Introducción
El conector Text Analytics con el respaldo de Microsoft Cognitive Services para Bizagi está disponible para su descarga en el Connectors XChange de Bizagi.
A través de este conector, podrá conectar sus procesos de Bizagi a su cuenta y servicios de Microsoft Azure Cognitive Services. Esto significa que puede detectar idiomas, identificar entidades, generar enlaces para obtener más información sobre dichas entidades, reconocer entidades y frases clave (key phrases) conocidas, así como identificar el sentimiento de un texto directamente desde Bizagi.
Para más información sobre las capacidades de este conector, visite nuestro Connectors XChange
|
Este Conector se desarrolló de acuerdo con los contenidos del API o información sobre los mismos suministrada por Microsoft Cognitive Services. Bizagi no se hace responsable por errores derivados del llamado de los servicios del API, incongruencias en la documentación presentada por Azure. Ni Bizagi ni sus filiales serán responsables de ofrecer cualquier tipo de garantía sobre los contenidos o errores derivados del llamado de los servicios del API. Bizagi y sus filiales no se harán responsables de las pérdidas, los costos o los daños en los que se incurra como consecuencia del acceso o el uso de los servicios del API de Microsoft Cognitive Services. |
Antes de iniciar
Para probar y utilizar este conector, necesitará:
1.Bizagi Studio previamente instalado.
2.Este conector previamente instalado, a través del Connectors Xchange como se describe en la documentación de Connectors Xchange, o a través de una instalación manual como se describe en la documentación de Instalar y administrar conectores.
3.Agregar Azure AI services a su suscripción de Azure.
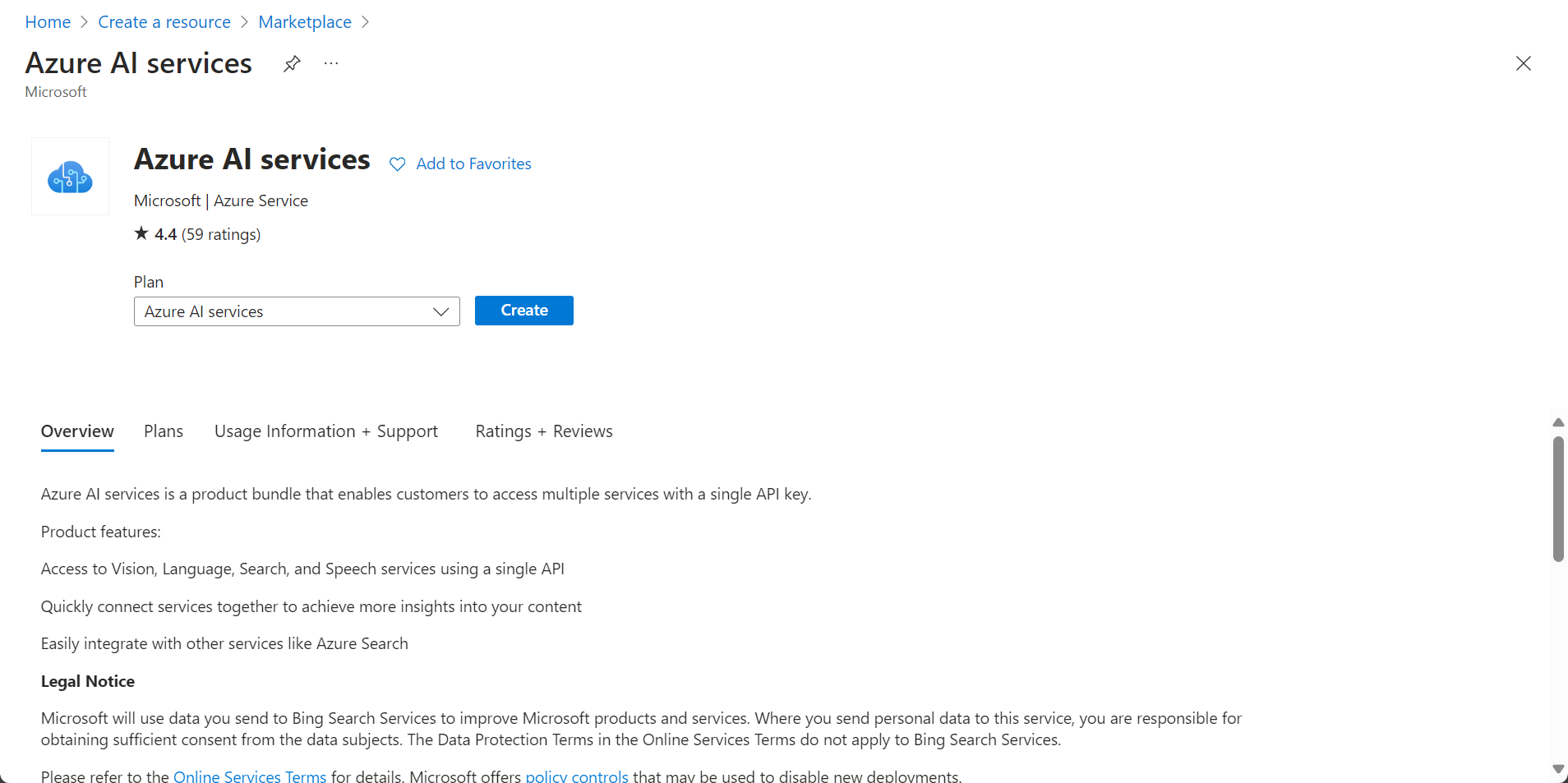
Configuración de Servicios de Azure AI
Para configurar Azure AI, siga estos pasos:
1.Cree el nuevo servicio: Vaya al Portal de Azure y haga clic en el botón Crear un recurso.
