Overview
The Bizagi Amazon Comprehend connector is available on the Bizagi Connectors Xchange.
Through this connector, you will be able to connect your Bizagi processes to an Amazon Comprehend account and use its services.
For more information on the capabilities of this connector, visit our Connectors Xchange.
|
This Connector was developed according to the contents of the API and the information about it provided by Amazon Comprehend. Bizagi and its subsidiaries will not provide any kind of guarantee over the content or error caused by calling the API services. Bizagi and its subsidiaries are not responsible for any loss, cost or damage consequence of the calls to Amazon Comprehend's API. |

Before You Start
To test and use this connector, you will need:
1.Bizagi Studio previously installed.
2.This connector previously installed, as described in the Connectors Xchange article, or through a manual installation as described in the Installing and managing connectors article.
3.An account on Amazon Comprehend.
How to Create an Account on Amazon Comprehend
To use the Amazon Comprehend connector, you need to create an account that will allow you to obtain an access key and a secret key. To achieve this, complete the following steps:
1.Go to https://aws.amazon.com/free/ and click Create a free account.
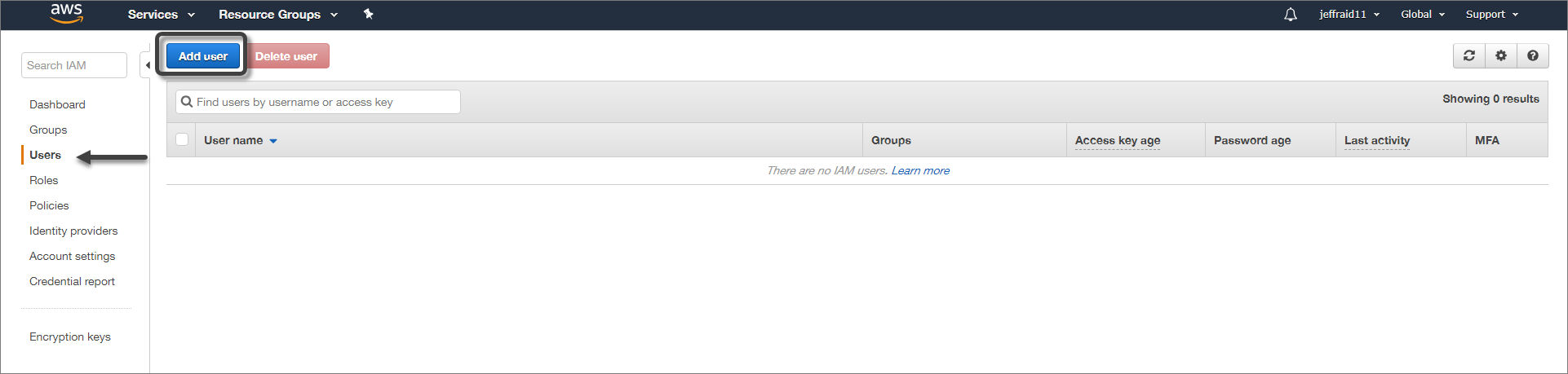
2.After registering, in the main window select the Users option located on the left panel and then click Add User.
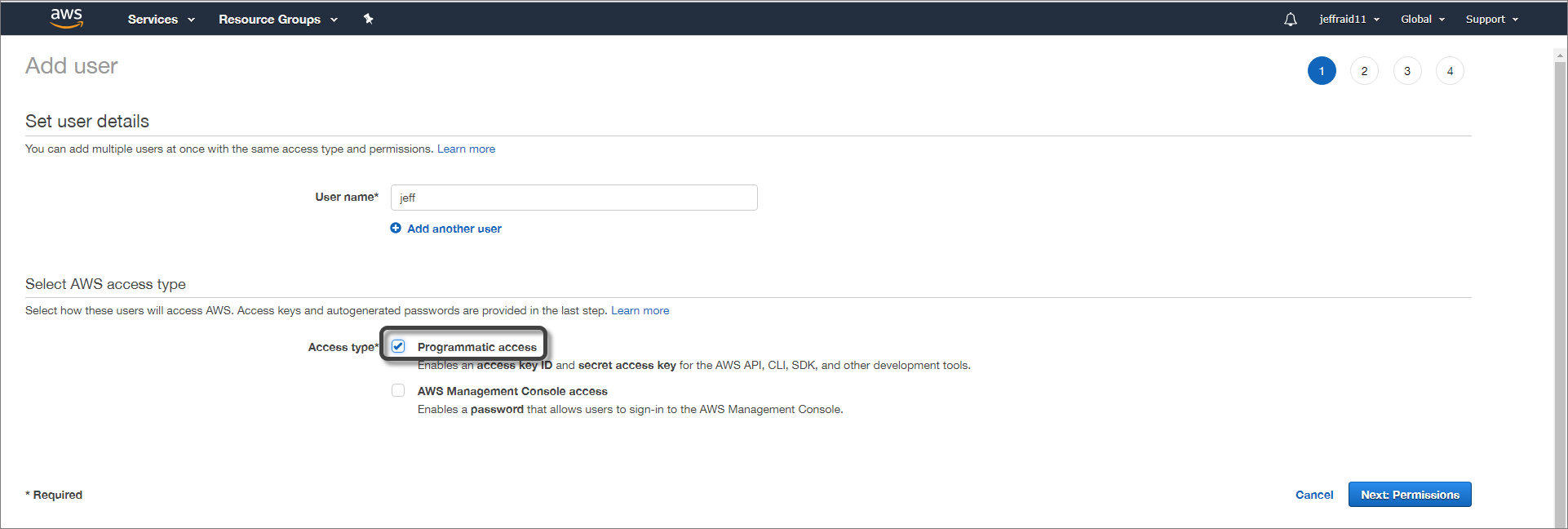
3.In the access type section, select the Programmatic Access option.
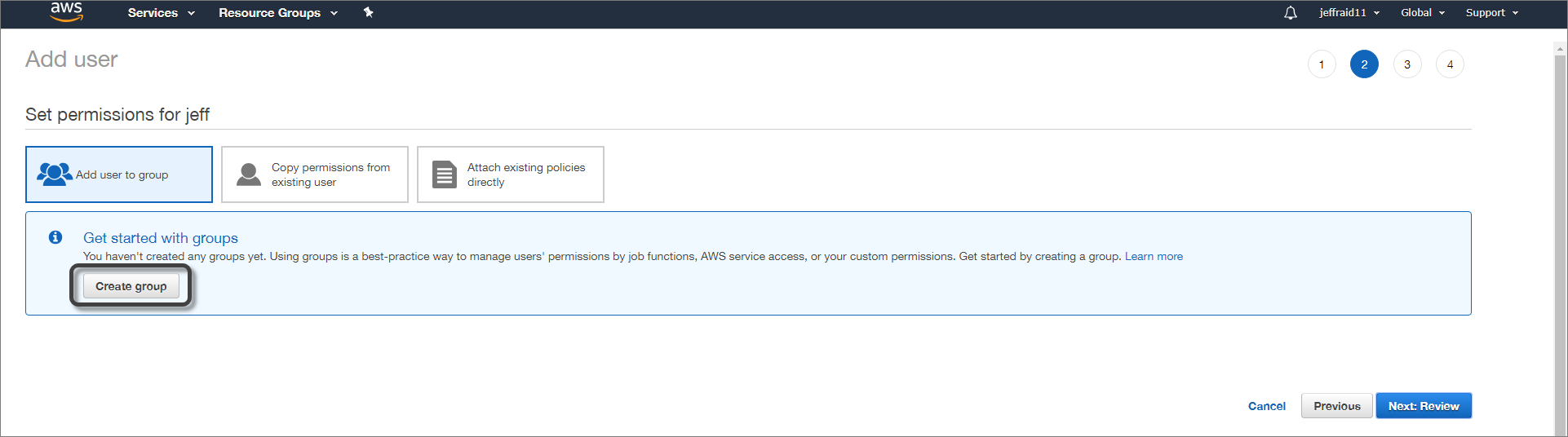
4.On the next page, click Create group.
5.Give the group a name and enable the AdministratorAccess option. Finally, click on Create Group and then on Next.
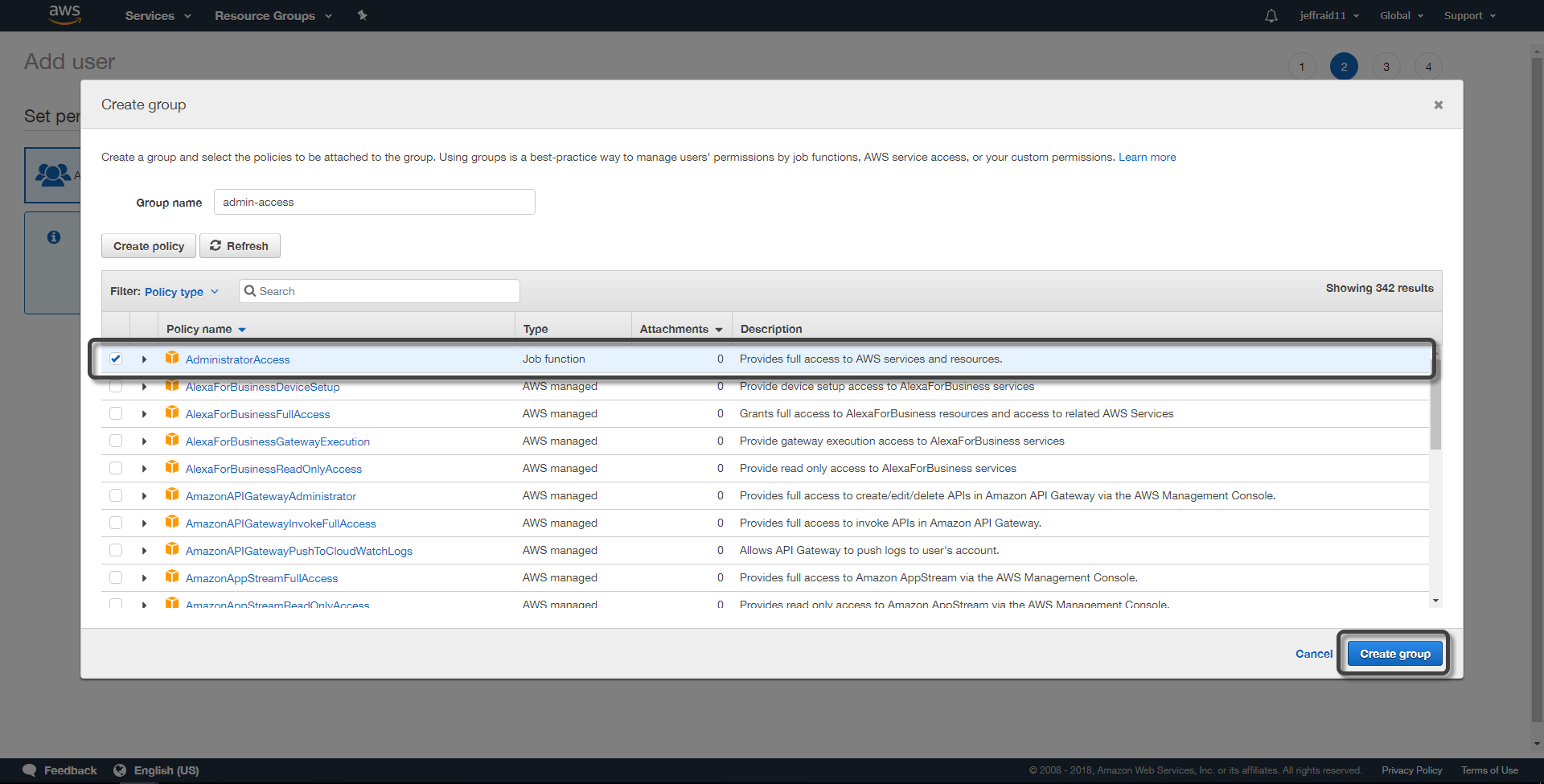
6.Finally, click on Create User.
