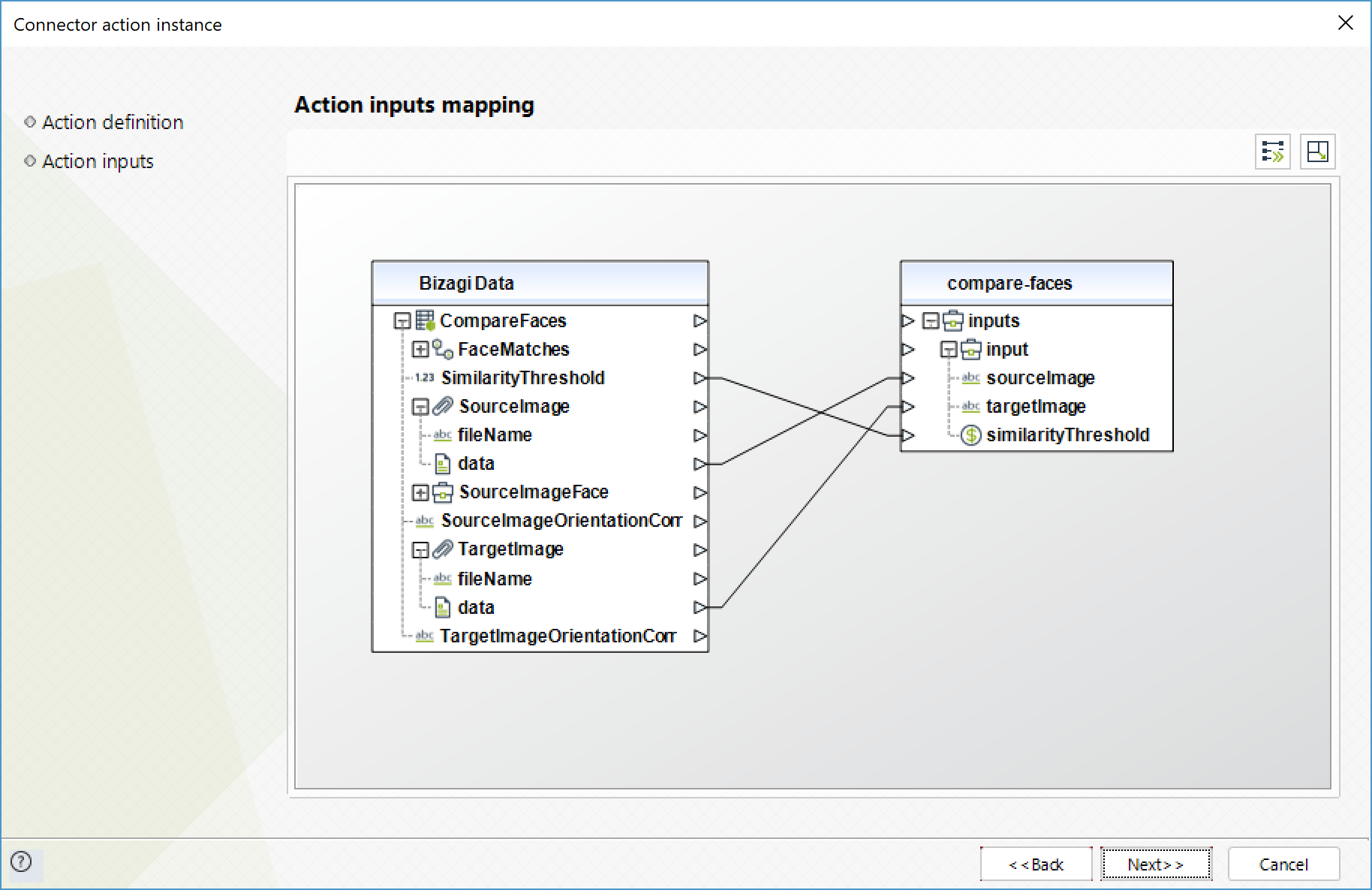
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•SourceImageFace (Objeto): face detected in the source image, used for the comparison.
oBoundingBox (Object): box that surrounds the detected face.
▪Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
▪Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
▪Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Confidence (float): confidence level that what the BoundingBox contains is a face.
•FaceMatches (Colección): array of the faces in the target image that match with the face of the source image.
oSimilarity (Flotante): confidence level on the match of the faces.
oFace (Objeto): detected face
▪BoundingBox (Object): box that surrounds the detected face.
•Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
•Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
•Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Confidence (float): confidence level that what the BoundingBox contains is a face.
▪Pose (Object): indicates the pose of the face
•Roll (float): Value representing the face rotation on the roll axis.
•Yaw (float): Value representing the face rotation on the yaw axis.
•Pitch (float): Value representing the face rotation on the pitch axis.
▪Quality (Object):
•Brightness (float): face's brightness in a value between 0 and 100. A higher value indicates a brighter face.
•Sharpness (float): face's sharpness in a value between 0 and 100. A higher value indicates a sharper face..
▪Landmarks (array de Objects): location of the landmarks on the face
•Type (string): landmark type. For example: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. These are the different parts found on a face.
•X (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's x coordinate is positioned at 350px, this field would have as value 0.5.
•Y (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's y coordinate is positioned at 350px, this field would have as value 0.5.
•SourceImageOrientationCorrection (Texto): orientation of the source image. Possible values include "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". If the image metadata contains an orientation, Rekognition does not perform a correction for the orientation and the value of this attribute would be NULL.
•TargetImageOrientationCorrection (Texto): orientation of the target image. Possible values include "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". If the image metadata contains an orientation, Rekognition does not perform a correction for the orientation and the value of this attribute would be NULL.
Create collection
Creates a collection in an AWS Region. You can add faces to the collection using the operation.
