Suponga que el siguiente proceso es cómo se manejan las reseñas de los clientes en el área de Servicio al cliente de una empresa. Después de que el área recibe una reseña, la analiza usando el conector de Text Analytics que provee Microsoft Cognitive Services.
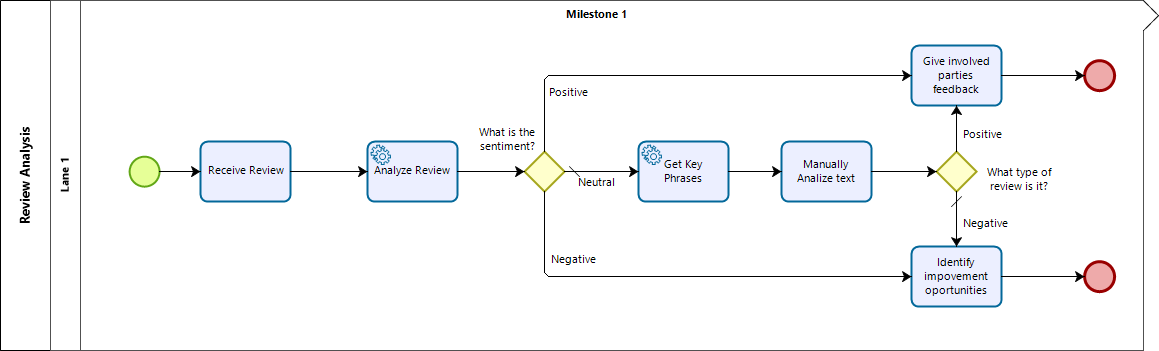
Después de recibir la reseña, esta se analiza a través del conector de Text Analytics de Microsoft Cognitive Services. Dependiendo de la calificación del sentimiento en la reseña, se llevan a cabo distintas acciones:
•Cuando la reseña es positiva, las partes involucradas reciben la realimentación positiva.
•Cuando la reseña es negativa, las partes involucradas identifican las oportunidades de mejora a partir de la reseña.
•Cuando la reseña es neutral, esta pasa a ser revisada por una persona que la analiza para calificarla como positiva o negativa.
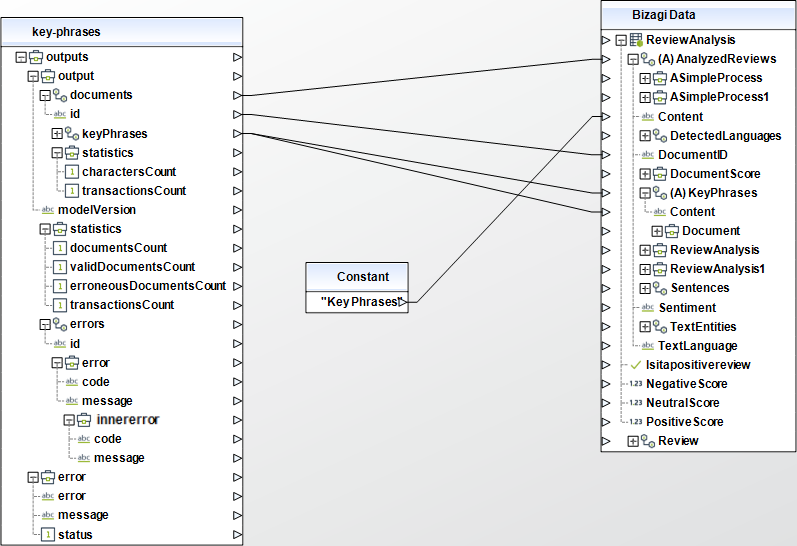
El siguiente es el modelo de datos para el proceso de análisis de reseñas:
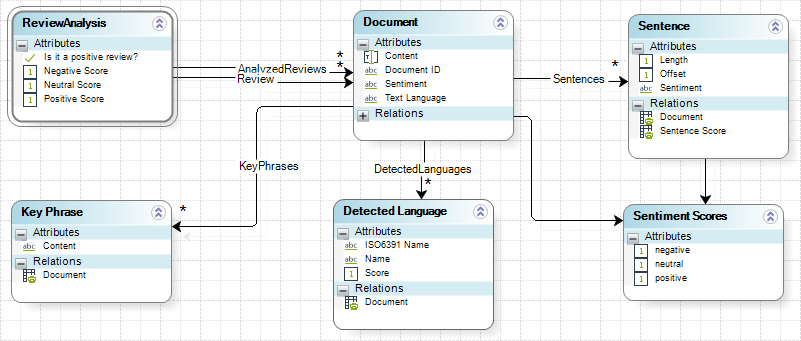
Este proceso utiliza distintos métodos para analizar las reseñas: comenzando por la detección del lenguaje y posteriormente identificando el sentimiento de la reseña. Si la reseña es neutral, se extraen las frases clave para hacer un análisis manual más fácilmente.