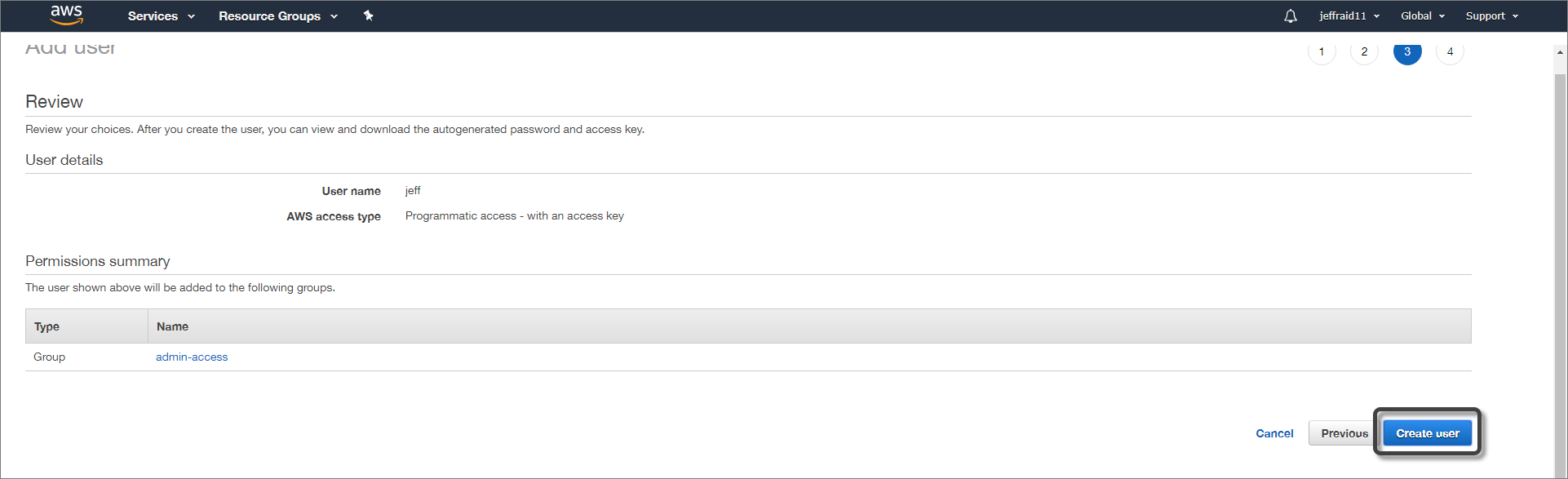
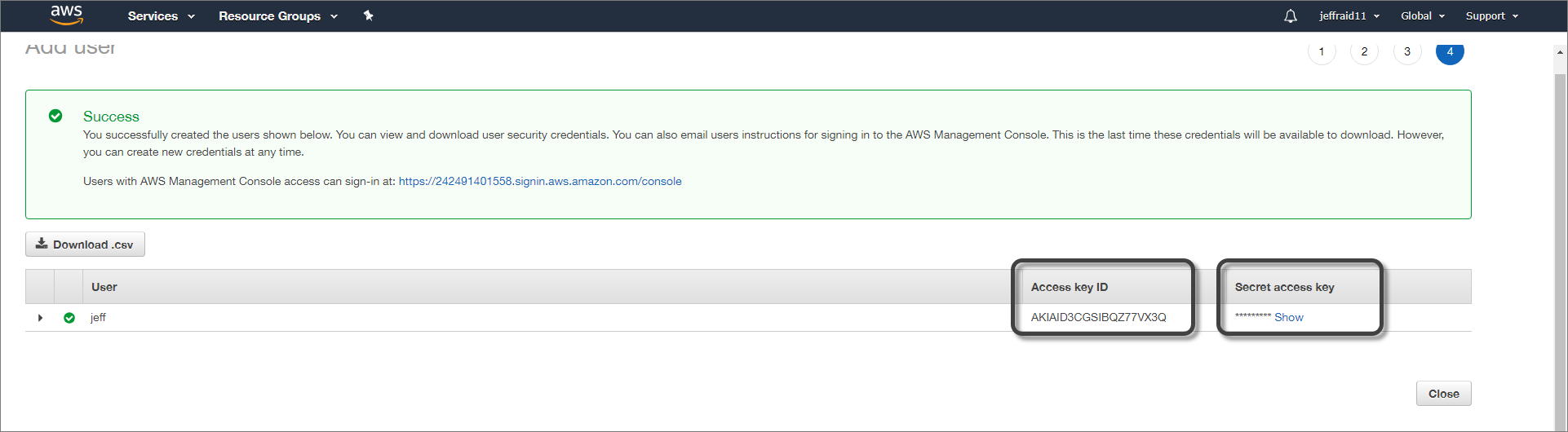
In the details window after user creation, copy the access key ID and the secret access key.
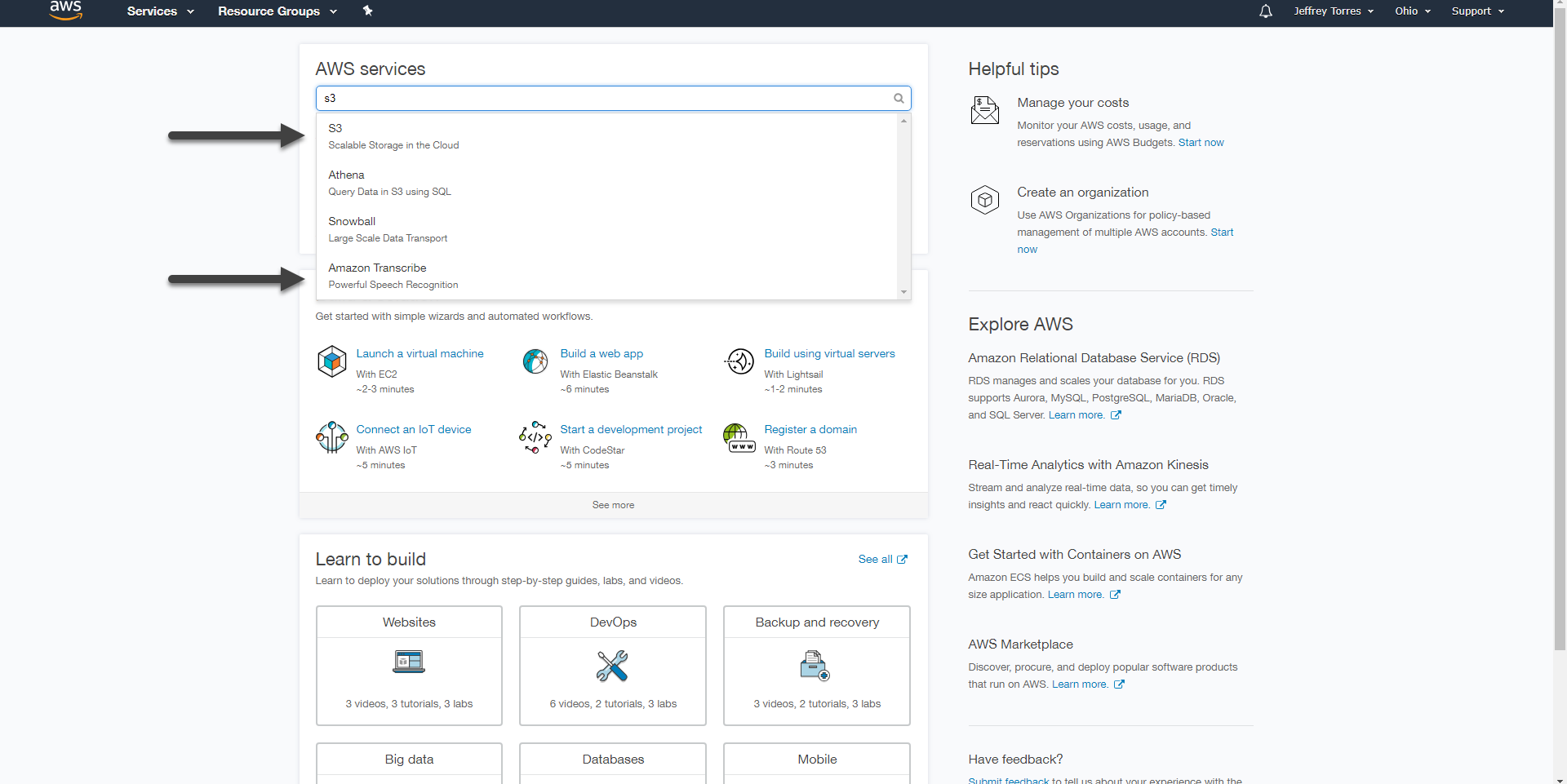
To use the Amazon translation service, go to the AWS console and search for Amazon Translate and S3 in the search bar. The S3 service will be used to view the files that are created with the connector and the results of some of the connector actions. The rest can be evidenced in Amazon Translate.
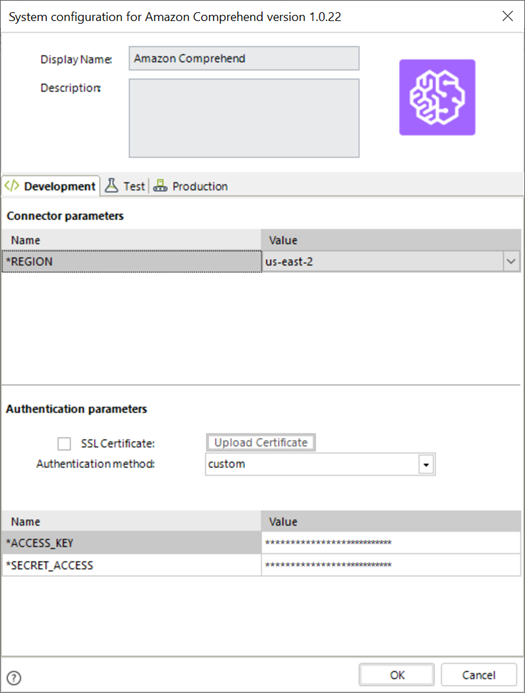
Configuring the Connector
To configure the connector (in particular its authentication parameters), follow the steps presented at the Configuration chapter in the Installing and managing connectors article.
For this configuration, consider the following authentication parameters:
•Authentication method: custom.
•ACCESS_KEY: Access key that you obtained in the previous section.
•SECRET_ACCESS: Secret key you got in the previous section.
•REGION: Region where the Amazon Translate S3 service is located. This can be verified in the AWS console URL after logging in.
Using the Connector
This connector allows the use from Bizagi of various methods available for the use of Amazon's artificial intelligence services.
To learn overall how/where to configure the use of a connector, refer to the Using Connectors article.
When using the connector, keep in mind they may need input or output configurations. The following images show examples of how to map the inputs or outputs of a method.

Available Actions
Detect PII Entities
Inspects the input text for entities that contain personally identifiable information (PII) and returns information about them.
To configure its inputs, take into account the following descriptions:
• Text (String - Required): A string of UTF-8 text. Each string must contain less than 5000 bytes of UTF-8 encoded characters. This parameter must be of type String in your Bizagi model.
• LanguageCode (String - Required): The language of the input documents. Possible values include: "in". This parameter must be of type String in your Bizagi model.