To configure its inputs, take into account the following descriptions:
•CollectionID (String - Required): ID of the collection to be created, it is case sensitive. This parameter is required for the service invocation to be successful.
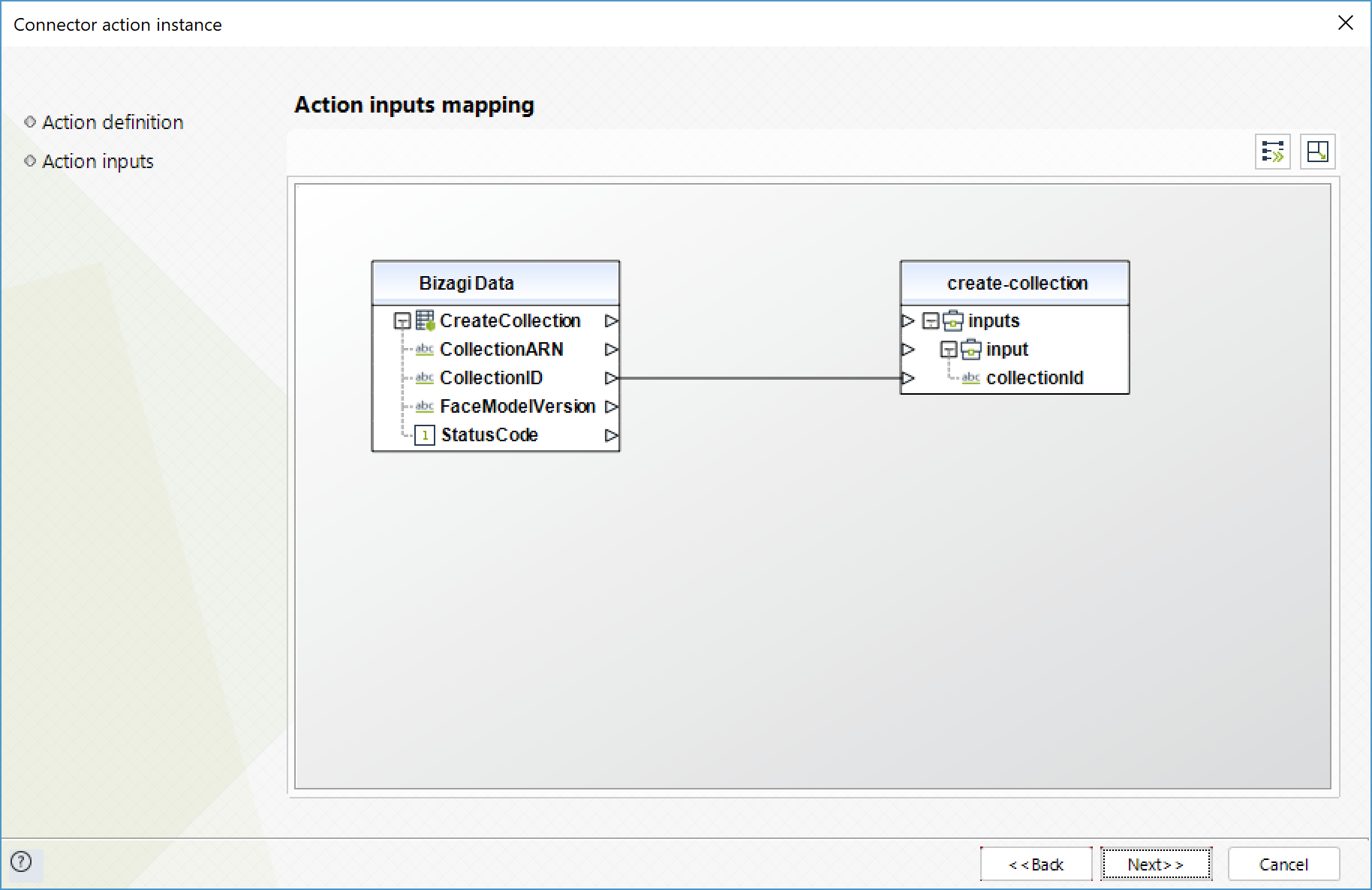
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•StatusCode (Entero): HTTP code that indicates the result of the operation.
•CollectionArn (Texto): Collection's Amazon Resource Name (ARN)
•FaceModelVersion (Texto): version number of the face detection model associated to the collection created.
List collections
Returns list of collection IDs in your account. If the result is truncated, the response also provides a NextToken that you can use in the subsequent request to fetch the next set of collection IDs.
To configure its inputs, take into account the following descriptions:
•MaxResults (Integer): Maximum amount of results to retrieve.
•NextToken (String): Pagination token of the previous result.