Tenga en cuenta que cada vez que usted utiliza el conector, usted puede agregar la respuesta a la colección de reseñas analizadas, o puede sobrescribir la colección existente. En este caso, la configuración recomendada es tener agregar todas las peticiones a la colección (reseñas analizadas). La entidad Documentos tiene un atributo de Contenido, el cual puede usar para separar las respuestas de los distintos métodos. También, tenga en cuenta que sólo se realiza una revisión por proceso. Esto significa que usted recibe un ítem de colección cada vez que se usa el conector. Las reseñas analizadas no excederán los 3 ítems, que es el número máximo de veces que el conector puede usarse por cada ejecución del proceso.
Las acciones que se ejecutan a la entrada de la tarea de servicio Analizar Reseña son:
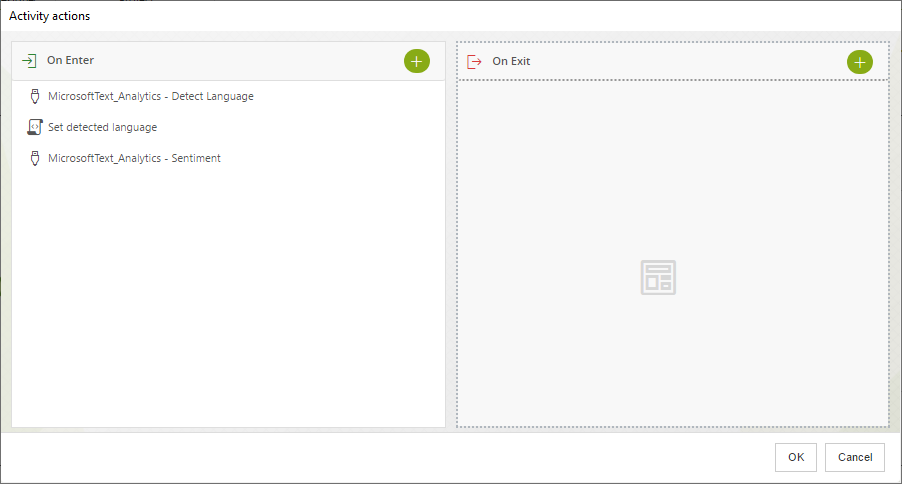
Primero, el conector de Text Analytics se utiliza para detectar el lenguaje de la reseña, así es como la respuesta debe mapearse para identificar el lenguaje. Note que hay una constante de tipo String con el valor Detección de lenguaje mapeado al atributo Contenido de la colección.
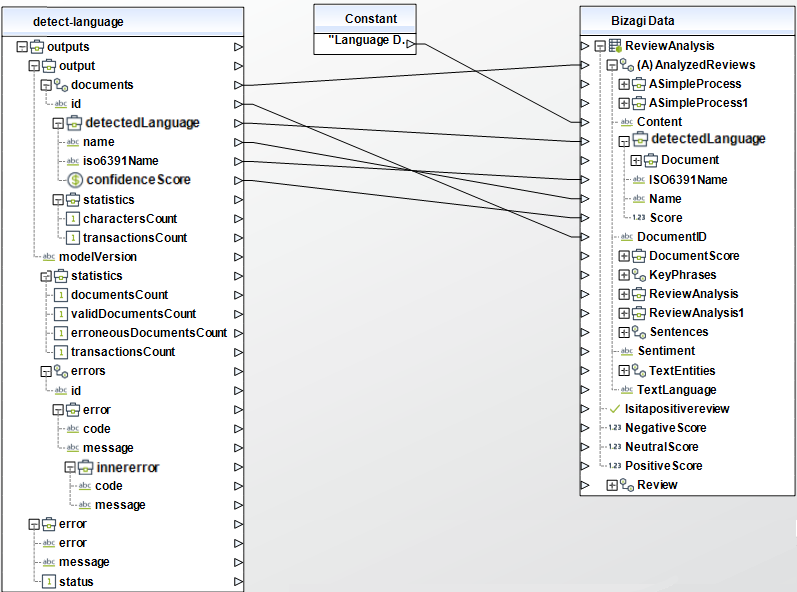
Después, se tiene la regla que obtiene la respuesta del lenguaje y lo asigna al lenguaje de la reseña.