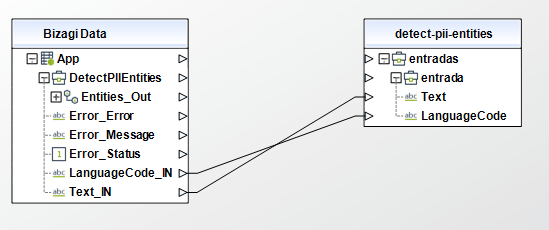
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•Entities (Collection): A collection of PII entities identified in the input text. For each entity, the response provides the entity type, where the entity text begins and ends, and the level of confidence Amazon Comprehend has in detection.
oScore (Float): The level of confidence Amazon Comprehend has in the accuracy of the detection.
oType (String): Type of entity. Possible values include:
▪"BANK_ACCOUNT_NUMBER"
▪"BANK_ROUTING"
▪"CREDIT_DEBIT_NUMBER"
▪"CREDIT_DEBIT_CVV"
▪"CREDIT_DEBIT_EXPIRY"
▪"PIN"
▪"EMAIL"
▪"ADDRESS"
▪"NAME"
▪"PHONE"
▪"SSN"
▪"DATE_TIME"
▪"PASSPORT_NUMBER"
▪"DRIVER_ID"
▪"URL"
▪"AGE"
▪"USERNAME"
▪"PASSWORD"
▪"AWS_ACCESS_KEY"
▪"AWS_SECRET_KEY"
▪"IP_ADDRESS"
▪"MAC_ADDRESS"
▪"ALL""
oBeginOffset (Integer): A character offset in the input text that shows where the PII entity begins (the first character is at position 0). The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character of a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
oEndOffset - (Integer): An offset character in the input text that shows where the PII entity ends. The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character of a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectPiiEntities.html.
Detect Entities
Inspects text for named entities, and returns information about them.
To configure its inputs, take into account the following descriptions:
• Text (String - Required): A UTF-8 text string. Each string must contain less than 5000 bytes of UTF-8 encoded characters. This parameter must be of type String in your Bizagi model.
• LanguageCode (String): The language of the input documents. You can specify any of the major languages supported by Amazon Comprehend. All documents must be in the same language. If your request includes the endpoint for a custom entity recognition model, Amazon Comprehend uses the language of your custom model and ignores any language codes that you specify here. Possible values include: "en" "es" "fr" "de" "it" "pt" "ar" "hi" "ja" "ko" "zh" "zh-TW"
• EndpointArn (String): The Amazon resource name of an endpoint associated with a custom entity recognition model. Provide an endpoint if you want to discover entities using your own custom model instead of the default model that Amazon Comprehend uses. If you specify an endpoint, Amazon Comprehend uses the language of your custom model and ignores any language codes that you provide in your request.
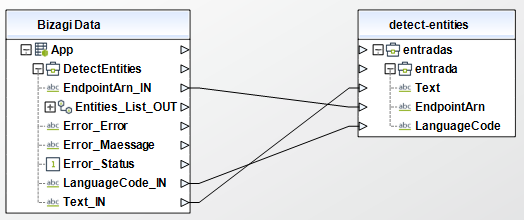
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•Entities (Collection): A collection of entities identified in the input text. For each entity, the response provides the entity text, the entity type, where the entity text begins and ends, and the level of confidence Amazon Comprehend has in detection. If your request uses a custom entity recognition model, Amazon Comprehend detects the entities that the model is capable of recognizing. Otherwise, it detects the default entity types. For a list of the default entity types, see how-entities.
oScore - (Float): The level of confidence Amazon Comprehend has in the accuracy of the detection.
oType - (String): The type of entity. Possible values include:
▪"PERSON"
▪"LOCATION"
▪"ORGANIZATION"
▪"COMMERCIAL_ITEM"
▪"EVENT"
▪"DATE"
▪"QUANTITY"
▪"TITLE"
▪"OTHER"
oText - (String): The text of the entity.
oBeginOffset - (Integer): An offset character in the input text that shows where the feature begins (the first character is at position 0). The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character of a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
oEndOffset - (Integer): An offset character in the input text that shows where the entity ends. The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character of a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
•error (Object):
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectEntities.html.
Batch Detect Entities
Inspects the text of a batch of documents for named entities and returns information about them.
To configure its inputs, take into account the following descriptions:
• TextList (Collection - Required): A list containing the text of the input documents. The list can contain a maximum of 25 documents. Each document must contain less than 5000 bytes of UTF-8 encoded characters.
•LanguageCode (String - Required): The language of the input documents. You can specify any of the major languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW". This parameter must be of type String in your Bizagi model.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•ResultList (Collection): A list of objects that contain the results of the operation. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If all the documents contain an error, the Results List is empty.
oIndex (Integer): The zero-based index of the document in the input list.
oEntities (Collection): One or more Entity objects, one for each entity found in the document.
▪Score (Float): The level of confidence that Amazon Comprehend has in the accuracy of the detection.
▪Type (String): The type of the entity.
▪Possible values include:
•"PERSON"
•"LOCATION"
•"ORGANIZATION"
•"COMMERCIAL_ITEM"
•"EVENT"
•"DATE"
•"QUANTITY"
•"TITLE"
•"OTHER"
▪Text (String): The entity's text.
▪BeginOffset (Integer): An offset character in the input text that shows where the feature begins (the first character is at position 0). The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character of a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
▪EndOffset (Integer): An offset character in the input text that shows where the entity ends. The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character of a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
•ErrorList (Collection): A list that contains an object for each document that contains an error. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If there are no errors in the batch, ErrorList is empty.
oIndex (Integer): The zero-based index of the document in the input list.
oErrorCode (String): The numerical error code of the error.
oErrorMessage (String): A text description of the error.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_BatchDetectEntities.html.
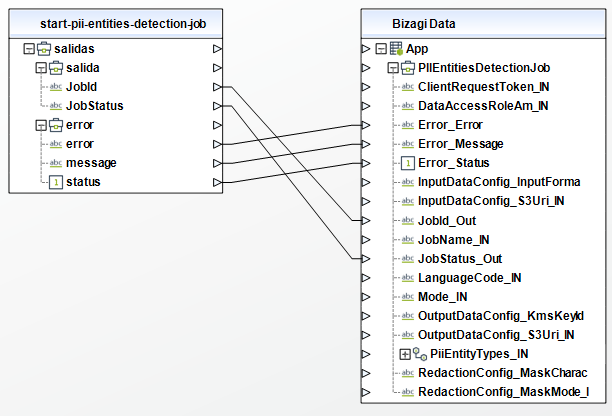
Start PII Entities Detection Job
Starts an asynchronous PII entity detection job for a collection of documents.
To configure its inputs, take into account the following descriptions:
• InputDataConfig (Object - Required): The input properties for a PII entities detection job. This parameter must be an object in your Bizagi model.
o S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the URI S3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend uses all of them as input. This parameter must be of type String in your Bizagi model.
o InputFormat (String) Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.Possible values include:"ONE_DOC_PER_FILE""ONE_DOC_PER_LINE"
• OutputDataConfig (Object - Required): Provides conguration parameters for the output of PII entity detection jobs. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file. When the topic detection job is finished, the service creates an output file in a directory specific to the job. The S3Uri field contains the location of the output file, called output.tar.gz. It is a compressed archive that contains the ouput of the operation. This parameter must be of type String in your Bizagi model.
o KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job. The KmsKeyId can be one of the following formats:KMS Key ID: "1234abcd-12ab-34cd-56ef-1234567890ab"Amazon Resource Name (ARN) of a KMS Key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"KMS Key Alias: "alias/ExampleAlias"ARN of a KMS Key Alias: "arn:aws:kms:us-west-2:111122223333:alias/ExampleAlias"
• Mode (String - Required): Specifies whether the output provides the locations (offsets) of PII entities or a file in which PII entities are redacted.Possible values include:"ONLY_REDACTION""ONLY_OFFSETS". This parameter must be of type String in your Bizagi model.
• RedactionConfig (Object): Provides configuration parameters for PII entity redaction. This parameter is required if you set the Mode parameter to ONLY_REDACTION. In that case, you must provide a RedactionConfig definition that includes the PiiEntityTypes parameter.
o PiiEntityTypes (Array): An array of the types of PII entities that Amazon Comprehend detects in the input text for your request.
o MaskMode (String): Specifies whether the PII entity is redacted with the mask character or the entity type. Possible values include:"MASK""REPLACE_WITH_PII_ENTITY_TYPE"
o MaskCharacter (String): A character that replaces each character in the redacted PII entity.
• DataAccessRoleArn (String - Required): The Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role that grants Amazon Comprehend read access to your input data.
• JobName (String): The identifier of the job.
• LanguageCode (String - Required): The language of the input documents. Possible values include: "en" . This parameter must be of type String in your Bizagi model.
• ClientRequestToken (String): A unique identifier for the request. If you don't set the client request token, Amazon Comprehend generates one. If a token is not provided, the SDK will use a version 4 UUID.

To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier generated for the job.
•JobStatus (String): Status of the job. Possible values include:
o"SUBMITTED"
o"IN_PROGRESS"
o"COMPLETED"
o"FAILED"
o"STOP_REQUESTED"
o"STOPPED"
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StartPiiEntitiesDetectionJob.html.
Describe PII Entities Detection Job
Gets the properties associated with a PII entities detection job. For example, you can use this operation to get the job status.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•PiiEntitiesDetectionJobProperties (Object): Provides information about a PII entity discovery job.
oDataAccessRoleArn (String): The Amazon Resource Name (ARN) that grants Amazon Comprehend read access to your input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (Date): The time the PII entity discovery job was submitted for processing.
oEndTime (Date): The time the PII entity discovery job completed.
oInputDataConfig (Object): The input properties for a PII entity discovery job.
▪S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in the same region as the API endpoint you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the URI prefix S3: // bucketName /, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend uses all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific articles. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing a lot of short documents, such as text messages. Possible values include:
•"ONE_DOC_PER_FILE"
•"ONE_DOC_PER_LINE"
oJobId (String): The identifier assigned to the PII entity discovery job.
oJobName (String): The name that you assigned to the PII entity discovery job.
oJobStatus (String): The current status of the PII entity discovery job. If the status is FAILED, the Message field shows the reason for the failure. Possible values include:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): The language code of the input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW"
oMessage (String): A description of the status of a job.
oMode (String): Specifies whether the output provides the locations (offsets) of the PII entities or a file in which the PII entities are redacted. Possible values include:
▪"ONLY_REDACTION"
▪"ONLY_OFFSETS"
oOutputDataConfig (Object): The output data settings that you provided when you created the PII entity discovery job.
▪S3Uri - obligatorio (String): When you use the PiiOutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data.
▪KmsKeyId - (String): ID of the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results of an analysis job.
oRedactionConfig (Object): Provides configuration parameters for redaction of PII entities. This parameter is required if you set the Mode parameter to ONLY_REDACTION. In that case, you need to provide a RedactionConfig definition that includes the PiiEntityTypes parameter.
▪PiiEntityTypes (Collection): An array of the PII entity types that Amazon Comprehend detects in the input text of your request.
▪MaskMode (String): Specifies whether the PII entity is censored with mask character or entity type. Possible values include:
•"MÁSCARA"
•"REPLACE_WITH_PII_ENTITY_TYPE"
▪MaskCharacter (String): A character that replaces each character in the redacted PII entity.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DescribePiiEntitiesDetectionJob.html.
List PII Entities Detection Jobs
Gets a list of the PII entity detection jobs that you have submitted.
To configure its inputs, take into account the following descriptions:
• Filter (Object): Filter the jobs that are returned. You can filter jobs by name, status, or the date and time they were submitted. You can only configure one filter at a time.
• JobName (String): Filter job name.
• JobStatus (String): Filter the list of jobs based on the status of the job. Returns only jobs with the specified status. Possible values include: "SUBMITTED", "IN_PROGRESS", "COMPLETED", "FAILED", "STOP_REQUESTED", and "STOPPED"
• SubmitTimeBefore (Date): Filters the list of jobs based on the time the job was submitted for processing. Returns only jobs submitted before the specified time. Jobs are returned in ascending order, from oldest to newest. Date format 'yyyy-MM-ddTHH:MM:ssZ' date example '2021-07-22T14:51:20Z'
• SubmitTimeAfter (Date): Filters the list of jobs based on the time the job was submitted for processing. Returns only jobs submitted after the specified time. Jobs are returned in descending order, from newest to oldest. Date format 'yyyy-MM-ddTHH:MM:ssZ' date example '2021-07-22T14:51:20Z'
• NextToken (String): Identify the next page of results to return.