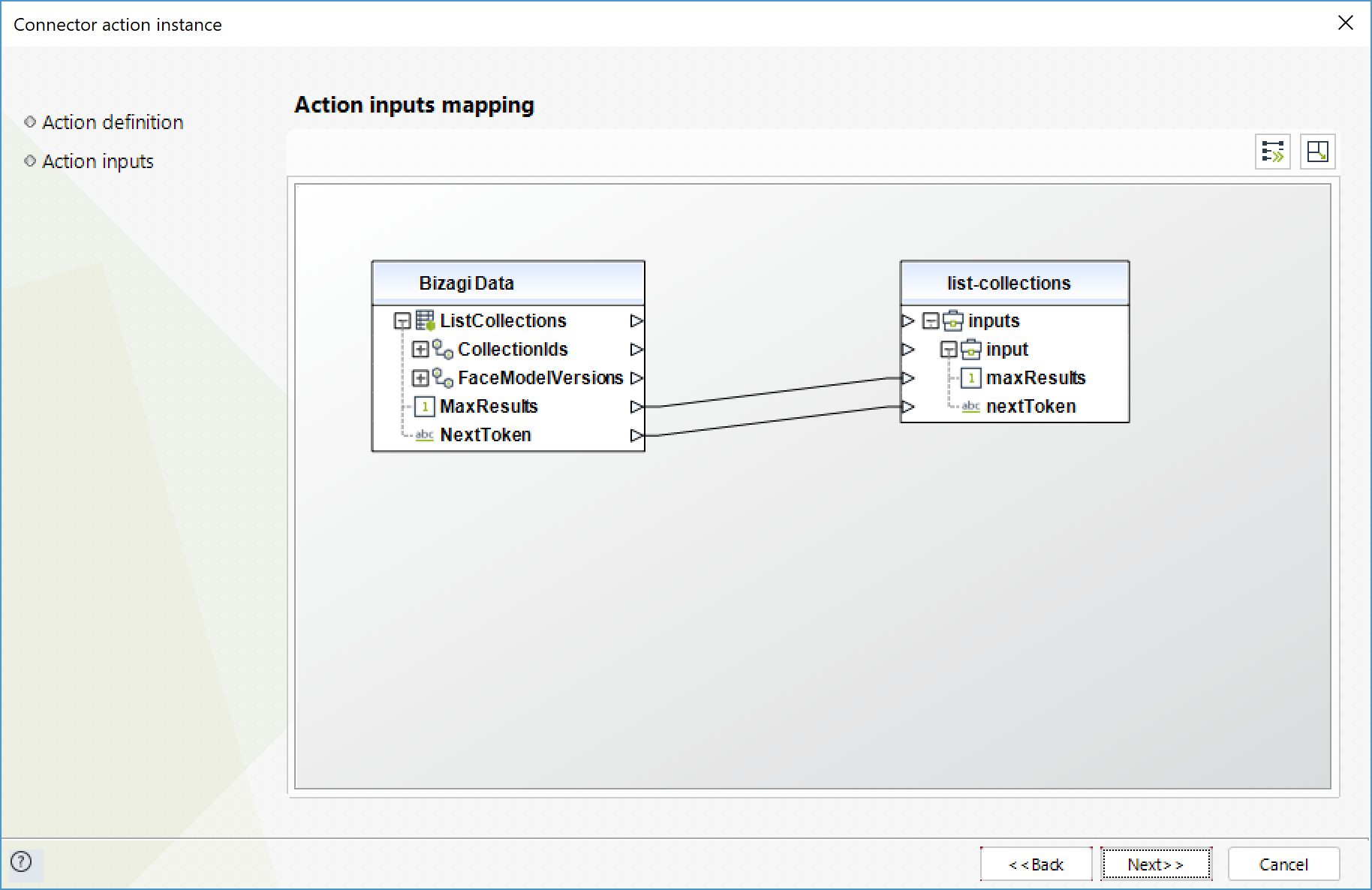
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•CollectionIds (Colección): array with the IDs of the collections.
•NextToken (Texto): if the result is truncated, the response provides this value to be used in future requests to obtain the next set of collection IDs.
•FaceModelVersions (Colección): version numbers of the face detection models associated to the collections in the array of collection IDs. For example, the value of FaceModelVersions[2] corresponds to the version of the detection model used by the collection CollectionIds[2]
Delete collection
Deletes the specified collection.
To configure its inputs, take into account the following descriptions:
•CollectionID (String - Required): ID of the collection to be deleted.