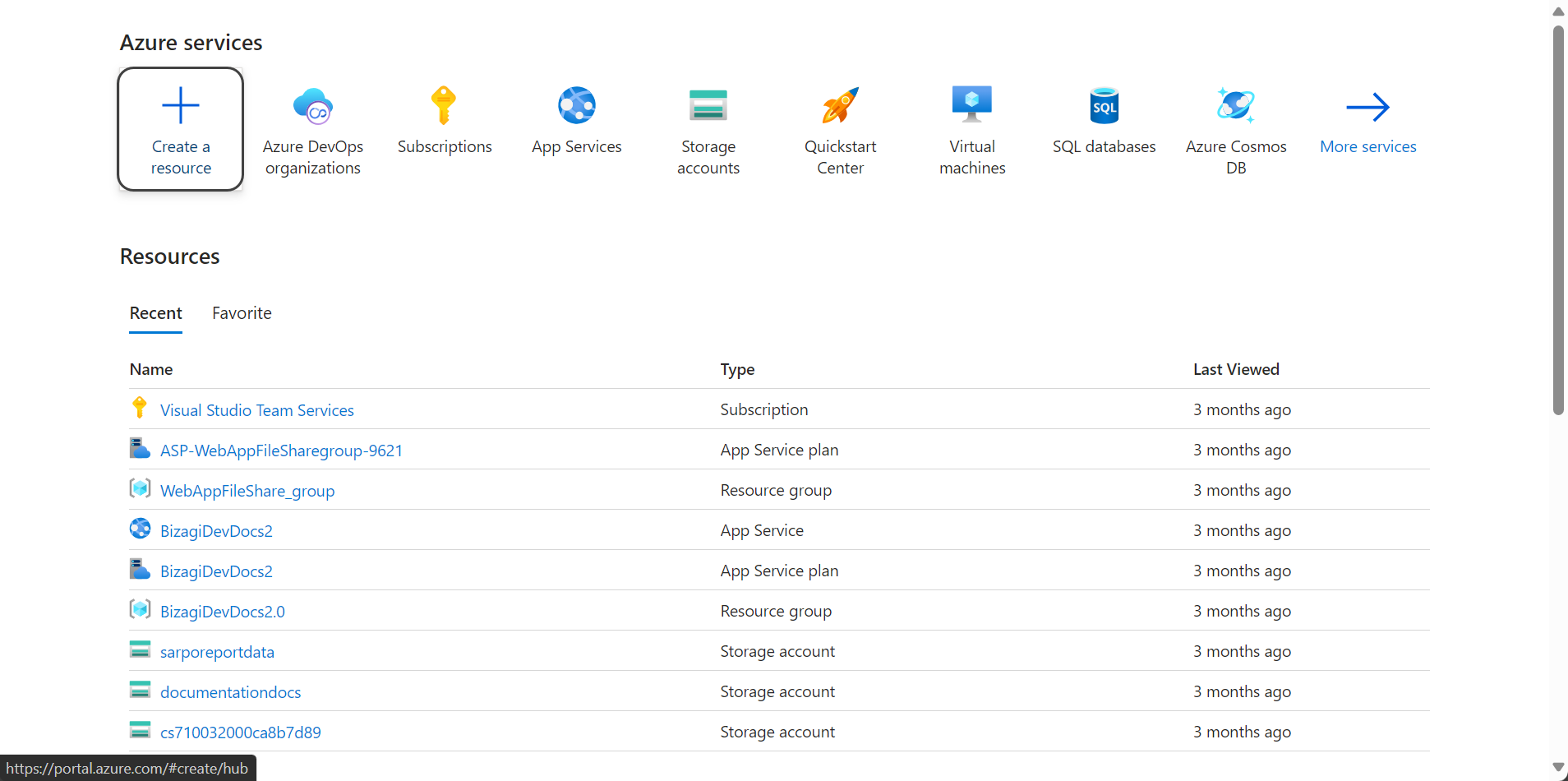
2.Busque "Servicios de Azure AI": Encuentre y seleccione la opción con el logo azul, como se muestra en la siguiente imagen.
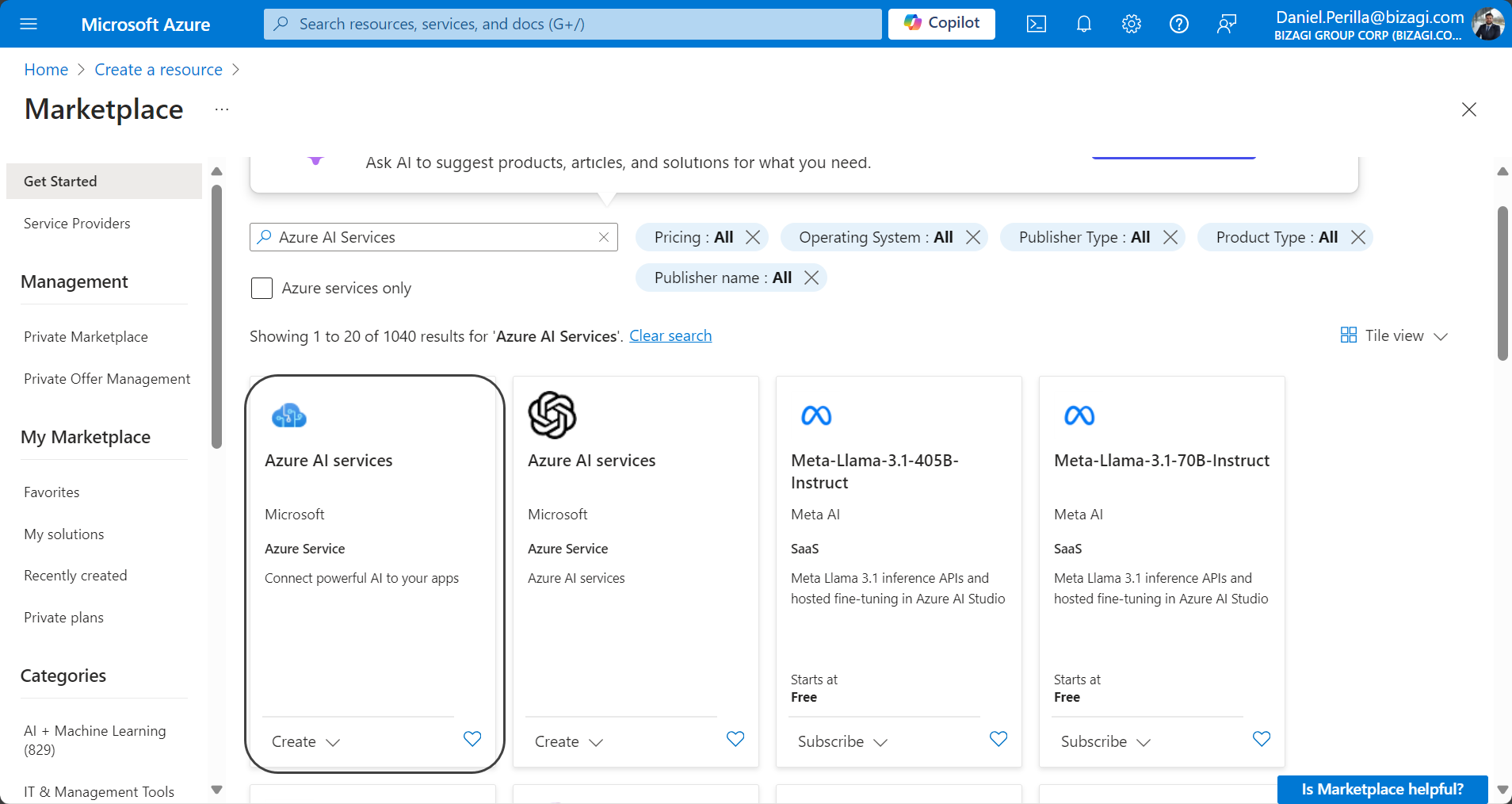
3.Seleccione el plan que mejor se adapte a sus necesidades según las opciones listadas en el menú desplegable Plan, y haga clic en Crear.