• MaxResults (Integer): The maximum number of results to return on each page.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately. Take into account the following descriptions:
•PiiEntitiesDetectionJobPropertiesList - (Collection) Una lista que contiene las propiedades de cada job que se devuelve.
oDataAccessRoleArn (String): The Amazon Resource Name (ARN) that grants Amazon Comprehend read access to your input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (Date): The time the PII entity discovery job was submitted for processing.
oEndTime (Date): The time the PII entity discovery job completed.
oInputDataConfig (Object): The input properties for a PII entity discovery job.
▪S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in the same region as the API endpoint you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the URI prefix S3: // bucketName /, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend uses all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific articles. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing a lot of short documents, such as text messages. Possible values include:
•"ONE_DOC_PER_FILE"
•"ONE_DOC_PER_LINE"
oJobId (String): The identifier assigned to the PII entity discovery job.
oJobName (String): The name that you assigned to the PII entity discovery job.
oJobStatus (String): The current status of the PII entity discovery job. If the status is FAILED, the Message field shows the reason for the failure. Possible values include:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): The language code of the input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW"
oMessage (String): A description of the status of a job.
oMode (String): Specifies whether the output provides the locations (offsets) of the PII entities or a file in which the PII entities are redacted. Possible values include:
▪"ONLY_REDACTION"
▪"ONLY_OFFSETS"
oOutputDataConfig (Object): The output data settings that you provided when you created the PII entity discovery job.
▪S3Uri - obligatorio (String): When you use the PiiOutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data.
▪KmsKeyId - (String): ID of the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results of an analysis job.
oRedactionConfig (Object): Provides configuration parameters for redaction of PII entities. This parameter is required if you set the Mode parameter to ONLY_REDACTION. In that case, you need to provide a RedactionConfig definition that includes the PiiEntityTypes parameter.
▪PiiEntityTypes (Collection): An array of the PII entity types that Amazon Comprehend detects in the input text of your request.
▪MaskMode (String): Specifies whether the PII entity is censored with mask character or entity type. Possible values include:
•"MÁSCARA"
•"REPLACE_WITH_PII_ENTITY_TYPE"
▪MaskCharacter (String): A character that replaces each character in the redacted PII entity.
•NextToken - (String): Identify the next page of results to return.
•error (Object)
oerror (String): name of the error
omessage (String): description of the error
ostatus (Integer): code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_ListPiiEntitiesDetectionJobs.html.
Stop PII entities detection job
Stops a PII entities detection job in progress. If the status of a job is IN_PROGRESS the job will be marked for completion and its status will be updated to STOP_REQUESTED. If the job completes before it can be stopped, its status will be COMPLETED. When a job is stopped, all documents already processed are written to the output location.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier assigned to the PII entity discovery job.
•JobStatus (String): The current status of the PII entity discovery job. If the status is FAILED, the Message field shows the reason for the failure. Possible values include:
o"SUBMITTED"
o"IN_PROGRESS"
o"COMPLETED"
o"FAILED"
o"STOP_REQUESTED"
o"STOPPED"
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StopPiiEntitiesDetectionJob.html.
Start Entities Detection Job
Starts an asynchronous PII entity detection job for a collection of documents.
To configure its inputs, take into account the following descriptions:
• InputDataConfig (Object - Required): Specifies the format and location of the input data for the job. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (Required text): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the URI S3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend uses all of them as input. This parameter must be of type String in your Bizagi model.
o InputFormat (String): Specifies how the text in an input file should be processed: Possible values include:
▪"ONE_DOC_PER_FILE" and "ONE_DOC_PER_LINE"ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
▪ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
• OutputDataConfig (Object - Required): Specifies where to send the output files. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file. When the topic detection job is finished, the service creates an output file in a directory specific to the job. The S3Uri field contains the location of the output file, called output.tar.gz. It is a compressed archive that contains the ouput of the operation. This parameter must be of type String in your Bizagi model.
o KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job. The KmsKeyId can be one of the following formats:
▪KMS Key ID: "1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS Key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
▪KMS Key Alias: "alias/ExampleAlias"
▪ARN of a KMS Key Alias: "arn:aws:kms:us-west-2:111122223333:alias/ExampleAlias"
• DataAccessRoleArn (String - Required): The Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role that grants Amazon Comprehend read access to your input data. For more information, see https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
• JobName (String): The identifier of the job.
• EntityRecognizerArn (String): The Amazon Resource Name (ARN) that identifies the specific entity recognizer to be used by the StartEntitiesDetectionJob. This ARN is optional and is only used for a custom entity recognition job.
• LanguageCode (String - Required): The language of the input documents. All documents must be in the same language. You can specify any of the languages supported by Amazon Comprehend. If custom entities recognition is used, this parameter is ignored and the language used for training the model is used instead. Possible values include: "en", "es", "fr", "de", "it", "pt", "ar", "hi", "ja", "ko", "zh" and "zh-TW". This parameter must be of type String in your Bizagi model.
• ClientRequestToken (String): A unique identifier for the request. If you don't set the client request token, Amazon Comprehend generates one. If a token is not provided, the SDK will use a version 4 UUID.
• VolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. The VolumeKmsKeyId can be either of the following formats: KMS Key ID:
o"1234abcd-12ab-34cd-56ef-1234567890ab"
oAmazon Resource Name (ARN) of a KMS Key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"

To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId - (String): The identifier generated for the job.
•JobStatus (String): Status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values include:
oSUBMITTED : the job has been received and is queued for processing.
oIN_PROGRESS: Amazon Comprehend is processing the job.
oCOMPLETED: the job completed successfully and the output is available.
oFAILED: the job was not completed. For details, use the operation.
oSTOP_REQUESTED: Amazon Comprehend has received a stop request for work and is processing the request.
oSTOPPED: the job successfully stopped without completing.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StartPiiEntitiesDetectionJob.html.
Describe Entities Detection Job
Gets the properties associated with an entities detection job. Use this operation to get the status of a detection job.
To configure its inputs, take into account the following descriptions:
• JobId - (Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
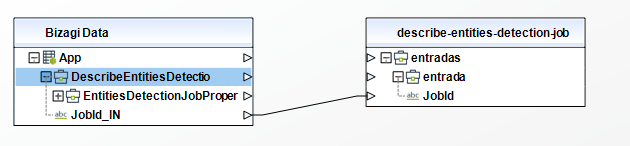
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•EntitiesDetectionJobPropertiesList - (Collection) collection with the properties of all the jobs that are returned.
oDataAccessRoleArn (String): The Amazon Resource Name (ARN) that grants Amazon Comprehend read access to your input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (Date): The time the PII entity discovery job was submitted for processing.
oEndTime (Date): The time the PII entity discovery job completed.
oInputDataConfig (Object): The input properties for a PII entity discovery job.
▪S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in the same region as the API endpoint you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the URI prefix S3: // bucketName /, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend uses all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific articles. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing a lot of short documents, such as text messages. Possible values include:
•"ONE_DOC_PER_FILE"
•"ONE_DOC_PER_LINE"
oJobId (String): The identifier assigned to the PII entity discovery job.
oJobName (String): The name that you assigned to the PII entity discovery job.
oJobStatus (String): The current status of the PII entity discovery job. If the status is FAILED, the Message field shows the reason for the failure. Possible values include:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): The language code of the input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW"
oMessage (String): A description of the status of a job.
oOutputDataConfig (Object): The output data settings that you provided when you created the PII entity discovery job.
▪S3Uri - obligatorio (String): When you use the PiiOutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data.
▪KmsKeyId - (String): ID of the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results of an analysis job.
oVpcConfig (Objeto): optional configuration parameters for a Virtual Private Cloud (VPC) that contains the resources that you are using for the topic discovery job. For more information, see https://docs.aws.amazon.com/en_us/vpc/latest/userguide/what-is-amazon-vpc.html.
▪ SecurityGroupIds (Colección - Requerido): ID number of a security group in an instance of your private VPC. VPC role security groups serve as a virtual firewall to control inbound and outbound traffic and provide security for the resources that you will access in the VPC. This identification number is preceded by "sg-", for example: "sg-03b388029b0a285ea". For more information, see https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html.
▪ Subnets (Colección - Requerido): The identifier for each subnet that is used in the private VPC. This subnet is a subset of the IPv4 address range used by the VPC and is specific to a particular Availability Zone in the VPC region. This identification number is preceded by "subnet-", for example: "subnet-04ccf456919e69055"
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DescribeEntitiesDetectionJob.html.
List Entities Detection Jobs
Gets a list of entity discovery jobs that you have submitted.
To configure its inputs, take into account the following descriptions:
• Filter (Object): Filter the jobs that are returned. You can filter jobs by name, status, or the date and time they were submitted. You can only configure one filter at a time.
• JobName (String): Filter job name.
• JobStatus (String): Filter the list of jobs based on the status of the job. Returns only jobs with the specified status. Possible values include: "SUBMITTED", "IN_PROGRESS", "COMPLETED", "FAILED", "STOP_REQUESTED" y "STOPPED".
• SubmitTimeBefore (Date): Filters the list of jobs based on the time the job was submitted for processing. Returns only jobs submitted before the specified time. Jobs are returned in ascending order, from oldest to newest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14: 51: 20Z'
• SubmitTimeAfter (Date): Filters the list of jobs based on the time the job was submitted for processing. Returns only jobs submitted after the specified time. Jobs are returned in descending order, from newest to oldest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14: 51: 20Z'
• NextToken (String): Identify the next page of results to return.
• MaxResults (Integer): The maximum number of results to return on each page.
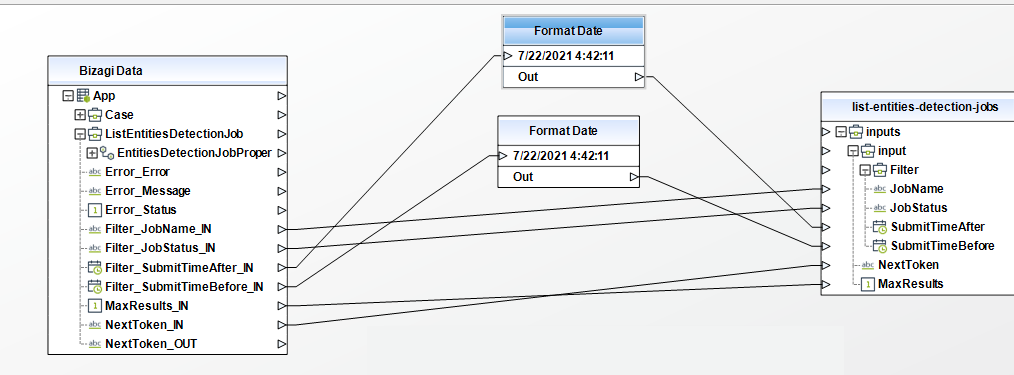
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•EntitiesDetectionJobPropertiesList - (Collection) collection with the properties of all the jobs that are returned.
oDataAccessRoleArn (String): The Amazon Resource Name (ARN) that grants Amazon Comprehend read access to your input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (Date): The time the PII entity discovery job was submitted for processing.
oEndTime (Date): The time the PII entity discovery job completed.
oInputDataConfig (Object): The input properties for a PII entity discovery job.
▪S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in the same region as the API endpoint you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the URI prefix S3: // bucketName /, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend uses all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific articles. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing a lot of short documents, such as text messages. Possible values include:
•"ONE_DOC_PER_FILE"
•"ONE_DOC_PER_LINE"
oJobId (String): The identifier assigned to the PII entity discovery job.
oJobName (String): The name that you assigned to the PII entity discovery job.
oJobStatus (String): The current status of the PII entity discovery job. If the status is FAILED, the Message field shows the reason for the failure. Possible values include:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): The language code of the input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW"
oMessage (String): A description of the status of a job.
oOutputDataConfig (Object): The output data settings that you provided when you created the PII entity discovery job.