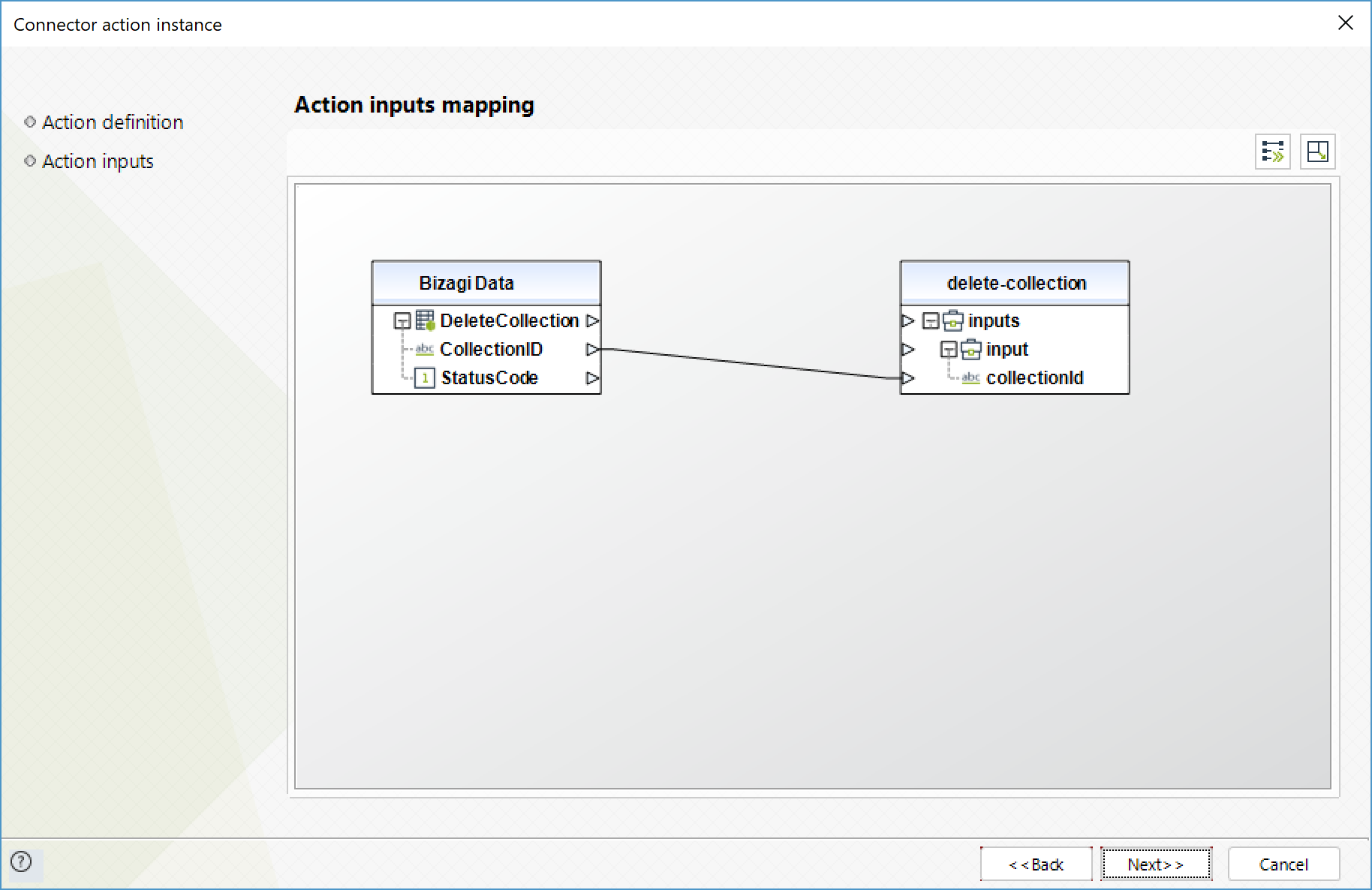
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•StatusCode (Entero): HTTP code that indicates the result of the operation.
Index faces
Detects faces in the input image and adds them to the specified collection.
To configure its inputs, take into account the following descriptions:
•CollectionID (String - Required): ID of the collection to add faces.
•Data (String - Required): input image encoded in base64 format.
•ExternalImageId (String): ID to assign to all detected faces.
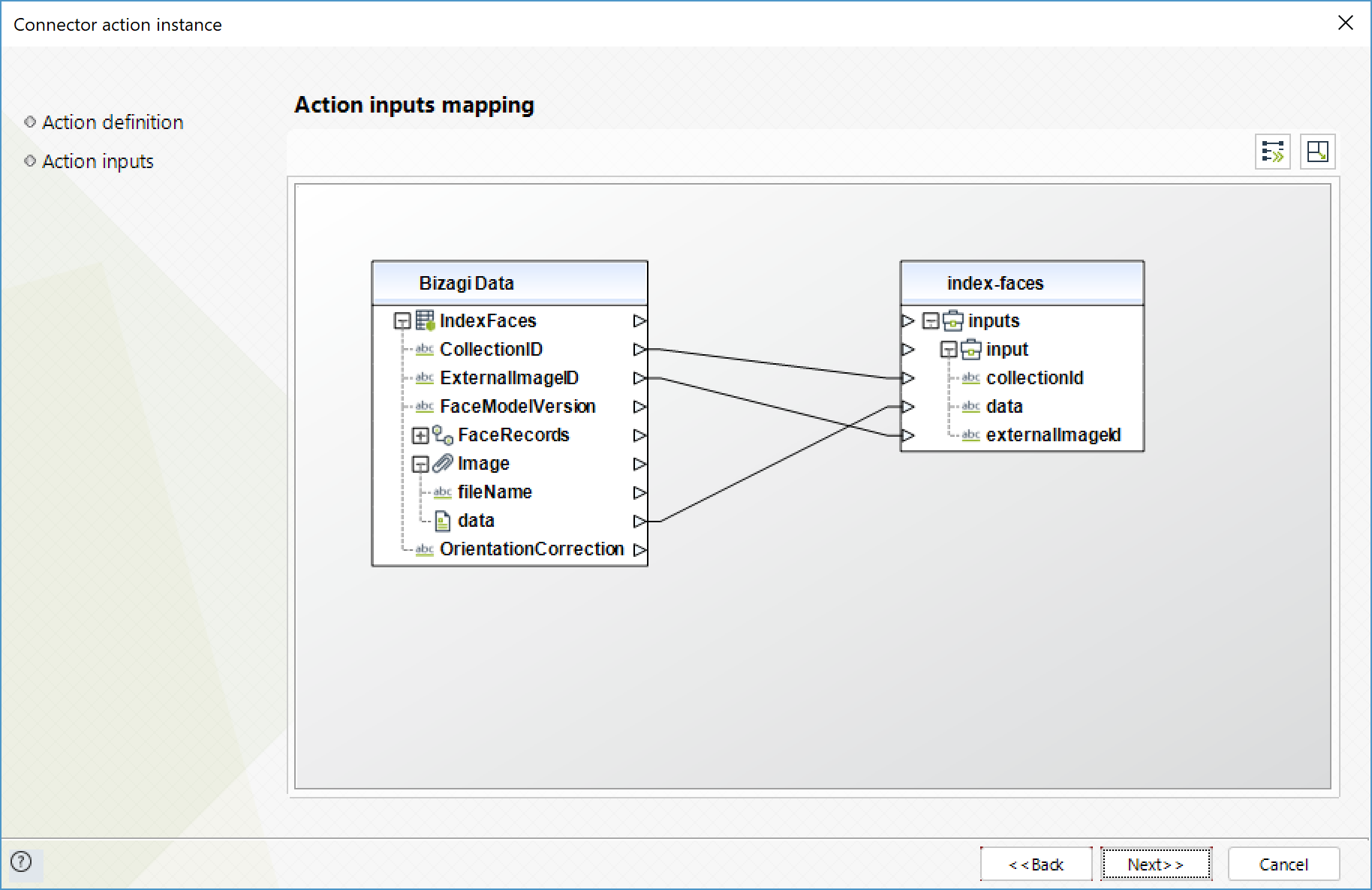
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•FaceRecords (Colección): collection of the faces detected that are going to be added to the collection.
oFace (Objeto): cara detectada.