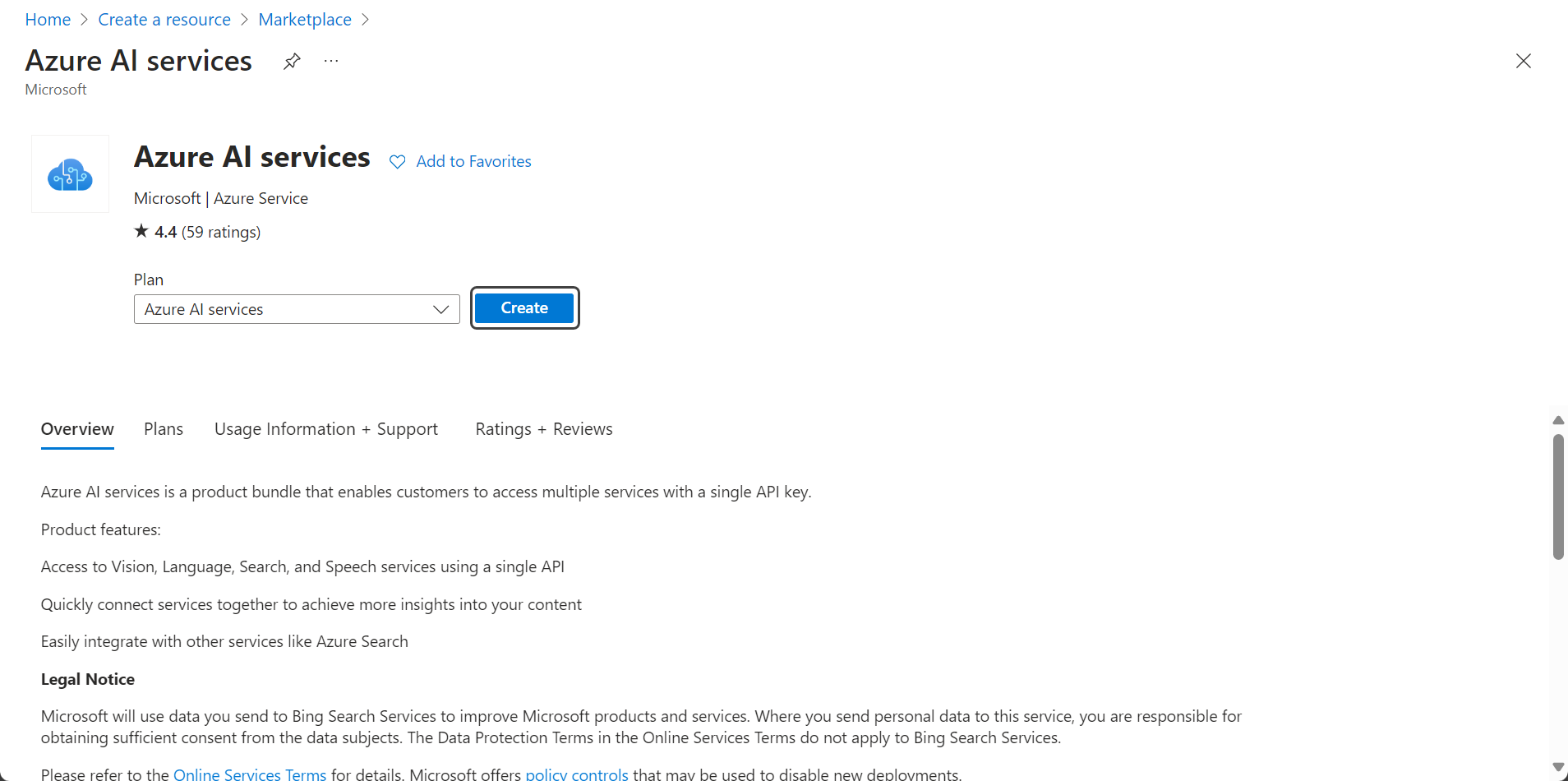
4.Luego, configure el nuevo servicio: Configúrelo de acuerdo a sus preferencias. Tenga en cuenta que el valor que defina en el cuadro de texto Nombre es el valor que necesitará usar en la propiedad de configuración "SERVICE_NAME". Rellene los campos requeridos y haga clic en el botón Revisar + crear.
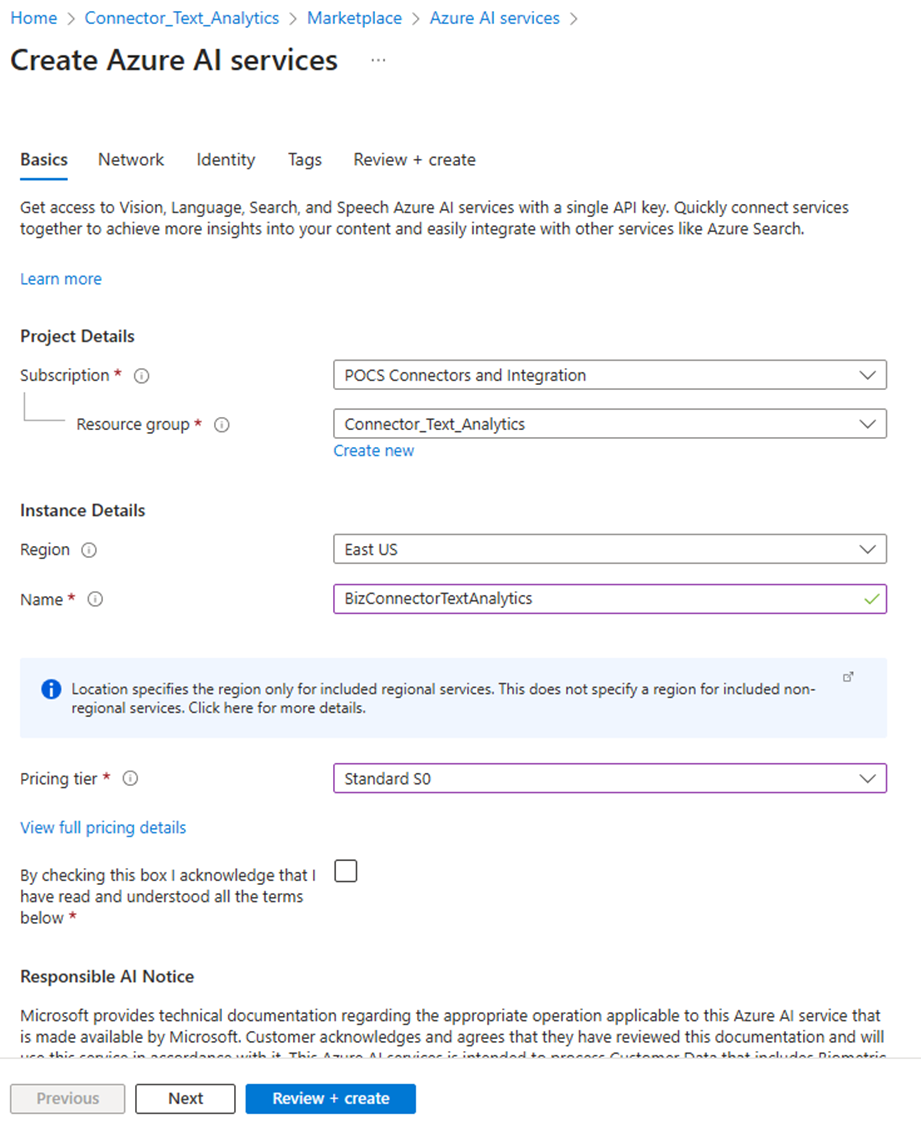
5.Haga clic en el botón Crear.