▪S3Uri - obligatorio (String): When you use the PiiOutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data.
▪KmsKeyId - (String): ID of the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results of an analysis job.
oVolumeKmsKeyId (String): ID of the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the compute ML instances that process the scan job. VolumeKmsKeyId can have any of the following formats: KMS Key ID:
▪"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn: aws: kms: us-west-2: 111122223333: key / 1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (Objeto): optional configuration parameters for a Virtual Private Cloud (VPC) that contains the resources that you are using for the topic discovery job. For more information, see https://docs.aws.amazon.com/en_us/vpc/latest/userguide/what-is-amazon-vpc.html.
▪ SecurityGroupIds (Colección - Requerido): ID number of a security group in an instance of your private VPC. VPC role security groups serve as a virtual firewall to control inbound and outbound traffic and provide security for the resources that you will access in the VPC. This identification number is preceded by "sg-", for example: "sg-03b388029b0a285ea". For more information, see https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html.
▪ Subnets (Colección - Requerido): The identifier for each subnet that is used in the private VPC. This subnet is a subset of the IPv4 address range used by the VPC and is specific to a particular Availability Zone in the VPC region. This identification number is preceded by "subnet-", for example: "subnet-04ccf456919e69055"
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_ListEntitiesDetectionJobs.html.
Stop Entities Detection Job
Stops an entities detection job in progress. If the job state is IN_PROGRESS the job is marked for termination and put into the STOP_REQUESTED state. If the job completes before it can be stopped, it is put into the COMPLETED state; otherwise the job is stopped and put into the STOPPED state. When a job is stopped, any documents already processed are written to the output location.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
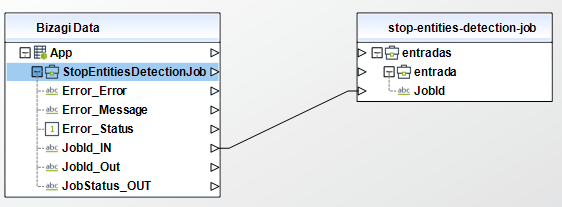
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier assigned to the PII entity discovery job.
•JobStatus (String): The current status of the PII entity discovery job. If the status is FAILED, the Message field shows the reason for the failure. Possible values include:
o"SUBMITTED"
o"IN_PROGRESS"
o"COMPLETED"
o"FAILED"
o"STOP_REQUESTED"
o"STOPPED"
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StopEntitiesDetectionJob.html.
Detect Sentiment
Inspects a text and returns an inference of the predominant sentiment. The possible sentiment values are: POSITIVE, NEUTRAL, NEGATIVE, or MIXED.
To configure its inputs, take into account the following descriptions:
• Text (String - Required): A UTF-8 text. Each Text must contain fewer that 5,000 bytes of UTF-8 encoded characters. This parameter must be of type String in your Bizagi model.
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en", "es", "fr", "de", "it", "pt", "ar", "hi", "ja", "ko", "zh", "zh-TW". This parameter must be of type String in your Bizagi model.
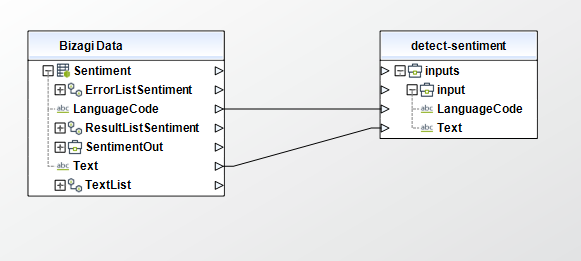
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•Sentiment (String): The inferred sentiment that Amazon Comprehend has the highest level of confidence in. Possible values include: "POSITIVE", "NEGATIVE", "NEUTRAL", "MIXED"
•SentimentScore (object): An object that lists the sentiments, and their corresponding confidence levels.
oPositive (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the POSITIVE sentiment.
oNegative (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the NEGATIVE sentiment.
oNeutral (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the NEUTRAL sentiment.
oMixed (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the MIXED sentiment.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectSentiment.html.
Batch Detect Sentiment
Inspects a batch of documents and returns an inference of the prevailing sentiment, POSITIVE, NEUTRAL, MIXED, or NEGATIVE, in each one.
To configure its inputs, take into account the following descriptions:
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en", "es", "fr", "de", "it", "pt", "ar", "hi", "ja", "ko", "zh", "zh-TW". This parameter must be of type String in your Bizagi model.
• TextList (Collection - Required): A list containing the text of the input documents. The list can contain a maximum of 25 documents. Each document must contain fewer that 5,000 bytes of UTF-8 encoded characters.
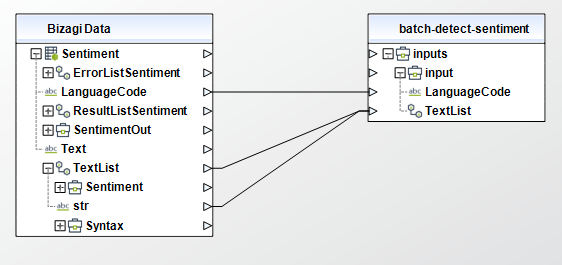
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•ResultList (Collection): A list of objects containing the results of the operation. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If all of the documents contain an error, the ResultList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oSentiment (String): The inferred sentiment that Amazon Comprehend has the highest level of confidence in. Possible values include: "POSITIVE", "NEGATIVE", "NEUTRAL", "MIXED"
oSentimentScore (object): An object that lists the sentiments, and their corresponding confidence levels.
▪Positive (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the POSITIVE sentiment.
▪Negative (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the NEGATIVE sentiment.
▪Neutral (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the NEUTRAL sentiment.
▪Mixed (String): The level of confidence that Amazon Comprehend has in the accuracy of its detection of the MIXED sentiment.
•ErrorList (Collection): A list containing one object for each document that contained an error. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If there are no errors in the batch, the ErrorList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oErrorCode (String): The numeric error code of the error.
oErrorMessage (String): A text description of the error.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_BatchDetectSentiment.html.
Detect Syntax
Inspects text for syntax and the part of speech of words in the document.
To configure its inputs, take into account the following descriptions:
• Text (String - Required): A UTF-8 text. Each Text must contain fewer that 5,000 bytes of UTF-8 encoded characters. This parameter must be of type String in your Bizagi model.
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en", "es", "fr", "de", "it", "pt". This parameter must be of type String in your Bizagi model.
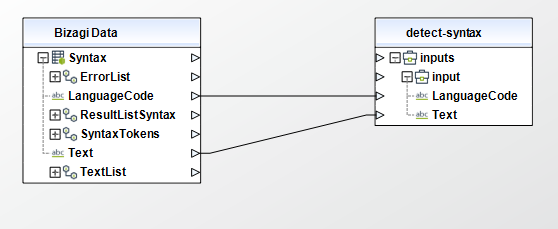
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•SyntaxTokens (array of object): A collection of syntax tokens describing the text. For each token, the response provides the text, the token type, where the text begins and ends, and the level of confidence that Amazon Comprehend has that the token is correct
oTokenId (integer): A unique identifier for a token.
oText (String): The word that was recognized in the source text.
oBeginOffset (integer): The zero-based offset from the beginning of the source text to the first character in the word.
oEndOffset (integer): The zero-based offset from the beginning of the source text to the last character in the word.
oPartOfSpeech (object): Provides the part of speech label and the confidence level that Amazon Comprehend has that the part of speech was correctly identified. For more information, see how-syntax.
▪Tag (String): Identifies the part of speech that the token represents.
▪Score (double): The confidence that Amazon Comprehend has that the part of speech was correctly identified.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectSyntax.html.
Batch Detect Syntax
Inspects the text of a batch of documents for the syntax and part of speech of the words in the document and returns information about them.
To configure its inputs, take into account the following descriptions:
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en", "es", "fr", "de", "it", "pt". This parameter must be of type String in your Bizagi model.
• TextList (Collection - Required): A list containing the text of the input documents. The list can contain a maximum of 25 documents. Each document must contain fewer that 5,000 bytes of UTF-8 encoded characters.
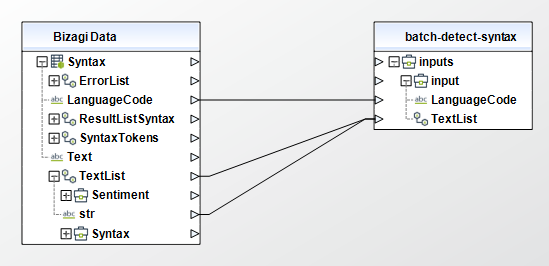
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•ResultList (Collection): A list of objects containing the results of the operation. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If all of the documents contain an error, the ResultList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oSyntaxTokens (Collection): A collection of syntax tokens describing the text. For each token, the response provides the text, the token type, where the text begins and ends, and the level of confidence that Amazon Comprehend has that the token is correct
▪TokenId (integer): A unique identifier for a token.
▪Text (String): The word that was recognized in the source text.
▪BeginOffset (integer): The zero-based offset from the beginning of the source text to the first character in the word.
▪EndOffset (integer): The zero-based offset from the beginning of the source text to the last character in the word.
▪PartOfSpeech (object): Provides the part of speech label and the confidence level that Amazon Comprehend has that the part of speech was correctly identified. For more information, see how-syntax.
•Tag (String): Identifies the part of speech that the token represents.
•Score (double): The confidence that Amazon Comprehend has that the part of speech was correctly identified.
•ErrorList (array of object): A list containing one object for each document that contained an error. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If there are no errors in the batch, the ErrorList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oErrorCode (String): The numeric error code of the error.
oErrorMessage (String): A text description of the error.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_BatchDetectSyntax.html.
Start Sentiment Detection Job
Starts an asynchronous sentiment detection job for a collection of documents.
To configure its inputs, take into account the following descriptions:
• DataAccessRoleArn (String - Required): The Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role that grants Amazon Comprehend read access to your input data. For more information, see https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions. This parameter must be of type String in your Bizagi model.
• InputDataConfig (Object - Required): Specifies the format and location of the input data for the job. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. This parameter must be of type String in your Bizagi model.
o InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
• LanguageCode (Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en","es","fr","de","it","pt","ar","hi","ja","ko","zh","zh-TW". This parameter must be of type String in your Bizagi model.
• OutputDataConfig (Object - Required): Specifies where to send the output files. This parameter must be an object in your Bizagi model.
o S3Uri (String - Required): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file. This parameter must be of type String in your Bizagi model.
o KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
• ClientRequestToken (String): A unique identifier for the request. If you don't set the client request token, Amazon Comprehend generates one. If a token is not provided, the connector will use a version 4 UUID.
• JobName (String): The identifier of the job.
• VolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job.
• VpcConfig (Object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your sentiment detection job. For more information, see Amazon VPC.
• SecurityGroupIds (Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
• Subnets (Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
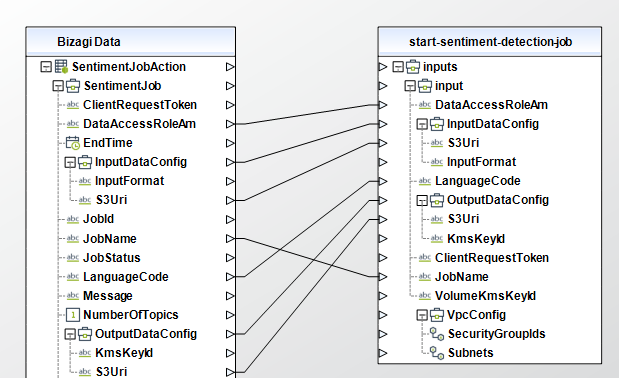
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier generated for the job. To get the status of a job, use this identifier with the operation.