▪FaceId (Texto): ID that Amazon Rekognition assigns to the face.
▪ImageId (Texto): ID that Amazon Rekognition assigns to the source image.
▪ExternalImageId (Texto): ID assigned to all the faces in the source image.
oFaceDetails (Colección): si no detecta ninguna cara, este arreglo estará vacio
▪BoundingBox (Object): box that surrounds the detected face.
•Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
•Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
•Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Confidence (float): confidence level that what the BoundingBox contains is a face.
▪Pose (Object): indicates the pose of the face
•Roll (float): Value representing the face rotation on the roll axis.
•Yaw (float): Value representing the face rotation on the yaw axis.
•Pitch (float): Value representing the face rotation on the pitch axis.
▪Quality (Object):
•Brightness (float): face's brightness in a value between 0 and 100. A higher value indicates a brighter face.
•Sharpness (float): face's sharpness in a value between 0 and 100. A higher value indicates a sharper face..
▪Landmarks (array de Objects): location of the landmarks on the face
•Type (string): landmark type. For example: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. These are the different parts found on a face.
•X (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's x coordinate is positioned at 350px, this field would have as value 0.5.
•Y (float): y coordinate from the upper left corner, as a proportion of the width of the image. For example, if the image is 700x200 px, the landmark's y coordinate is positioned at 350px, this field would have as value 0.5.
▪AgeRange (Object): estimated age range, in years, for the face.
•Low (integer): lowest estimated age
•High (integer): highest estimated age
▪Smile (Object): indicates whether or not the face is smiling.
•Value (boolean): true if the face is smilent, false if it is not.
•Confidence (float): confidence level in the smile's determination.
▪Gender (Object): predicted gender of the face.
•Value (string): face's gender. Possible values include "Male", "Female".
•Confidence (float): confidence level in the gender's determination.
▪Emotions (array de Objects): emotions that appear on the face.
•Type (string): type of emotion detected. Possible values include "HAPPY", "SAD", "ANGRY", "CONFUSED", "DISGUSTED", "SURPRISED", "CALM", "UNKNOWN".
•Confidence (float): confidence level in the emotion's determination.
oOrientationCorrection (string): image's orientation. Possible values include "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". If the image metadata contains an orientation, Rekognition does not perform a correction for the orientation and the value of this attribute would be NULL.
•FaceModelVersion (Texto): version number of the face detection model associated to the collection created.
List faces
Returns metadata for faces in the specified collection.
To configure its inputs, take into account the following descriptions:
•CollectionID (String - Required): ID of the collection of the faces to list.
•MaxResults (Integer): Maximum number of results returned.
•NextToken (Float): pagination token from the previous response.
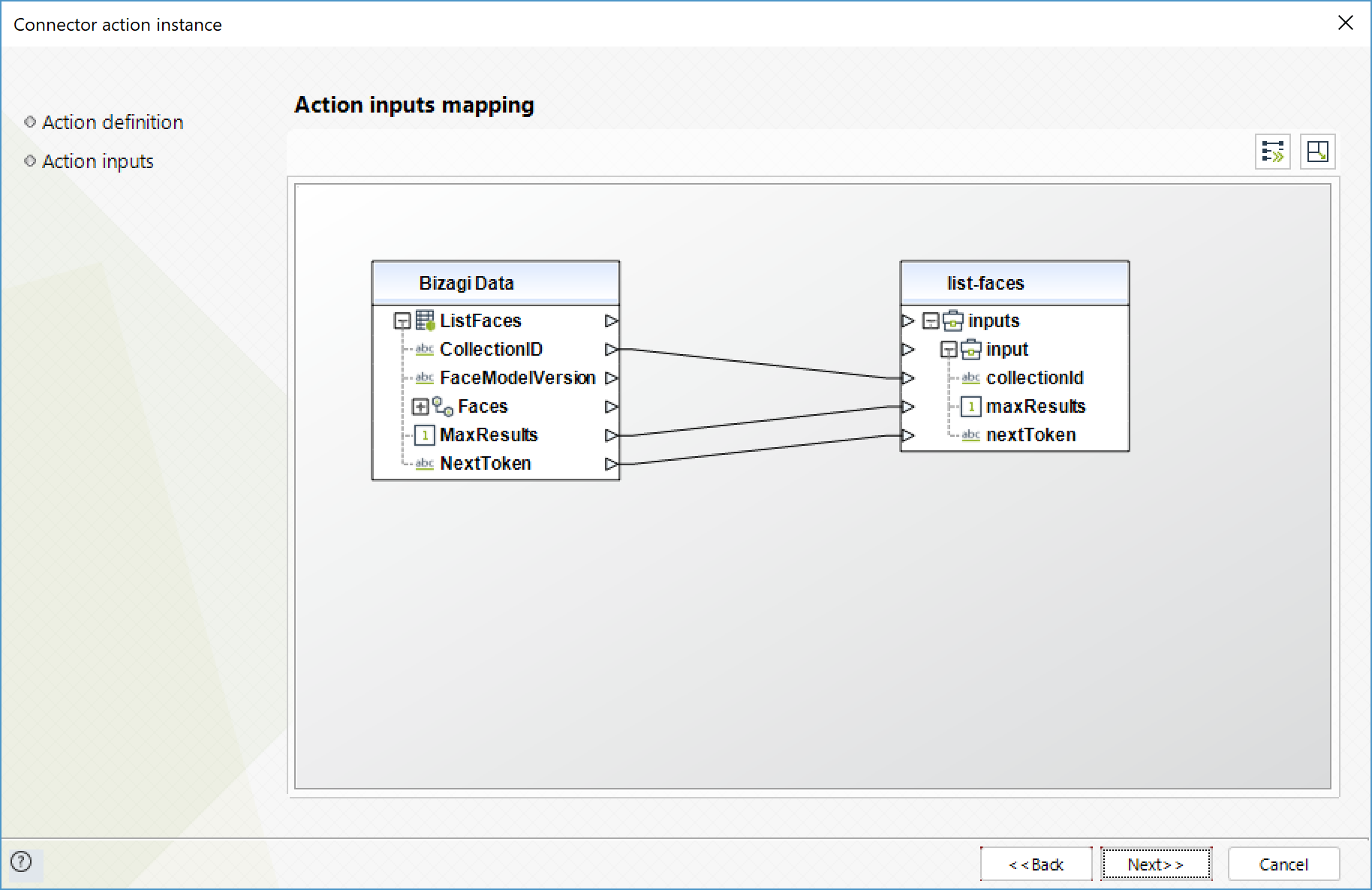
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•Faces (Colección):
oFaceId (Texto): unique ID assigned by Amazon Rekognition to the face.