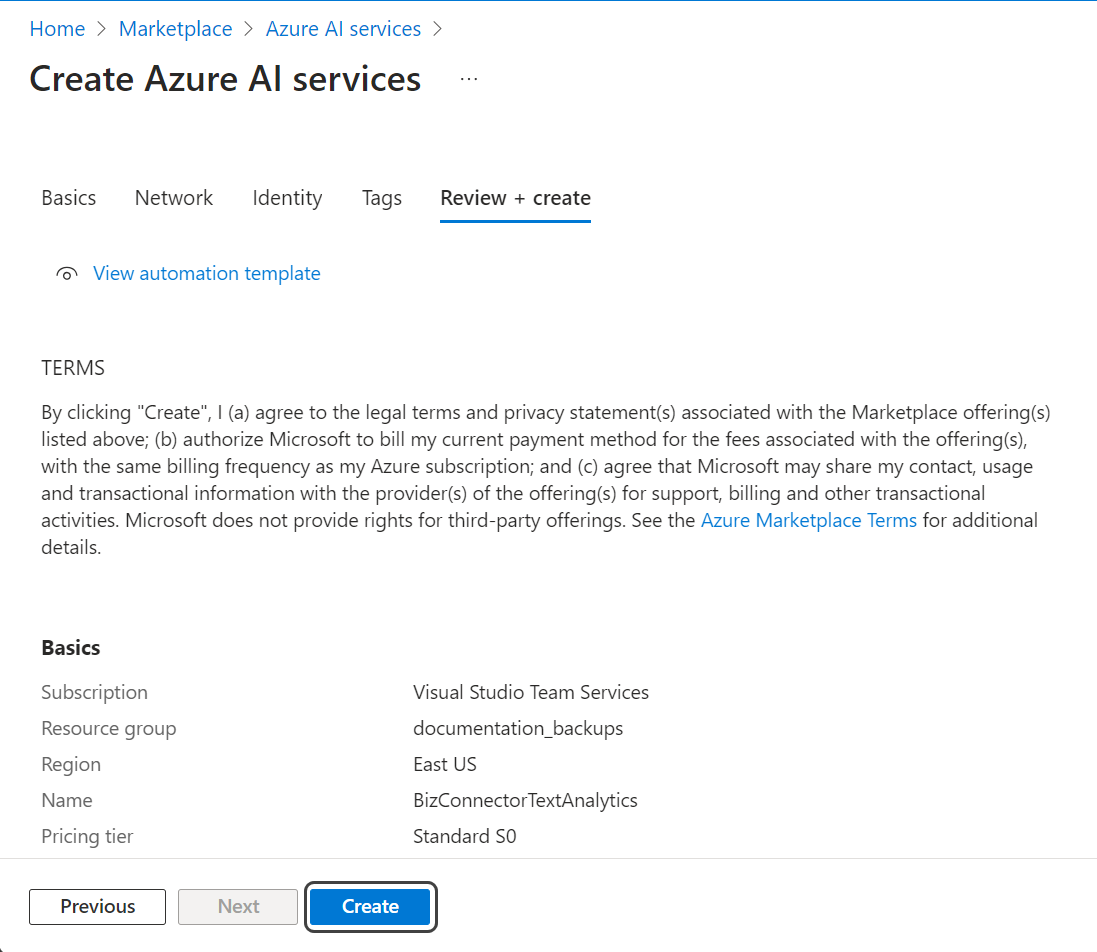
6. Será automáticamente dirigido a la página de detalles de la implementación. Bajo el título Próximos pasos, haga clic en el botón Ir al recurso.
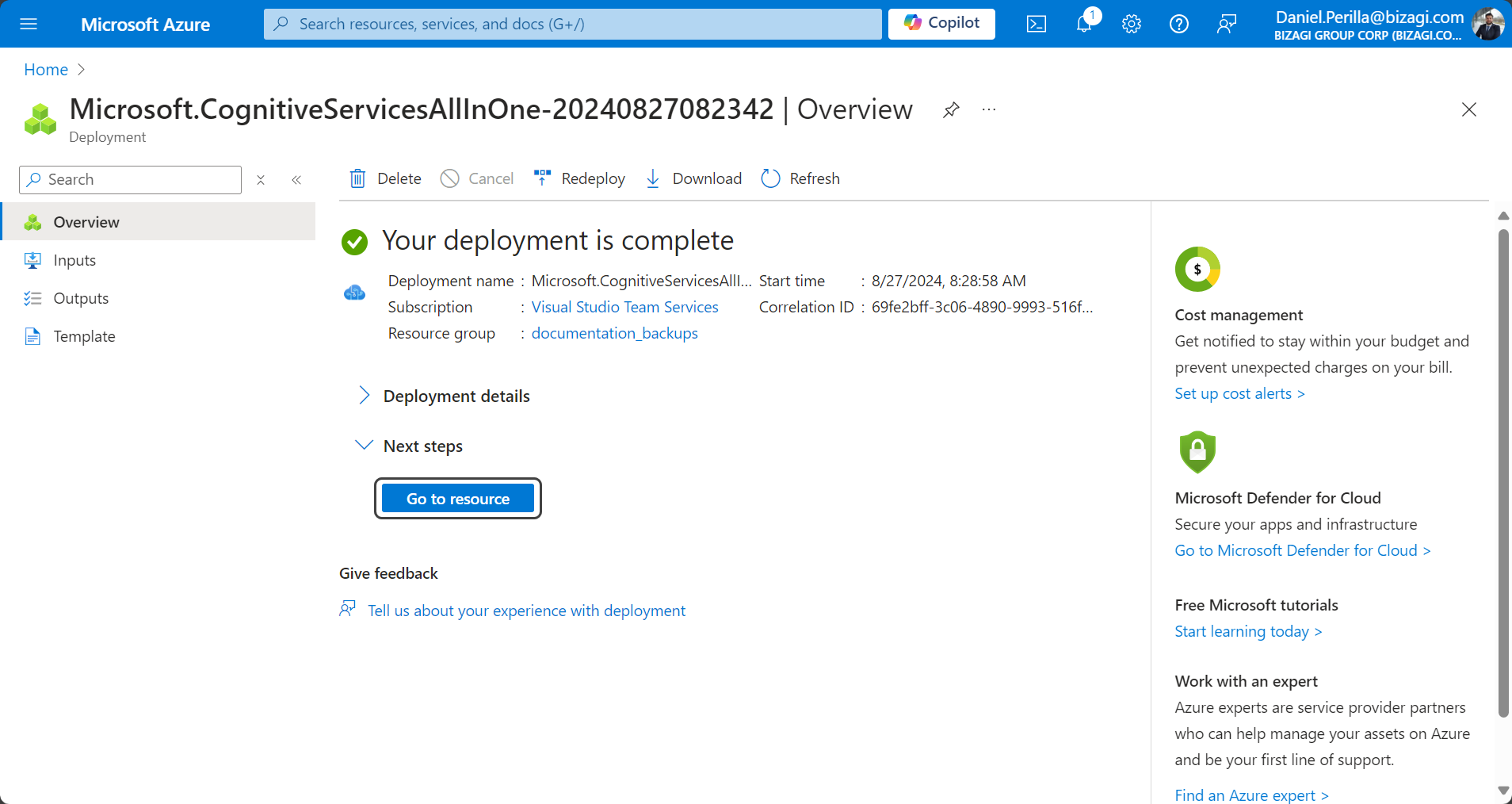
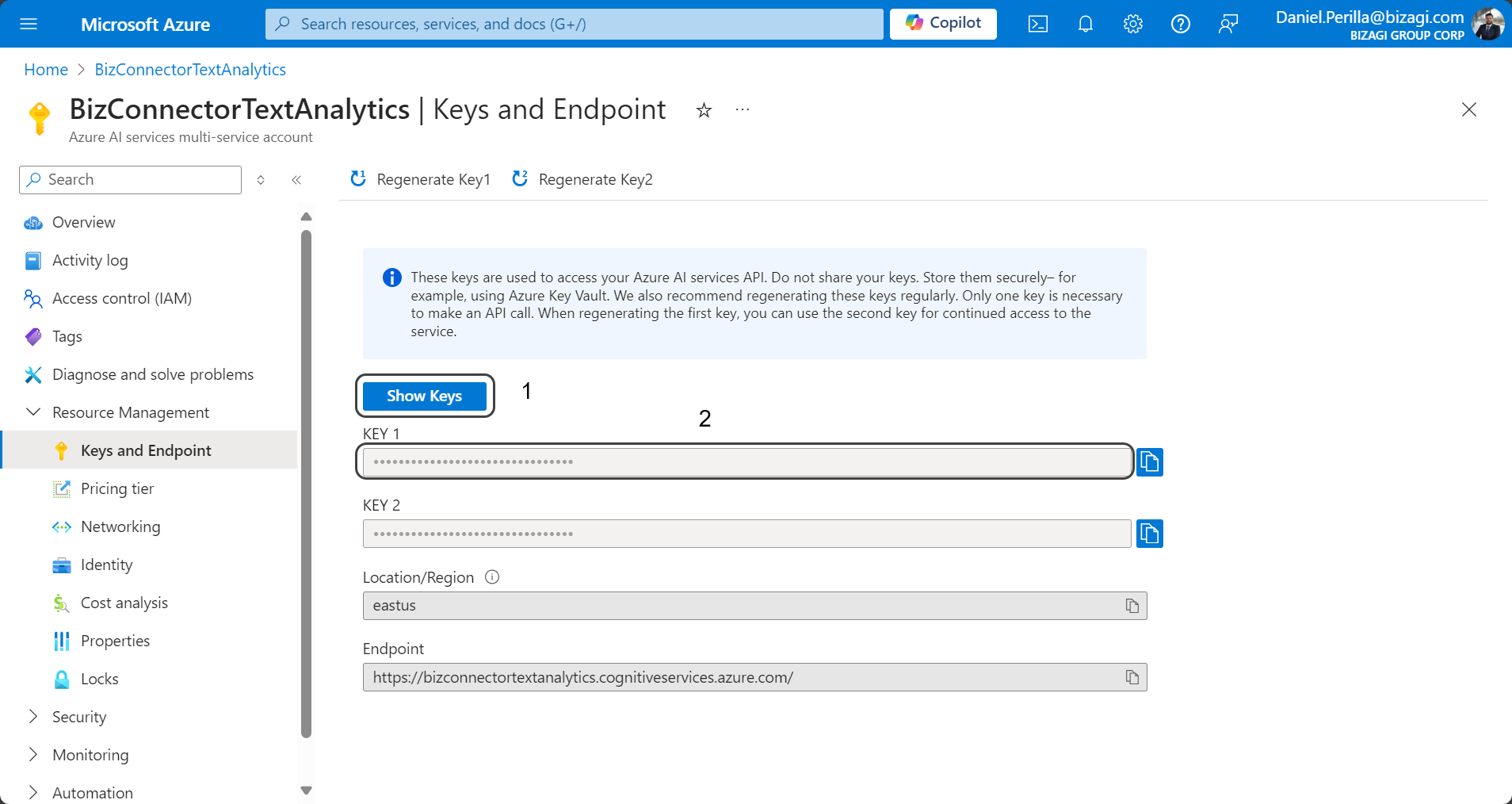
7.Bajo el subtítulo Administrar claves, haga clic en la frase subrayada Haga clic aquí para administrar claves.
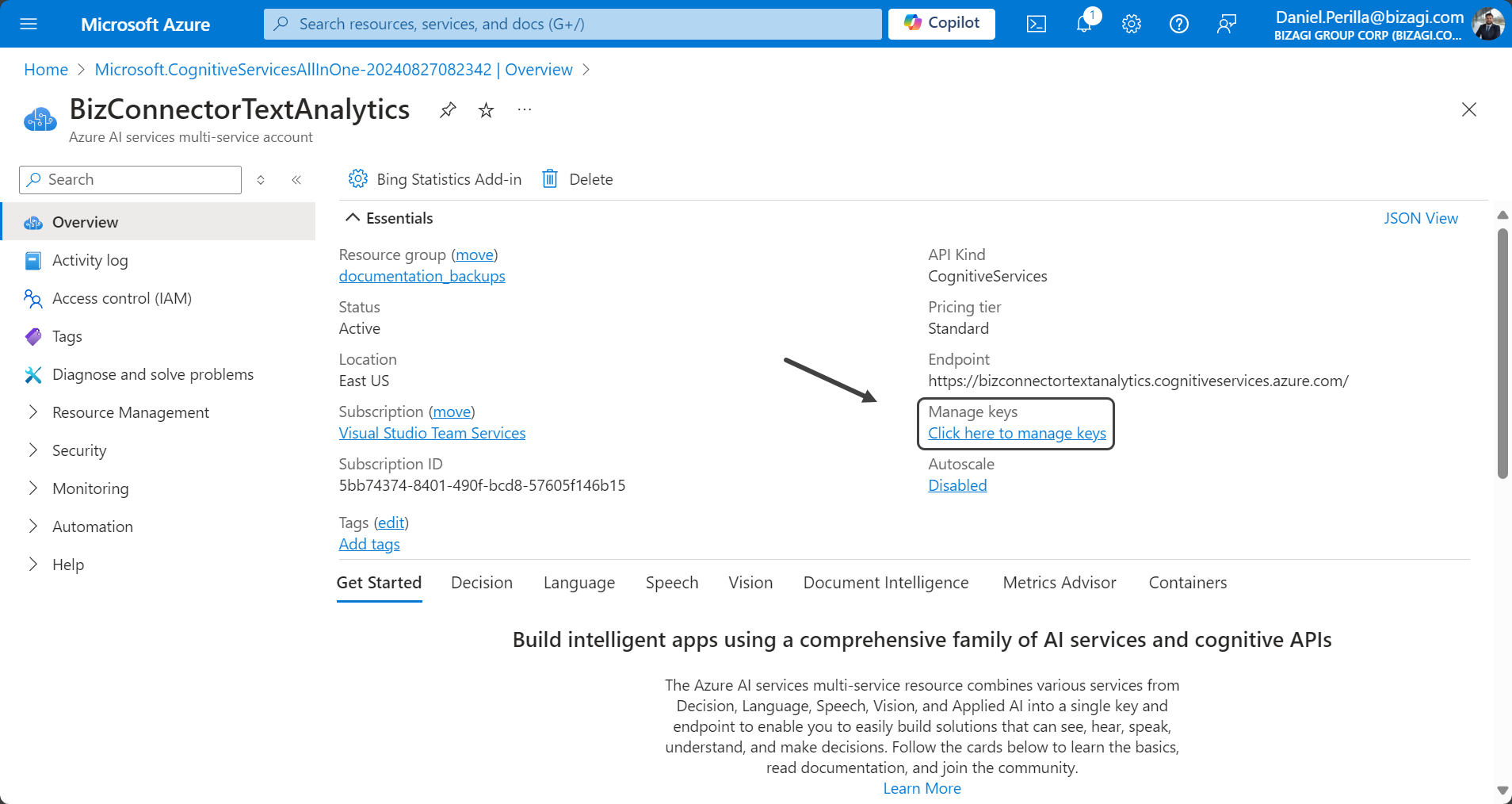
8.En la sección Claves y Punto de conexión, recupere el valor del campo CLAVE 1, que necesitará usar en la propiedad SUBSCRIPTION_KEY en la configuración de autenticación del conector.
Configurar el conector
Para configurar el conector (en particular sus parámetros de autenticación), siga los pasos presentados en el capítulo de Configuración en la documentación de Instalar y administrar conectores.