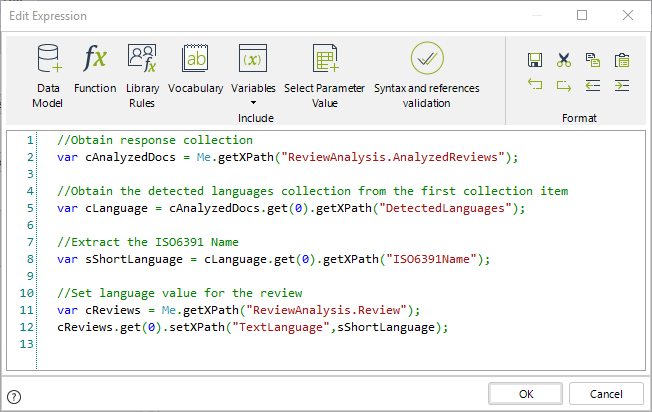
La expresión utilizada es la siguiente:
//Obtain response collection
var cAnalyzedDocs = Me.getXPath("ReviewAnalysis.AnalyzedReviews");
//Obtain the detected languages collection from the first collection item
var cLanguage = cAnalyzedDocs.get(0).getXPath("DetectedLanguages");
//Extract the ISO6391 Name
var sShortLanguage = cLanguage.get(0).getXPath("ISO6391Name");
//Set language value for the review
var cReviews = Me.getXPath("ReviewAnalysis.Review");
cReviews.get(0).setXPath("TextLanguage",sShortLanguage);
La tercera acción en esta tarea consiste en detectar el sentimiento de la reseña. Así es como se debe mapear la respuesta para la detección de sentimientos. Note que hay una constante de tipo String con el valor Detección de sentimiento mapeado al atributo Contenido de la colección.
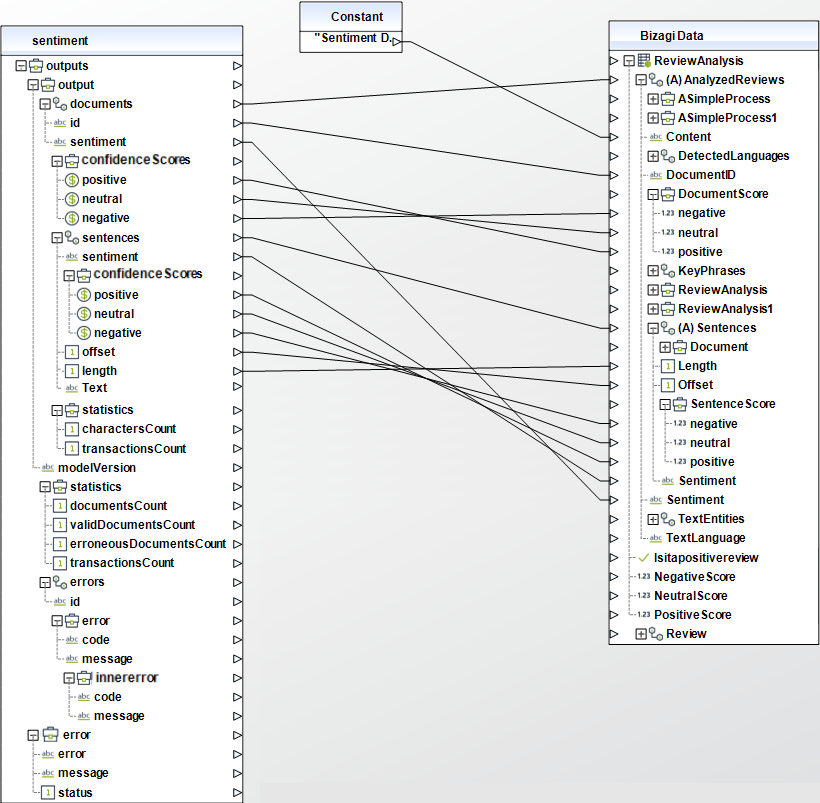
El método de sentimientos del conector retorna el sentimiento identificado junto con las puntuaciones para los sentimientos de positividad, negatividad y neutralidad. La puntuación del sentimiento valora la certeza del sentimiento detectado. Valores cercanos a 1 representan una mayor certeza. Este valor se utiliza para configurar la compuerta exclusiva en el proceso.
El conector devuelve los resultados como una colección, ya que puede analizar más de un texto al mismo tiempo. En este ejemplo se utiliza una sola reseña por proceso. Adicionalmente, se utilizó la siguiente expresión para mapear los resultados de la colección a los valores en la entidad de proceso, como una acción a la entrada para la compuerta exclusiva.