▪BoundingBox (Object): box that surrounds the detected face.
•Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
•Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
•Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪ImageId (Texto): unique ID assigned by Amazon Rekognition to the source image.
▪ExternalImageId (Texto): ID assigned to all the faces of the source image.
▪Confidence (float): confidence level that what the BoundingBox contains is a face.
oNextToken (Texto): if the result is truncated, the response provides this value to be used in future requests to obtain the next set of collection IDs.
oFaceModelVersion (Texto): version number of the face detection model associated to the collection created.
Search faces
For a given input face ID, searches for matching faces in the collection the face belongs to.
To configure its inputs, take into account the following descriptions:
•CollectionID (String - Required): ID of the collection to get the faces from.
•FaceID (Text - Required): ID of the face to search for.
•MaxFaces (Integer): Maximum amount of results to be returned.
•faceMatchThreshold (Float): minimum confidence for a result to be included in the response.
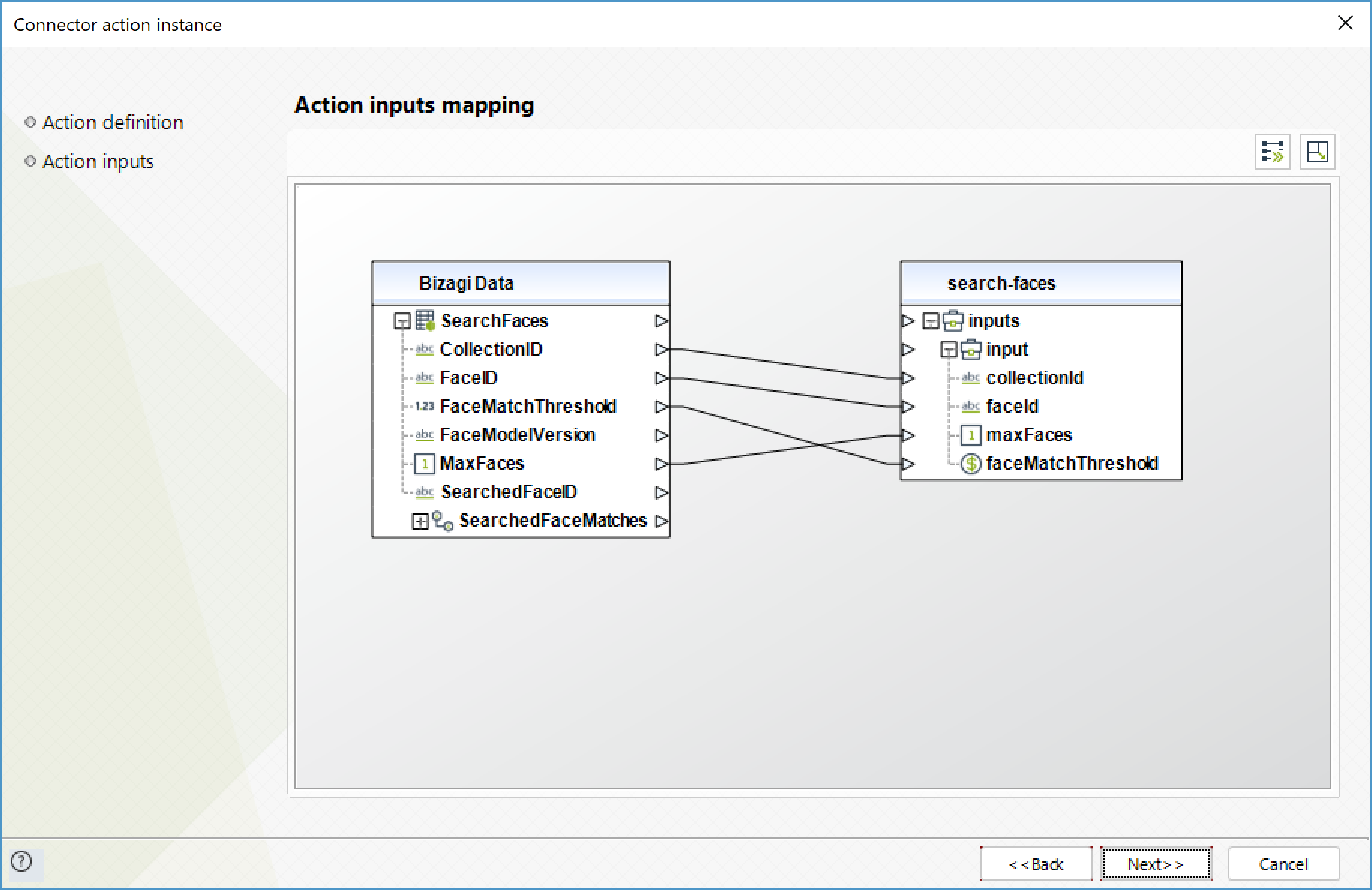
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•SearchedFaceId (Texto): ID of the searched face in the collection.