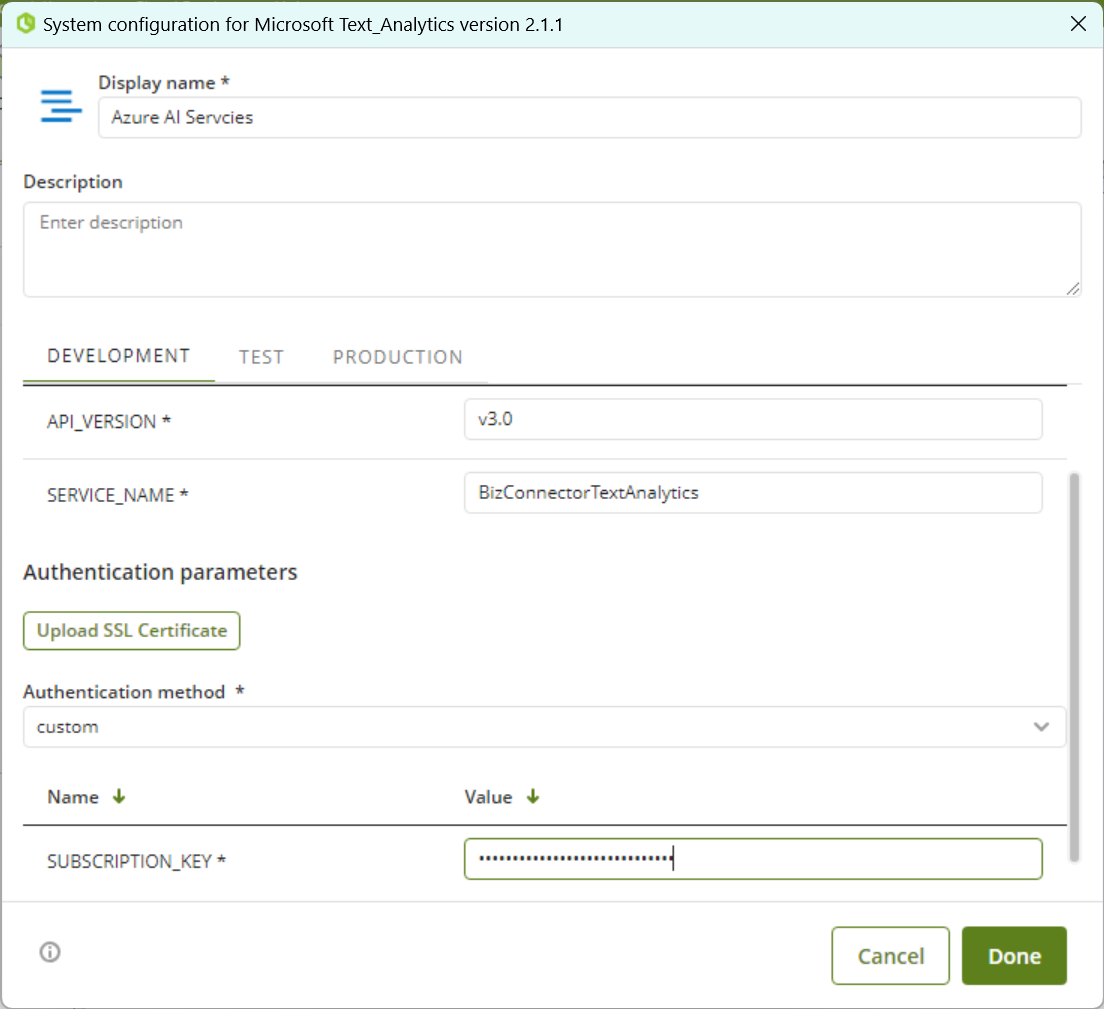
Para esta configuración, considere los siguientes parámetros de autenticación:
•SERVICE_NAME: El nombre del servicio configurado en las instrucciones de Configuración de Servicios de Azure AI.
•API_Version: v3.0
•Método de autenticación: Custom (personalizado)
•Subscription_key: La clave de Cognitive Services (CLAVE 1 copiada en el último paso de las instrucciones de Configuración de Servicios de Azure AI).
La configuración del Conector debe ser como la siguiente:
Usar el conector
Este conector cuenta con un conjunto de métodos que le permiten utilizar los servicios API de Azure Text Analytics para aprovechar sus capacidades.
Para conocer en general cómo/donde configurar el uso de un conector, consulte la documentación de Utilizar conectores.
Al usar el conector, tenga en cuenta que puede necesitar configurar entradas o salidas. Las siguientes imágenes muestran ejemplos de cómo mapear las entradas o salidas de un método
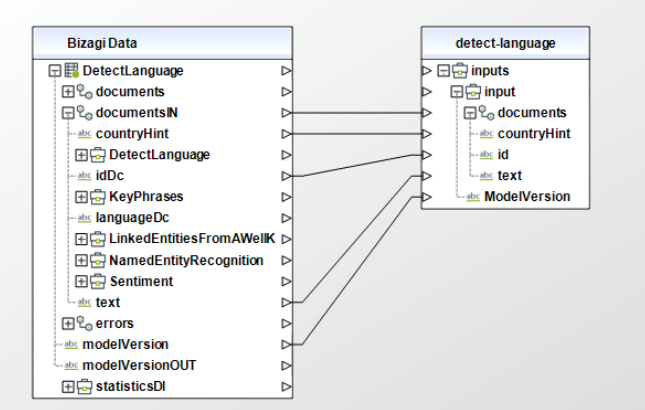
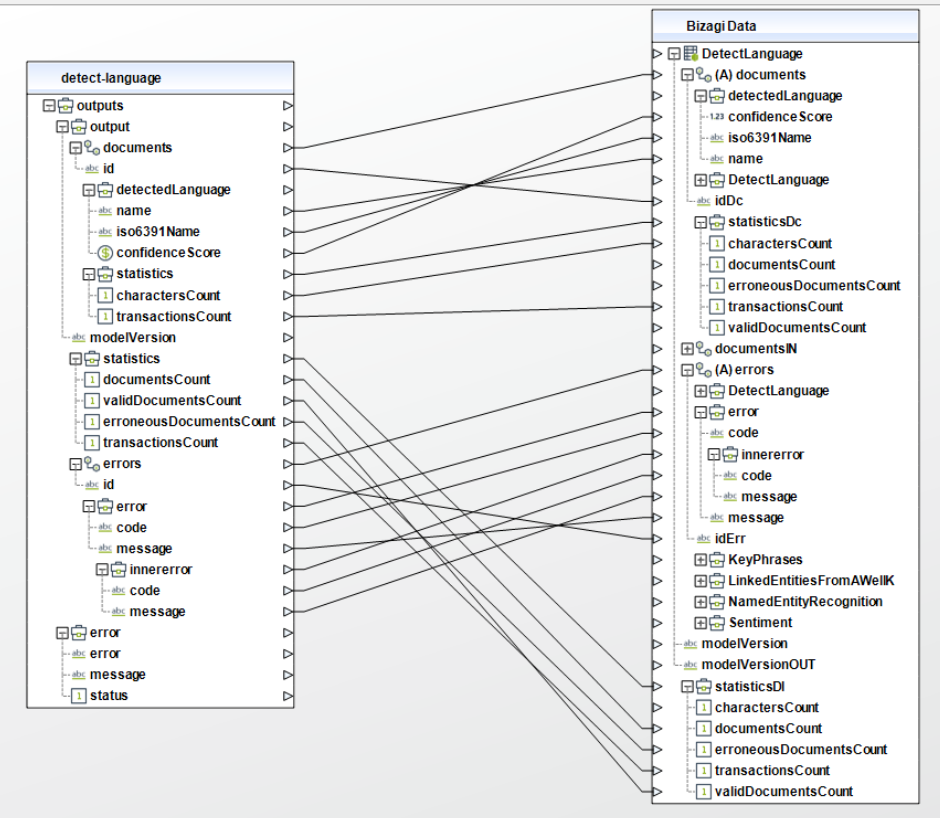
Acciones disponibles
Detect language
Detecta el idioma de un texto.