•JobStatus (String): The status of the job.
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StartSentimentDetectionJob.html.
Describe Sentiment Detection Job
Gets the properties associated with a sentiment detection job. Use this operation to get the status of a detection job.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
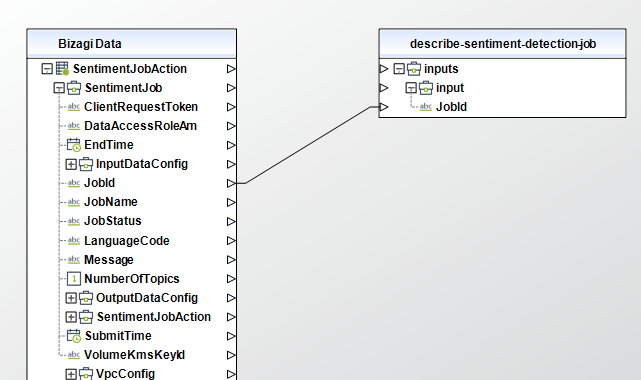
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•SentimentDetectionJobProperties (object): An object that contains the properties associated with a job.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3: // bucketName / prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): The status of the job.
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en","es","fr","de","it","pt","ar","hi","ja","ko","zh","zh-TW"
oMessage (String): A description of the status of a job.
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job. This parameter can have any of the following formats:
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job.
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key:"arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
▪SecurityGroupIds (Collection): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
▪Subnets (array of strings): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DescribeSentimentDetectionJob.html.
List Sentiment Detection Jobs
Gets a list of sentiment detection jobs that you have submitted.
To configure its inputs, take into account the following descriptions:
• Filter (Object): Filters the jobs that are returned. You can filter jobs on their name, status, or the date and time that they were submitted. You can only set one filter at a time.
• JobName (String): Filters on the name of the job.
• JobStatus (String): Filters the list of jobs based on job status. Returns only jobs with the specified status. Possible values include: "SUBMITTED", "IN_PROGRESS", "COMPLETED", "FAILED", "STOP_REQUESTED", "STOPPED"
• SubmitTimeBefore (Date): Filters the list of jobs based on the time that the job was submitted for processing. Returns only jobs submitted before the specified time. Jobs are returned in ascending order, oldest to newest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14: 51: 20Z'
• SubmitTimeAfter (Date): Filters the list of jobs based on the time that the job was submitted for processing. Returns only jobs submitted after the specified time. Jobs are returned in descending order, newest to oldest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14:51:20Z'
• MaxResults (Integer): The maximum number of results to return in each page. The default is 100.
• NextToken (String): Identifies the next page of results to return.
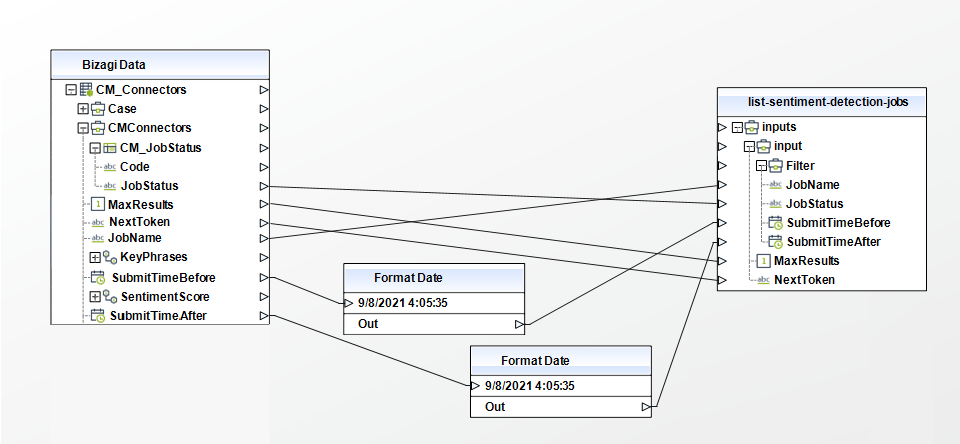
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•SentimentDetectionJobPropertiesList (Collection): A list containing the properties of each job that is returned.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en","es","fr","de","it","pt","ar","hi","ja","ko","zh","zh-TW"
oMessage (String): A description of the status of a job.
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
▪SecurityGroupIds (Collection): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
▪Subnets (Collection): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•NextToken (String): Identifies the next page of results to return.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_ListSentimentDetectionJobs.html.
Stop Sentiment Detection Job
Stops a sentiment detection job in progress. If the job state is IN_PROGRESS the job is marked for termination and put into the STOP_REQUESTED state. If the job completes before it can be stopped, it is put into the COMPLETED state; otherwise the job is be stopped and put into the STOPPED state. When a job is stopped, any documents already processed are written to the output location..
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
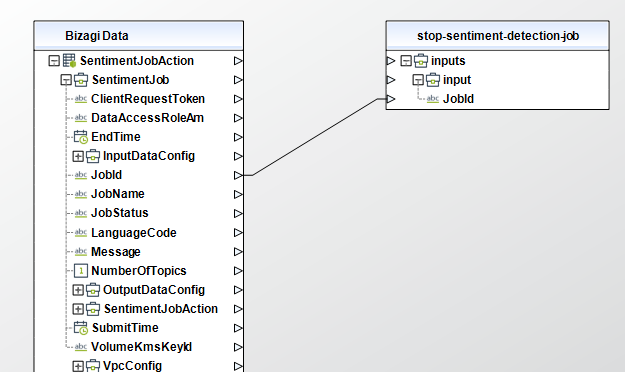
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier of the job.
•JobStatus (String): The status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StopSentimentDetectionJob.html.
Start Topics Detection Job
Starts an asynchronous topic detection job.
To configure its inputs, take into account the following descriptions:
• DataAccessRoleArn (String - Required): The Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role that grants Amazon Comprehend read access to your input data. For more information, see https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions. This parameter must be of type String in your Bizagi model.
• InputDataConfig (Object - Required): Specifies the format and location of the input data for the job. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. This parameter must be of type String in your Bizagi model.
o InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
• OutputDataConfig (Object - Required): Specifies where to send the output files. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file. This parameter must be of type String in your Bizagi model.
o KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
• ClientRequestToken (String): A unique identifier for the request. If you don't set the client request token, Amazon Comprehend generates one. If a token is not provided, the connector will use a version 4 UUID.
• JobName (String): The identifier of the job.
• NumberOfTopics (Integer): The number of topics to detect.
• VolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job.
• VpcConfig (Object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
• SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
• Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
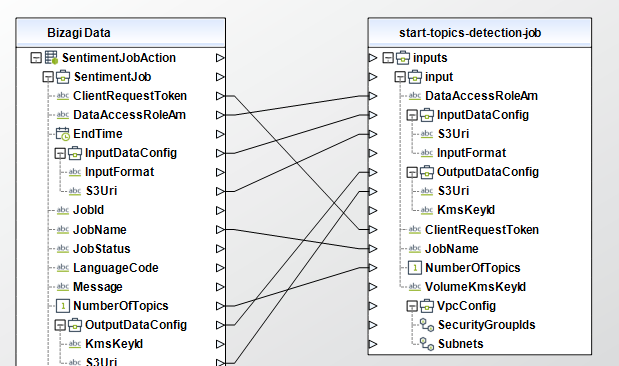
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier of the job.
•JobStatus (String): The status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StartTopicsDetectionJob.html.
Describe Topics Detection Job
Gets the properties associated with a topic detection job. Use this operation to get the status of a detection job.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
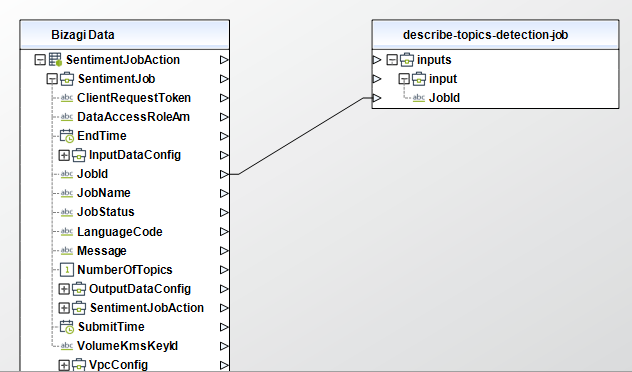
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•TopicsDetectionJobProperties (Objeto): Object with job properties.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oMessage (String): A description of the status of a job.
oNumberOfTopics (Integer): number of topics to detect
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
▪SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
▪Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DescribeTopicsDetectionJob.html.
List Topics Detection Jobs
Gets a list of the topic detection jobs that you have submitted.
To configure its inputs, take into account the following descriptions:
• Filter (Object): Filters the jobs that are returned. You can filter jobs on their name, status, or the date and time that they were submitted. You can only set one filter at a time.
• JobName (String): Filters on the name of the job.
• JobStatus (String): Filters the list of jobs based on job status. Returns only jobs with the specified status. Possible values include: "SUBMITTED", "IN_PROGRESS", "COMPLETED", "FAILED", "STOP_REQUESTED", "STOPPED"
• SubmitTimeBefore (Date): Filters the list of jobs based on the time that the job was submitted for processing. Returns only jobs submitted before the specified time. Jobs are returned in ascending order, oldest to newest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14: 51: 20Z'
• SubmitTimeAfter (Date): Filters the list of jobs based on the time that the job was submitted for processing. Returns only jobs submitted after the specified time. Jobs are returned in descending order, newest to oldest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14:51:20Z'
• MaxResults (Integer): The maximum number of results to return in each page. The default is 100.
• NextToken (String): Identifies the next page of results to return.
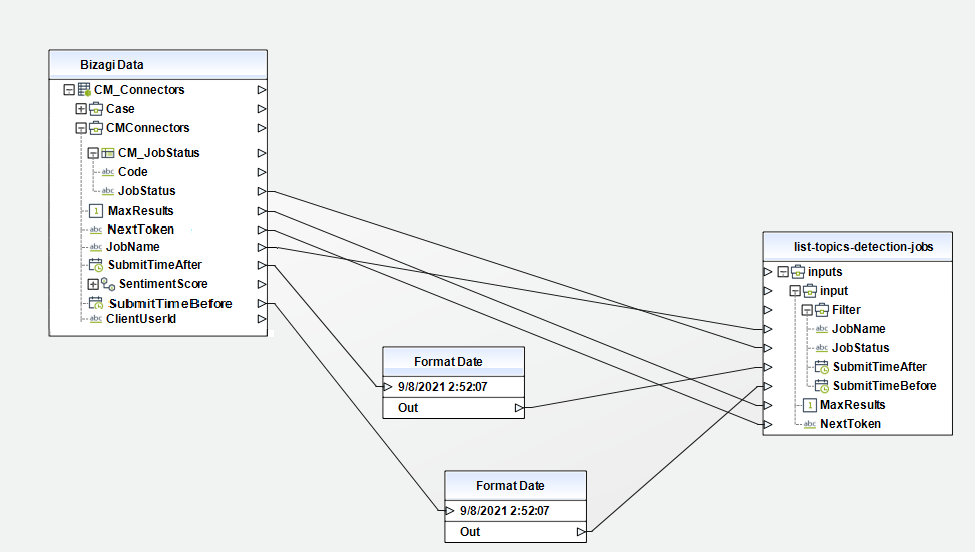
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•TopicsDetectionJobPropertiesList (Collection): A list containing the properties of each job that is returned.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oMessage (String): A description of the status of a job.
oNumberOfTopics (Integer): number of topics to detect
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
▪SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
▪Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•NextToken (String): Identifies the next page of results to return.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_ListTopicsDetectionJobs.html.
Detect Key Phrases
Detects the key noun phrases found in the text.