•FaceMatches (Colección): collection of the faces found according to the search performed.
oFace (Objeto): detected face.
oFaceId (Texto): unique ID assigned to the face by Amazon Rekognition.
oBoundingBox (Object): box that surrounds the detected face.
▪Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
▪Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
▪Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
oImageId (Texto): unique ID assigned by Amazon Rekognition to the source image.
oExternalImageId (Texto): ID assigned to all the faces of the source image.
oConfidence (float): confidence level that what the BoundingBox contains is a face.
oSimilarity (Flotante): confidence level on the match of the faces.
•FaceModelVersion (Texto): version number of the face detection model associated to the collection created.
Search faces by image
For a given input image, first detects the largest face in the image, and then searches the specified collection for matching faces.
To configure its inputs, take into account the following descriptions:
•CollectionID (String - Required): ID of the collection to get the faces from.
•Data (String - Required): Image of the face to search for, encoded in base64 format.
•MaxFaces (Integer): Maximum amount of results to be returned.
•faceMatchThreshold (Float): minimum confidence for a result to be included in the response.
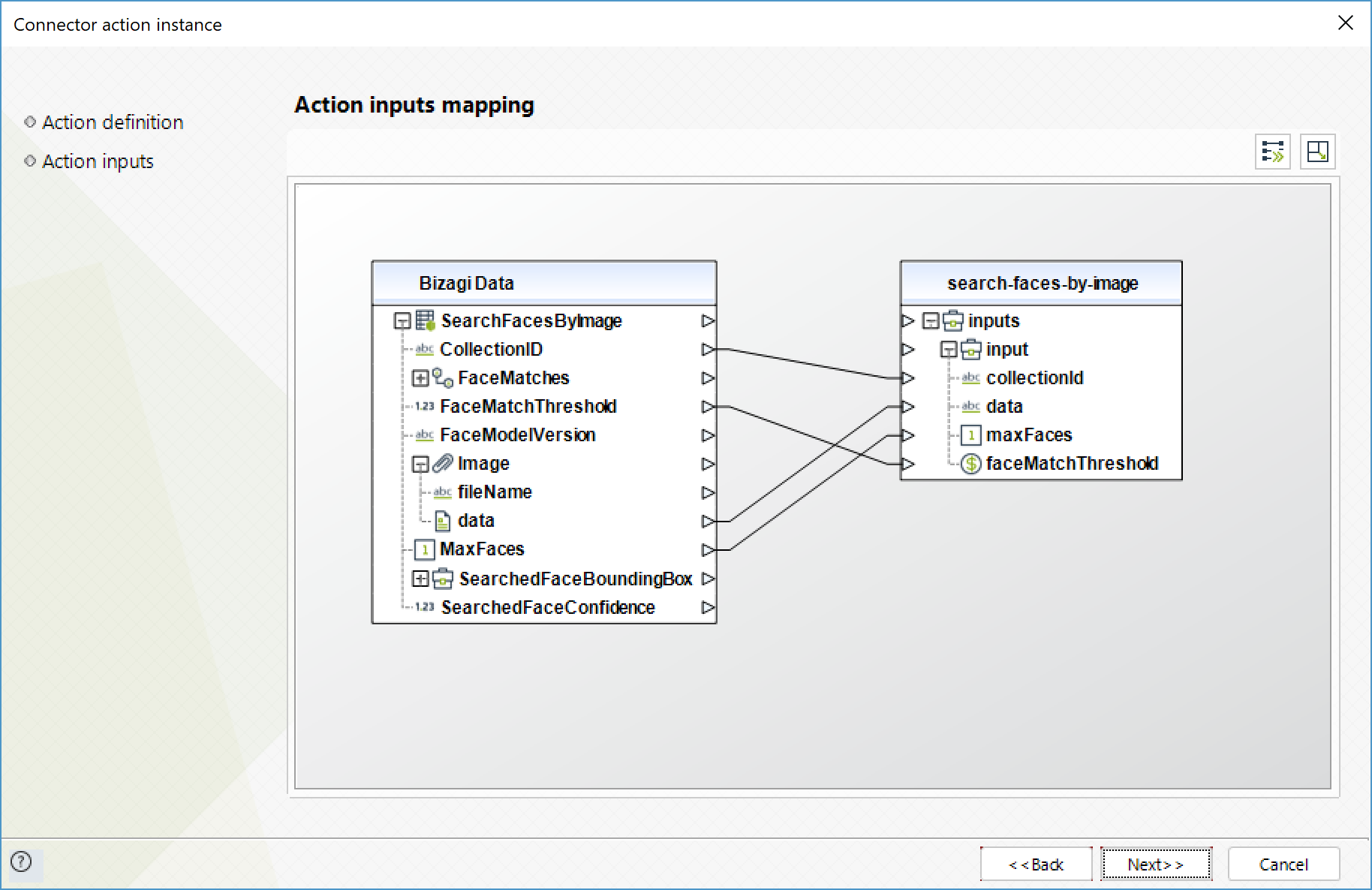
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•SearchedFaceBoundingBox (Objeto): bounding box surrounding the face in the source image, which is the one used by Amazon Rekognition utiliza for the search. Rekognition first detects the bigger face and then looks in the collection the faces that make a match.
oWidth (float): box's width that surrounds the face, as a proportion of the total width of the image.
oHeight (float): box's height that surrounds the face, as a proportion of the total height of the image.
oLeft (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
oTop (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
•SearchedFaceConfidence (Flotante): lever of confidence that the SearchedFaceBoundingBox contains a face.