Para configurar sus entradas, tenga en cuenta las siguientes descripciones:
•documents (Requerido): Colección que tiene los siguientes parámetros:
oid (Requerido): El identificador de texto. Este parámetro debe ser una cadena de texto en su modelo Bizagi.
otext (Requerido): El texto a analizar. Este parámetro debe ser una cadena de texto en su modelo Bizagi.
•modelVersion: La versión del modelo que desea utilizar, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo Bizagi.
Para configurar las salidas de esta acción, puede asignar el objeto de salida a la entidad correspondiente en Bizagi y asegúrese de mapear los atributos de la entidad apropiadamente.
Las salidas de este conector son las siguientes:
•statistics (Objeto): representa un objeto con los siguientes atributos:
odocumentsCount (Entero): el número de documentos procesados.
ovalidDocumentsCount (Entero): el número de documentos válidos procesados.
oerroneousDocumentsCount (Entero): el número de documentos con errores.
otransactionsCount (Entero): el número de transacciones exitosas.
•documents (Colección de Objetos): la lista de documentos analizados.
oid (Cadena): el identificador del documento de entrada.
odetectedLanguages (Objeto): contiene los siguientes parámetros.
▪name (Cadena): nombre del idioma.
▪iso6391Name (Cadena):el nombre abreviado del idioma.
▪confidenceScore (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza de que el idioma detectado es el correcto.
ostatistics (Objeto): estadísticas del documento
▪charactersCount (Entero): el número de caracteres del documento.
▪transactionsCount (Entero): el número de transacciones exitosas en el documento.
•error (Colección de Objetos): enumera los detalles si un documento tuvo errores durante el análisis.
•modelVersion (Cadena): la versión del modelo utilizado, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
Para más información sobre el uso de este método, consulte la documentación oficial de Azure AI Services.
Named Entity Recognition
Detecta entidades como Persona, Organización o Ubicación en el texto. Para más información sobre las categorías de entidades, consulte la documentación oficial de Microsoft.
Para configurar sus entradas, tenga en cuenta las siguientes descripciones:
•documents (Requerido): Colección que tiene los siguientes parámetros:
oid (Requerido): El identificador de texto. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
otext (Requerido): El texto a analizar. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
olanguage: El lenguaje del texto, los valores comunes son: de, en, es, fr, it, ja, ko, nl. Para más información consulte la documentación de detección de lenguaje. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
•modelVersion:La versión del modelo que desea utilizar, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
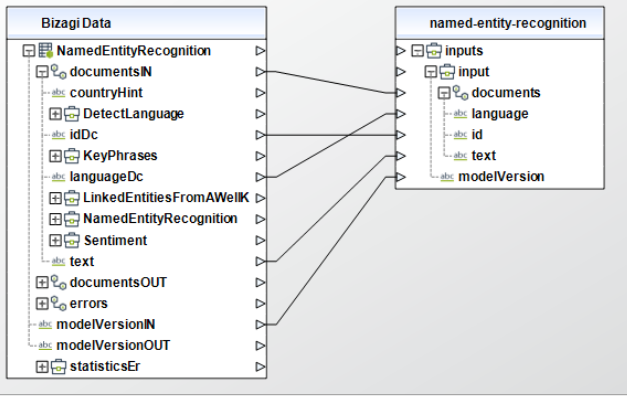
Para configurar las salidas de esta acción, puede asignar el objeto de salida a la entidad correspondiente en Bizagi y asegúrese de mapear los atributos de la entidad apropiadamente.
Las salidas de este conector son las siguientes:
•statistics (Objeto): representa un objeto con los siguientes atributos:
odocumentsCount (Entero): el número de documentos procesados.
ovalidDocumentsCount (Entero): el número de documentos válidos procesados.
oerroneousDocumentsCount (Entero): el número de documentos con errores.
otransactionsCount (Entero): el número de transacciones exitosas.
•documents (Colección de Objetos): la lista de documentos analizados.
oid (Cadena): el identificador del documento de entrada.
oentities (Colección de Objetos): la lista de entidades encontradas
▪text (Cadena): el texto identificado en el documento que pertenece a una entidad.
▪type (Cadena): tipo de entidad.
▪subtype (Cadena): describe a qué otra entidad puede pertenecer el texto.
▪offset (Entero): ubicación del texto identificado en el documento. Para obtener más información visite la documentación acerca de los desplazamientos.
▪length (Entero): la longitud de la palabra encontrada.
▪confidenceScore (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
ostatistics (Objeto): estadísticas de los documentos
▪charactersCount (Entero): el número de caracteres del documento.
▪transactionsCount (Entero): el número de transacciones exitosas en el documento.
•error (Colección de Objetos): enumera los detalles si un documento tuvo errores durante el análisis.
•modelVersion (Cadena): la versión del modelo utilizado, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
Linked Entities from a well-known knowledge base
Devuelve una lista de las entidades detectadas junto con enlaces a una base de datos de conocimiento como Wikipedia.
Para configurar sus entradas, tenga en cuenta las siguientes descripciones:
•documents (Requerido): Colección que tiene los siguientes parámetros:
oid (Requerido): El identificador de texto. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
otext (Requerido): El texto a analizar. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
olanguage: El lenguaje del texto, los valores comunes son: de, en, es, fr, it, ja, ko, nl. Para más información consulte la documentación de detección de lenguaje. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
•modelVersion:La versión del modelo que desea utilizar, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
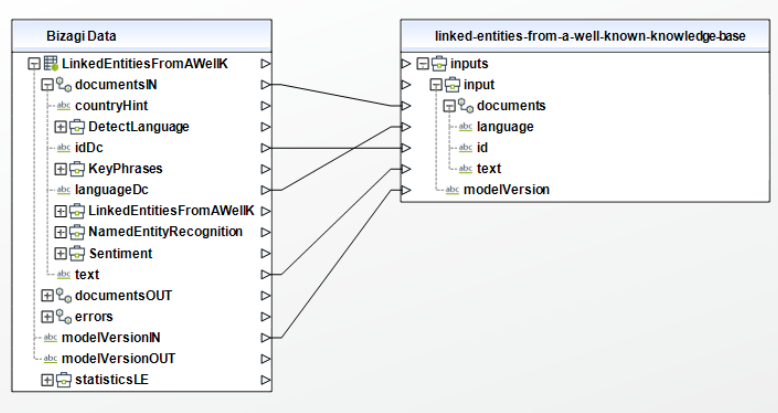
Para configurar las salidas de esta acción, puede asignar el objeto de salida a la entidad correspondiente en Bizagi y asegúrese de mapear los atributos de la entidad apropiadamente.
Las salidas de este conector son las siguientes:
•statistics (Objeto): representa un objeto con los siguientes atributos:
odocumentsCount (Entero): el número de documentos procesados.
ovalidDocumentsCount (Entero): el número de documentos válidos procesados.
oerroneousDocumentsCount (Entero): el número de documentos con errores.
otransactionsCount (Entero): el número de transacciones exitosas.