To configure its inputs, take into account the following descriptions:
• Text (String - Required): A UTF-8 text. Each Text must contain fewer that 5,000 bytes of UTF-8 encoded characters. This parameter must be of type String in your Bizagi model.
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en", "es", "fr", "de", "it", "pt", "ar", "hi", "ja", "ko", "zh", "zh-TW". This parameter must be of type String in your Bizagi model.

To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•KeyPhrases (Collection): A collection of key phrases that Amazon Comprehend identified in the input text. For each key phrase, the response provides the text of the key phrase, where the key phrase begins and ends, and the level of confidence that Amazon Comprehend has in the accuracy of the detection.
oBeginOffset (Integer): A character offset in the input text that shows where the key phrase begins (the first character is at position 0). The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character from a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
oEndOffset (Integer): A character offset in the input text where the key phrase ends. The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character from a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
oScore (Float): The level of confidence that Amazon Comprehend has in the accuracy of the detection.
oText (String): The text of a key noun phrase.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in en https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectKeyPhrases.html.
Batch Detect Key Phrases
Detects the key noun phrases found in a batch of documents.
To configure its inputs, take into account the following descriptions:
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en", "es", "fr", "de", "it", "pt", "ar", "hi", "ja", "ko", "zh", "zh-TW". This parameter must be of type String in your Bizagi model.
• TextList (Collection - Required): A list containing the text of the input documents. The list can contain a maximum of 25 documents. Each document must contain fewer that 5,000 bytes of UTF-8 encoded characters.
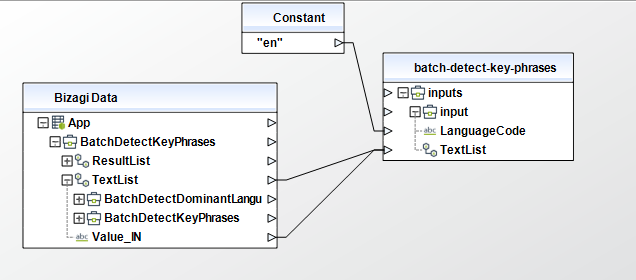
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•ResultList (Collection): A list of objects containing the results of the operation. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If all of the documents contain an error, the ResultList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oKeyPhrases (Collection): A collection of key phrases that Amazon Comprehend identified in the input text. For each key phrase, the response provides the text of the key phrase, where the key phrase begins and ends, and the level of confidence that Amazon Comprehend has in the accuracy of the detection.
▪BeginOffset (Integer): A character offset in the input text that shows where the key phrase begins (the first character is at position 0). The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character from a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
▪EndOffset (Integer): A character offset in the input text where the key phrase ends. The offset returns the position of each UTF-8 code point in the string. A code point is the abstract character from a particular graphical representation. For example, a multi-byte UTF-8 character maps to a single code point.
▪Score (Float): The level of confidence that Amazon Comprehend has in the accuracy of the detection.
▪Text (String): The text of a key noun phrase.
•ErrorList (Collection): A list containing one object for each document that contained an error. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If there are no errors in the batch, the ErrorList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oErrorCode (String): The numeric error code of the error.
oErrorMessage (String): A text description of the error.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_BatchDetectKeyPhrases.html.
Start Key Phrases Detection Job
Starts an asynchronous key phrase detection job for a collection of documents.
To configure its inputs, take into account the following descriptions:
• DataAccessRoleArn (String - Required): The Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role that grants Amazon Comprehend read access to your input data. For more information, see https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions. This parameter must be of type String in your Bizagi model.
• InputDataConfig (Object - Required): Specifies the format and location of the input data for the job. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. This parameter must be of type String in your Bizagi model.
o InputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
• LanguageCode (String - Required): The language of the input documents. You can specify any of the primary languages supported by Amazon Comprehend. All documents must be in the same language. Possible values include: "en","es","fr","de","it","pt","ar","hi","ja","ko","zh","zh-TW". This parameter must be of type String in your Bizagi model.
• OutputDataConfig (Object - Required): Specifies where to send the output files. Este parametro debe ser un objeto en su modelo de Bizagi.
o S3Uri (String - Required): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file. This parameter must be of type String in your Bizagi model.
o KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
• ClientRequestToken (String): A unique identifier for the request. If you don't set the client request token, Amazon Comprehend generates one. If a token is not provided, the connector will use a version 4 UUID.
• JobName (String): The identifier of the job.
• VolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job.
• VpcConfig (Object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your sentiment detection job. For more information, see Amazon VPC.
• SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
• Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
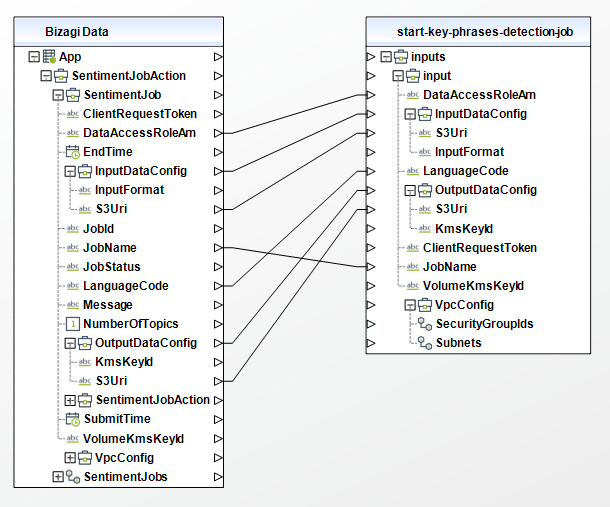
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier generated for the job. To get the status of a job, use this identifier with the operation.
•JobStatus (String): The status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StartKeyPhrasesDetectionJob.html.
Describe Key Phrases Detection Job
Gets the properties associated with a key phrases detection job. Use this operation to get the status of a detection job.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
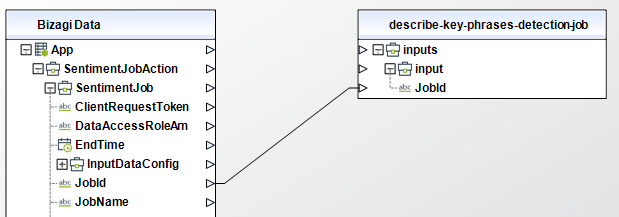
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
KeyPhrasesDetectionJobPropertiesList (object): An object that contains the properties associated with a job.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): language code for input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW".
oMessage (String): A description of the status of a job.
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
▪SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
▪Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DescribeKeyPhrasesDetectionJob.html.
List Key Phrases Detection Jobs
Get a list of key phrase detection jobs that you have submitted.
•Filter (Object): filters the jobs that are returned. You can filter jobs by name, status, or the date and time they were submitted. You can only configure one filter at a time.
• JobName (String): filter job name.
• JobStatus (String): Filters the job list based on job status. Returns only jobs with the specified status. Possible values include: "SUBMITTED", "IN_PROGRESS", "COMPLETED", "FAILED", "STOP_REQUESTED" y "STOPPED".
• SubmitTimeBefore (Date): filters the job list based on the time the job was submitted for processing. Returns only jobs submitted before the specified time. Jobs are returned in ascending order, oldest to newest. Date format 'yyyy-MM-ddTHH:MM:ssZ' date example '2021-07-22T14:51:20Z'
• SubmitTimeAfter (Date): filters the job list based on the time the job was submitted for processing. Returns only jobs submitted after the specified time. Jobs are returned in descending order, newest to oldest. Date format 'yyyy-MM-ddTHH:MM:ssZ' date example '2021-07-22T14:51:20Z'
• NextToken (String): identifies the next page of results to return.
• MaxResults (Integer): the maximum number of results to return on each page.
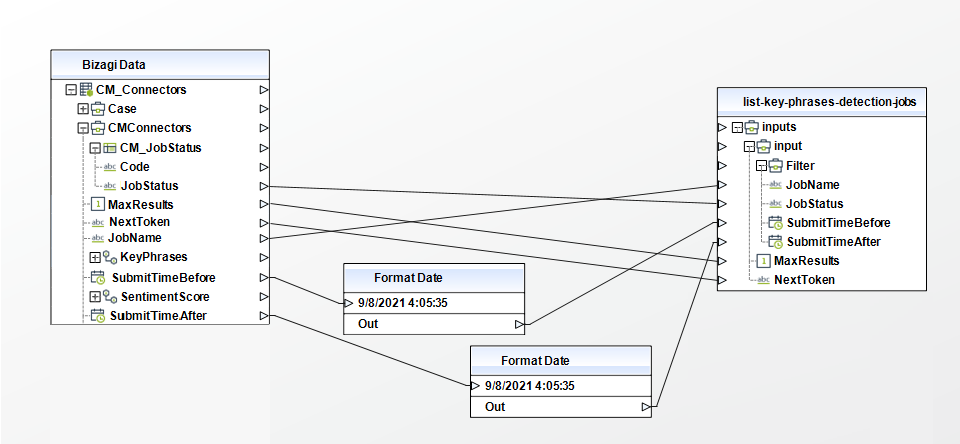
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•KeyPhrasesDetectionJobPropertiesList (Colección): collection with the properties of all the jobs that are returned.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): language code for input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW".
oMessage (String): A description of the status of a job.
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job. For more information, see https://docs.aws.amazon.com/en_us/vpc/latest/userguide/what-is-amazon-vpc.html
▪SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea". For more information, see https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
▪Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_ListKeyPhrasesDetectionJobs.html.
Stop Key Phrases Detection Job
Stops a key phrases detection job in progress. If the job state is IN_PROGRESS the job is marked for termination and put into the STOP_REQUESTED state. If the job completes before it can be stopped, it is put into the COMPLETED state; otherwise the job is stopped and put into the STOPPED state. When a job is stopped, any documents already processed are written to the output location.
To configure its inputs, take into account the following descriptions:
• JobId (Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
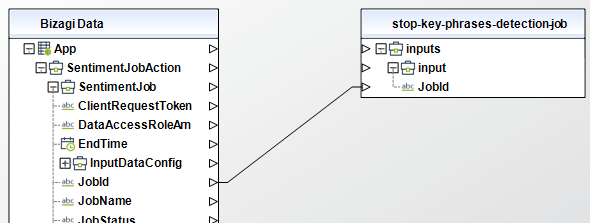
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier generated for the job. To get the status of a job, use this identifier with the operation.
•JobStatus (String): The status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StopKeyPhrasesDetectionJob.html.
Detect Dominant Language
Determines the dominant language of the input text. For a list of languages that Amazon Comprehend can detect, see https://docs.aws.amazon.com/comprehend/latest/dg/how-languages.html.
To configure its inputs, take into account the following descriptions:
• Text (String - Required): A UTF-8 text. Each Text must contain fewer that 5,000 bytes of UTF-8 encoded characters. This parameter must be of type String in your Bizagi model.
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•Languages (Collection) The languages that Amazon Comprehend detected in the input text. For each language, the response returns the RFC 5646 language code and the level of confidence that Amazon Comprehend has in the accuracy of its inference. For more information about RFC 5646, see Tags for Identifying Languages on the IETF Tools: https://datatracker.ietf.org/doc/html/rfc5646
oLanguageCode — (String) The RFC 5646 language code for the dominant language. For more information about RFC 5646, see Tags for Identifying Languages on the IETF Tools web site.
oScore (Float) The level of confidence that Amazon Comprehend has in the accuracy of the detection.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectDominantLanguage.html.
Batch Detect Dominant Language
Determines the dominant language of the input text for a batch of documents. For a list of languages that Amazon Comprehend can detect, see https://docs.aws.amazon.com/en_us/comprehend/latest/dg/how-languages.html.
To configure its inputs, take into account the following descriptions:
• TextList (Collection - Required): A list containing the text of the input documents. The list can contain a maximum of 25 documents. Each document must contain fewer that 5,000 bytes of UTF-8 encoded characters.