•FaceMatches (Colección): collection of the facs found according to the search.
oFace (Objeto): detected face.
oFaceId (Texto): unique ID assigned to the face by Amazon Rekognition.
oBoundingBox (Object): box that surrounds the detected face.
▪Width (float): box's width that surrounds the face, as a proportion of the total width of the image.
▪Height (float): box's height that surrounds the face, as a proportion of the total height of the image.
▪Left (float): left coordinate of the box that surrounds the face, as a proportion of the total width of the image.
▪Top (float): top coordinate of the box that surrounds the face, as a proportion of the total width of the image.
oImageId (Texto): unique ID assigned by Amazon Rekognition to the source image.
oExternalImageId (Texto): ID assigned to all the faces of the source image.
oConfidence (float): confidence level that what the BoundingBox contains is a face.
oSimilarity (Flotante): confidence level on the match of the faces.
•FaceModelVersion (Texto): version number of the face detection model associated to the collection created.
Delete faces
Deletes the specified faces from a given collection.
To configure its inputs, take into account the following descriptions:
•FaceIDs (Text - Required): IDs of the faces to delete from the collection.
•CollectionID (Text - Required): ID of the collection to delete faces from.
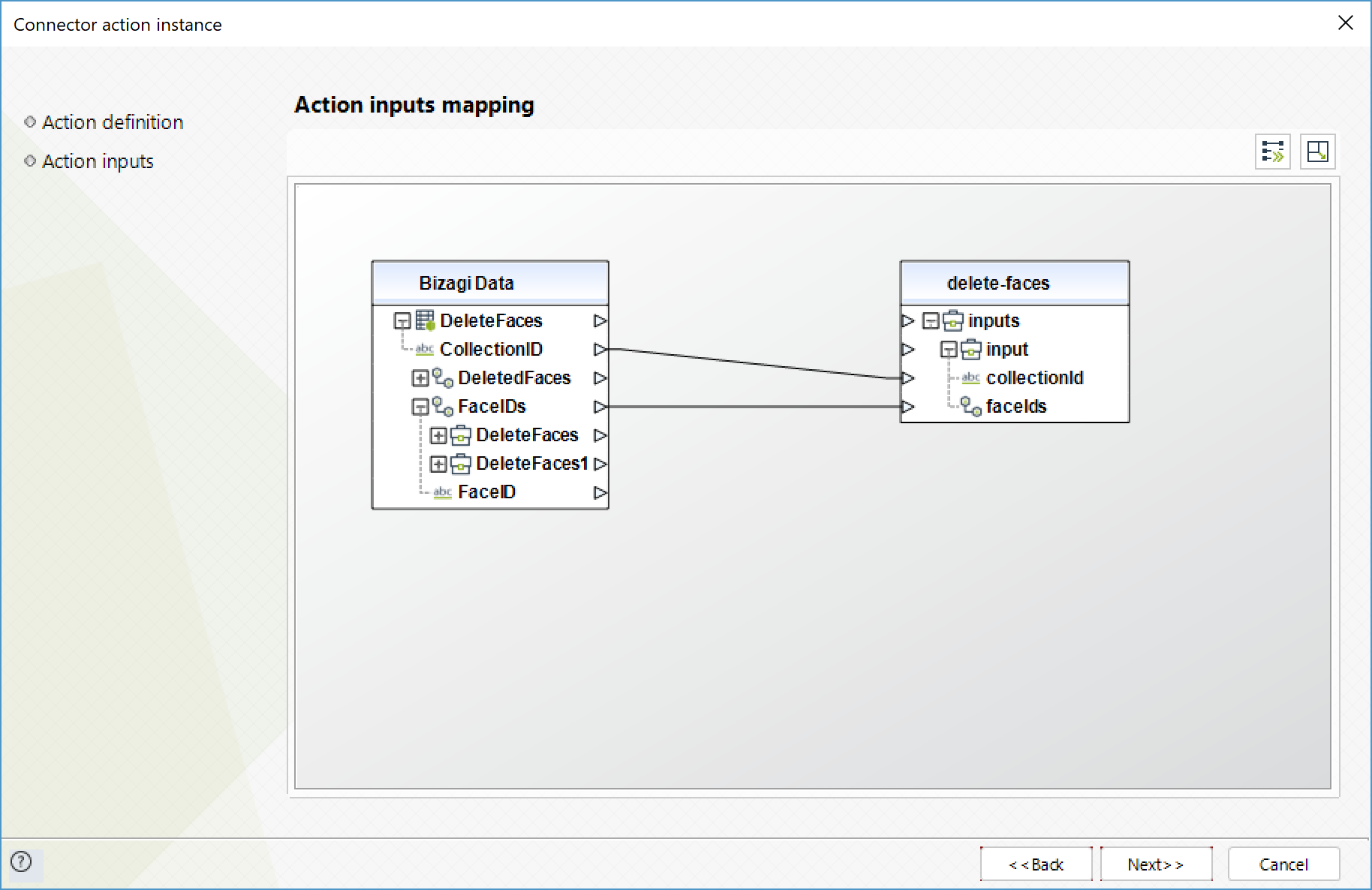
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi. Make sure you map the attributes of the entity appropriately.
•DeletedFaces (Colección): collection with the IDs of the faces that were deleted.
For more information about this methods, refer to Amazon's Rekognition official documentation at https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html.
Last Updated 10/27/2022 9:29:18 AM