•documents (Colección de Objetos): la lista de documentos analizados.
oid (Cadena): el identificador del documento de entrada.
oentities (Colección de Objetos): la lista de entidades encontradas.
▪name (Cadena): el texto identificado en el documento que pertenece a una entidad.
▪matches (Colección de Objetos): Lista de coincidencias relacionadas con la propiedad name.
•text (Cadena): el texto identificado en el documento que pertenece a una entidad.
•offset (Entero): ubicación del texto identificado en el documento. Para obtener más información visite la documentación acerca de los desplazamientos.
•length (Entero): la longitud de la palabra encontrada.
•confidenceScore (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
▪language (Cadena): la forma abreviada del idioma para la propiedad name identificada.
▪id (Cadena): suele ser el mismo valor que la propiedad name.
▪url (Cadena): URL a la base de datos de conocimiento que tiene información sobre la propiedad name.
▪dataSource (Cadena): Nombre de la base de datos de conocimiento vinculada.
▪type (Cadena): tipo de entidad.
▪subtype (Cadena): describe a qué otra entidad puede pertenecer el texto.
ostatistics (Objeto): estadísticas del documento
▪charactersCount (Entero): el número de caracteres del documento.
▪transactionsCount (Entero)El número de transacciones exitosas en el documento.
•error (Colección de Objetos): enumera los detalles si un documento tuvo errores durante el análisis.
•modelVersion (Cadena): la versión del modelo utilizado, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo Bizagi.
Key Phrases
Detecta una lista de cadenas de texto con los puntos clave del texto de entrada.
Para configurar sus entradas, tenga en cuenta las siguientes descripciones:
•documents (Requerido): Colección que tiene los siguientes parámetros:
oid (Requerido): El identificador de texto. Este parámetro debe ser una cadena (String) en su modelo de Bizagi.
otext (Requerido): El texto a analizar. Este parámetro debe ser una cadena (String) en su modelo de Bizagi.
olanguage: El lenguaje del texto, los valores comunes son: de, en, es, fr, it, ja, ko, nl. Para más información consulte la documentación de detección de lenguaje. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
•modelVersion:La versión del modelo que desea utilizar, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
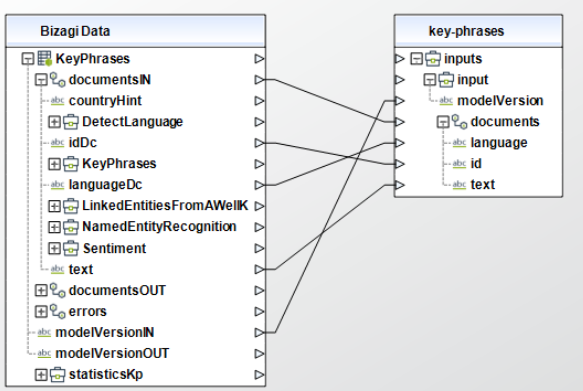
Para configurar las salidas de esta acción, puede asignar el objeto de salida a la entidad correspondiente en Bizagi y asegúrese de mapear los atributos de la entidad apropiadamente.
Las salidas de este conector son las siguientes:
•statistics (Objeto): representa un objeto con los siguientes atributos:
odocumentsCount (Entero): el número de documentos procesados.
ovalidDocumentsCount (Entero): el número de documentos válidos procesados.
oerroneousDocumentsCount (Entero): el número de documentos con errores.
otransactionsCount (Entero): el número de transacciones exitosas.
•documents (Colección de Objeto): la lista de documentos analizados.
oid (Cadena): el identificador del documento de entrada.
okeyPhrases (Colección de cadenas): una lista de las frases clave detectadas en el texto.
ostatistics (Objeto): estadísticas del documento.
▪charactersCount (Entero): el número de caracteres del documento.
▪transactionsCount (Entero): el número de transacciones exitosas en el documento.
•error (Colección de Objeto): enumera los detalles si un documento tuvo errores durante el análisis.
•modelVersion (Cadena): La versión del modelo que desea utilizar, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
Sentiment
Detecta una predicción de sentimiento, junto con puntuaciones de sentimiento para las clases de sentimiento (Positivo, Negativo y Neutral), para el texto.
Para configurar sus entradas, tenga en cuenta las siguientes descripciones:
•documents (Requerido): Colección que tiene los siguientes parámetros:
oid (Requerido): El identificador de texto. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
otext (Requerido): El texto a analizar. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
olanguage: El lenguaje del texto, los valores comunes son: de, en, es, fr, it, ja, ko, nl. Para más información consulte la documentación de detección de lenguaje. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
•modelVersion:La versión del modelo que desea utilizar, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
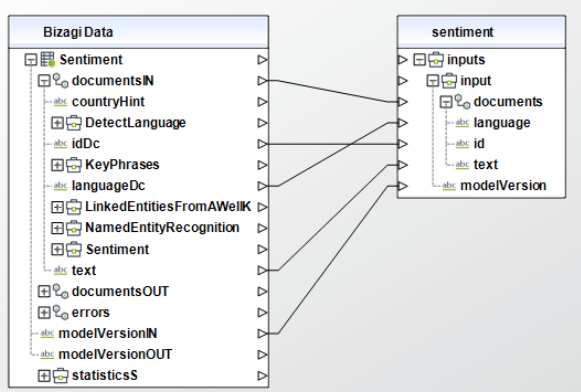
Para configurar las salidas de esta acción, puede asignar el objeto de salida a la entidad correspondiente en Bizagi y asegúrese de mapear los atributos de la entidad apropiadamente.
Las salidas de este conector son las siguientes:
•statistics (Objeto): representa un objeto con los siguientes atributos:
odocumentsCount (Entero): el número de documentos procesados.
ovalidDocumentsCount (Entero): el número de documentos válidos procesados.
oerroneousDocumentsCount (Entero): el número de documentos con errores.
otransactionsCount (Entero): el número de transacciones exitosas.
•documents (Colección de Objetos): la lista de documentos analizados.
oid (Cadena): el identificador del documento de entrada.
osentiment (Cadena): el sentimiento encontrado en el documento analizado, los valores son: positivo, negativo y neutral.
oconfidenceScores (Objeto): puntúa cada uno de los sentimientos del documento.
▪positive (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
▪neutral (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
▪negative (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
osentences (Colección de Objetos): Listas
▪sentiment (Cadena): el sentimiento encontrado en la frase analizada, los valores son: positivo, negativo y neutro.
▪confidenceScores (Objeto): puntúa cada uno de los sentimientos de la frase.
•positive (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
•neutral (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
• negative (Flotante): certeza de la detección, los valores más cercanos a 1 tienen más certeza.
▪offset (Entero): ubicación del texto identificado en el documento. Para obtener más información visite la documentación acerca de los desplazamientos.
▪length (Entero): la longitud de la oración.
▪text (Cadena): texto identificado
ostatistics (Objeto): estadísticas del documento
▪charactersCount (Entero): el número de caracteres del documento.
▪transactionsCount (Entero): el número de transacciones exitosas en el documento.
•error (Colección de Objetos): enumera los detalles si un documento tuvo errores durante el análisis.
•modelVersion (Cadena): la versión del modelo utilizado, ya sea latest, 2021-10-01, 2022-06-01, 2022-10-01 ó 2022-11-01. Este parámetro debe ser una cadena de texto en su modelo de Bizagi.
Last Updated 9/3/2024 5:06:53 PM