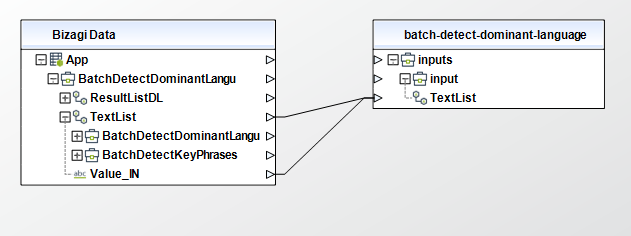
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•ResultList (Collectionea ): A list of objects containing the results of the operation. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If all of the documents contain an error, the ResultList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oLanguages (Collection): The languages that Amazon Comprehend detected in the input text. For each language, the response returns the RFC 5646 language code and the level of confidence that Amazon Comprehend has in the accuracy of its inference. For more information about RFC 5646, see Tags for Identifying Languages on the IETF Tools web site.
•LanguageCode (String): The RFC 5646 language code for the dominant language. For more information about RFC 5646, see Tags for Identifying Languages on the IETF Tools web site.
•Score (Float): The level of confidence that Amazon Comprehend has in the accuracy of the detection.
•ErrorList (array of object): A list containing one object for each document that contained an error. The results are sorted in ascending order by the Index field and match the order of the documents in the input list. If there are no errors in the batch, the ErrorList is empty.
oIndex (integer): The zero-based index of the document in the input list.
oErrorCode (String): The numeric error code of the error.
oErrorMessage (String): A text description of the error.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_BatchDetectDominantLanguage.html.
Start Dominant Language Detection Job
Starts an asynchronous dominant language detection job for a collection of documents.
To configure its inputs, take into account the following descriptions:
•DataAccessRoleArn (String - Required): The Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role that grants Amazon Comprehend read access to your input data. For more information, see https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions. This parameter must be of type String in your Bizagi model.
•InputDataConfig (Object - Required): Specifies the format and location of the input data for the job. This parameter must be an object in your Bizagi model.
oS3Uri (String - Required): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. This parameter must be of type String in your Bizagi model.
oInputFormat (String): Specifies how the text in an input file should be processed: ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers. ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
•OutputDataConfig (Object - Required): Specifies where to send the output files. This parameter must be an object in your Bizagi model.
oS3Uri (String - Required): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file. This parameter must be of type String in your Bizagi model.
oKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
•ClientRequestToken (String): A unique identifier for the request. If you don't set the client request token, Amazon Comprehend generates one. If a token is not provided, the connector will use a version 4 UUID.
•JobName (String): The identifier of the job.
•NumberOfTopics (Integer): The number of topics to detect.
•VolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job.
•VpcConfig (Object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job.
•SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea".
•Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier generated for the job. To get the status of a job, use this identifier with the operation.
•JobStatus (String): The status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StartDominantLanguageDetectionJob.html.
Describe Dominant Language Detection Job
Gets the properties associated with a dominant language detection job. Use this operation to get the status of a detection job.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
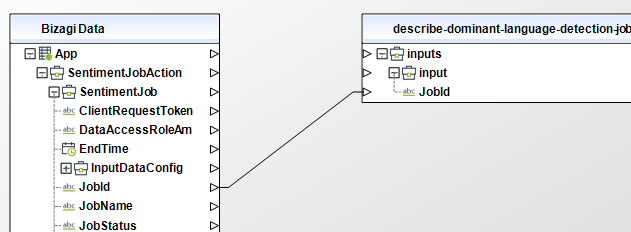
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•DominantLanguageDetectionJobProperties (Collection): collection with the properties of all the jobs that are returned.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): language code for input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW".
oMessage (String): A description of the status of a job.
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job. For more information, see https://docs.aws.amazon.com/en_us/vpc/latest/userguide/what-is-amazon-vpc.html
▪SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea". For more information, see https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
▪Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_DescribeDominantLanguageDetectionJob.html.
List Dominant Language Detection Jobs
Gets a list of the dominant language detection jobs that you have submitted.
To configure its inputs, take into account the following descriptions:
• Filter (Object): Filters the jobs that are returned. You can filter jobs on their name, status, or the date and time that they were submitted. You can only set one filter at a time.
• JobName (String): Filters on the name of the job.
• JobStatus (String): Filters the list of jobs based on job status. Returns only jobs with the specified status. Possible values include: "SUBMITTED", "IN_PROGRESS", "COMPLETED", "FAILED", "STOP_REQUESTED", "STOPPED"
• SubmitTimeBefore (Date): Filters the list of jobs based on the time that the job was submitted for processing. Returns only jobs submitted before the specified time. Jobs are returned in ascending order, oldest to newest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14: 51: 20Z'
• SubmitTimeAfter (Date): Filters the list of jobs based on the time that the job was submitted for processing. Returns only jobs submitted after the specified time. Jobs are returned in descending order, newest to oldest. Date format 'yyyy-MM-ddTHH:MM:ssZ' example date '2021-07-22T14:51:20Z'
•NextToken (String): Identifies the next page of results to return.
•MaxResults (Integer): The maximum number of results to return in each page. The default is 100.
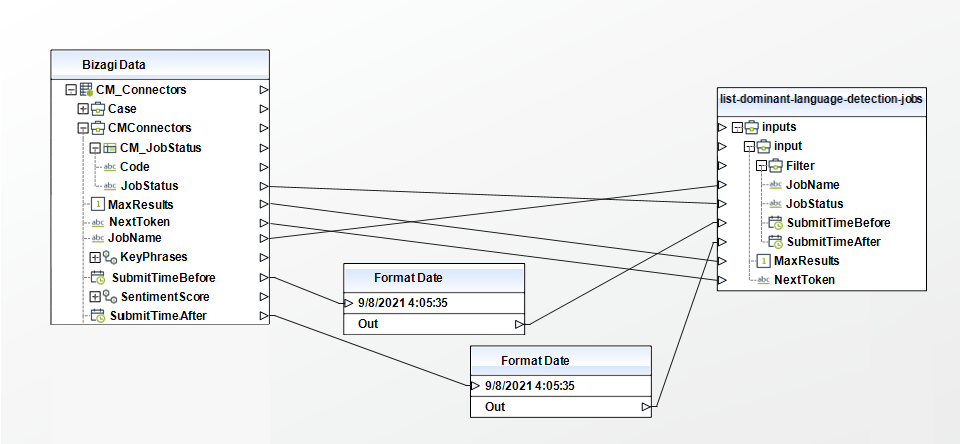
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•DominantLanguageDetectionJobProperties (Collection): collection with the properties of all the jobs that are returned.
oDataAccessRoleArn (String): the Amazon Resource Name (ARN) that provides read permissions to Amazon Comprehend of the input data. For more information, go to https://docs.aws.amazon.com/comprehend/latest/dg/access-control-managing-permissions.html#auth-role-permissions.
oSubmitTime (date): The time that the job was submitted for processing.
oEndTime (date): The time that the job ended.
oInputDataConfig (object): Specifies the format and location of the input data for the job.
▪S3Uri (String): The Amazon S3 URI for the input data. The URI must be in same region as the API endpoint that you are calling. The URI can point to a single input file or it can provide the prefix for a collection of data files. For example, if you use the prefix URIS3://bucketName/prefix, if the prefix is a single file, Amazon Comprehend uses that file as input. If more than one file begins with the prefix, Amazon Comprehend will use all of them as input.
▪InputFormat (String): Specifies how the text in an input file should be processed:
•ONE_DOC_PER_FILE - Each file is considered a separate document. Use this option when you are processing large documents, such as newspaper articles or scientific papers.
•ONE_DOC_PER_LINE - Each line in a file is considered a separate document. Use this option when you are processing many short documents, such as text messages.
oJobId (String): The identifier assigned to the job.
oJobName (String): The name that you assigned to the job
oJobStatus (String): current state of feeling detection work. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
▪"SUBMITTED"
▪"IN_PROGRESS"
▪"COMPLETED"
▪"FAILED"
▪"STOP_REQUESTED"
▪"STOPPED"
oLanguageCode (String): language code for input documents. Possible values include: "en""es""fr""de""it""pt""ar""hi""ja""ko""zh""zh-TW".
oMessage (String): A description of the status of a job.
oOutputDataConfig (object): Specifies where to send the output files.
▪S3Uri (String): When you use the OutputDataConfig object with asynchronous operations, you specify the Amazon S3 location where you want to write the output data. The URI must be in the same region as the API endpoint that you are calling. The location is used as the prefix for the actual location of the output file.
▪KmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt the output results from an analysis job.
oVolumeKmsKeyId (String): ID for the AWS Key Management Service (KMS) key that Amazon Comprehend uses to encrypt data on the storage volume attached to the ML compute instance(s) that process the analysis job. This parameter can be in any of the following formats:
▪:"1234abcd-12ab-34cd-56ef-1234567890ab"
▪Amazon Resource Name (ARN) of a KMS key: "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab"
oVpcConfig (object): Configuration parameters for an optional private Virtual Private Cloud (VPC) containing the resources you are using for your job. For more information, see https://docs.aws.amazon.com/en_us/vpc/latest/userguide/what-is-amazon-vpc.html
▪SecurityGroupIds (Collection - Required): The ID number for a security group on an instance of your private VPC. Security groups on your VPC function serve as a virtual firewall to control inbound and outbound traffic and provides security for the resources that you’ll be accessing on the VPC. This ID number is preceded by "sg-", for instance: "sg-03b388029b0a285ea". For more information, see https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
▪Subnets (Collection - Required): The ID for each subnet being used in your private VPC. This subnet is a subset of the a range of IPv4 addresses used by the VPC and is specific to a given availability zone in the VPC’s region. This ID number is preceded by "subnet-", for instance: "subnet-04ccf456919e69055".
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_ListDominantLanguageDetectionJobs.html.
Stop Dominant Language Detection Jobs
Stops a dominant language detection job in progress. If the job state is IN_PROGRESS the job is marked for termination and put into the STOP_REQUESTED state. If the job completes before it can be stopped, it is put into the COMPLETED state; otherwise the job is stopped and put into the STOPPED state. When a job is stopped, any documents already processed are written to the output location.
To configure its inputs, take into account the following descriptions:
• JobId (String - Required): The identifier that Amazon Comprehend generated for the job. The operation returns this identifier in its response. This parameter must be of type String in your Bizagi model.
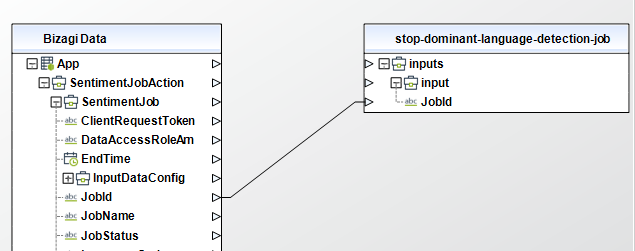
To configure the outputs of this action, you can map the output object to the corresponding entity in Bizagi and make sure you map the attributes of the entity appropriately.
To configure its outputs, take into account the following descriptions:
•JobId (String): The identifier generated for the job. To get the status of a job, use this identifier with the operation.
•JobStatus (String): The status of the job. If the job status is FAILED, the message field shows the cause for the failure. Possible values are:
o"SUBMITTED" - The job has been received and is queued for processing.
o"IN_PROGRESS" - Amazon Comprehend is processing the job.
o"COMPLETED" - The job was successfully completed and the output is available.
o"FAILED" - The job did not complete. To get details, use the operation.
o"STOP_REQUESTED" - Amazon Comprehend received a stop job request and the request is being processed.
o"STOPPED": The job has been stopped before its completion.
•error (Object)
oerror (String): Name of the error
omessage (String): Description of the error
ostatus (Integer): Code of the error
For more information about this method's use, refer to Amazon Comprehend's official documentation in https://docs.aws.amazon.com/comprehend/latest/dg/API_StopDominantLanguageDetectionJob.html.
Last Updated 12/10/2025 3:09:13 PM