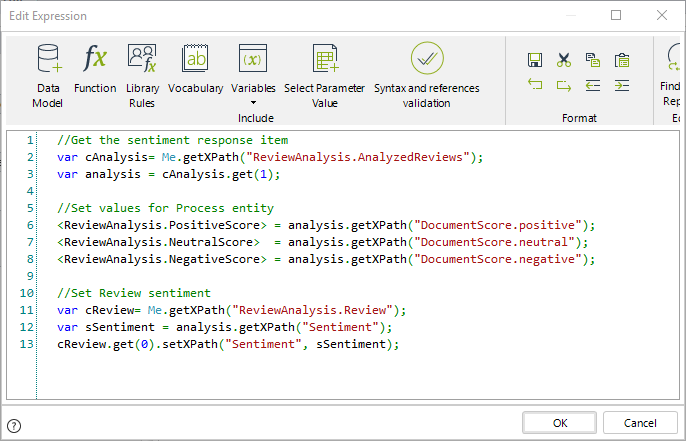
La expresión utilizada es la siguiente:
//Get the sentiment response item
var cAnalysis= Me.getXPath("ReviewAnalysis.AnalyzedReviews");
var analysis = cAnalysis.get(1);
//Set values for Process entity
<ReviewAnalysis.PositiveScore> = analysis.getXPath("DocumentScore.positive");
<ReviewAnalysis.NeutralScore> = analysis.getXPath("DocumentScore.neutral");
<ReviewAnalysis.NegativeScore> = analysis.getXPath("DocumentScore.negative");
//Set Review sentiment
var cReview= Me.getXPath("ReviewAnalysis.Review");
var sSentiment = analysis.getXPath("Sentiment");
cReview.get(0).setXPath("Sentiment", sSentiment);
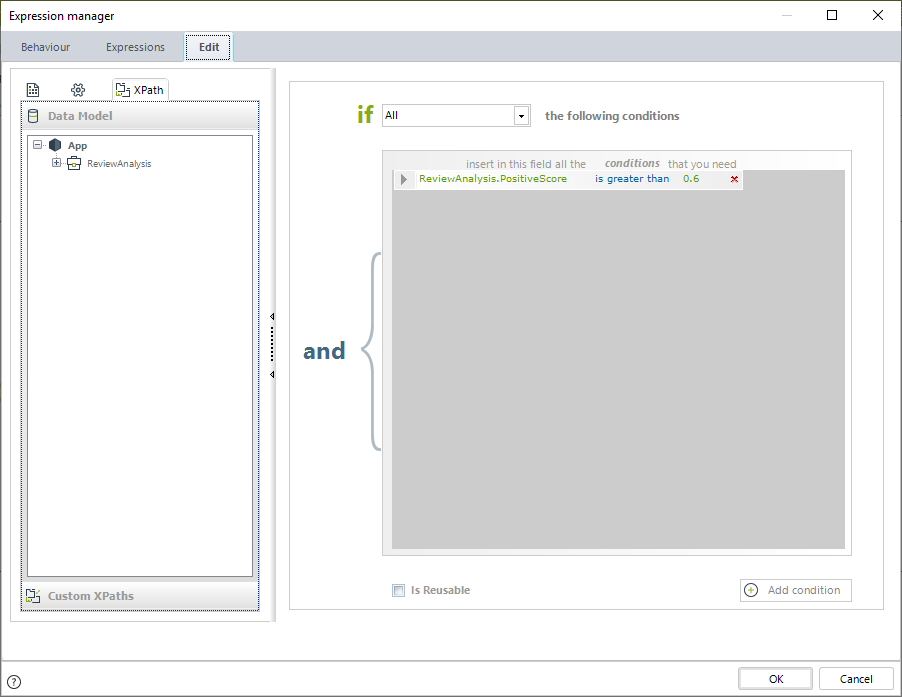
Después de configurar el conector, se configura la compuerta exclusiva con la puntuación del sentimiento del texto. Se utiliza 0.6 como el umbral para definir si la reseña es positiva o negativa. De este modo, cuando la reseña tiene una puntuación positiva mayor a 0.6, es una reseña positiva. Cuando la reseña tiene una puntuación negativa mayor a 0.6, se interpreta como una reseña negativa. Finalmente, si ninguna de las dos puntuaciones es alcanzada, se interpreta como una reseña neutral y se envía para su análisis manual.
La siguiente es la manera en la que se debe mapear la respuesta cuando el sentimiento es mixto como parte de la tarea de servicio extraer frases clave. Note que hay una constante de tipo String con el valor Frases clave mapeado al atributo Contenido de la colección.
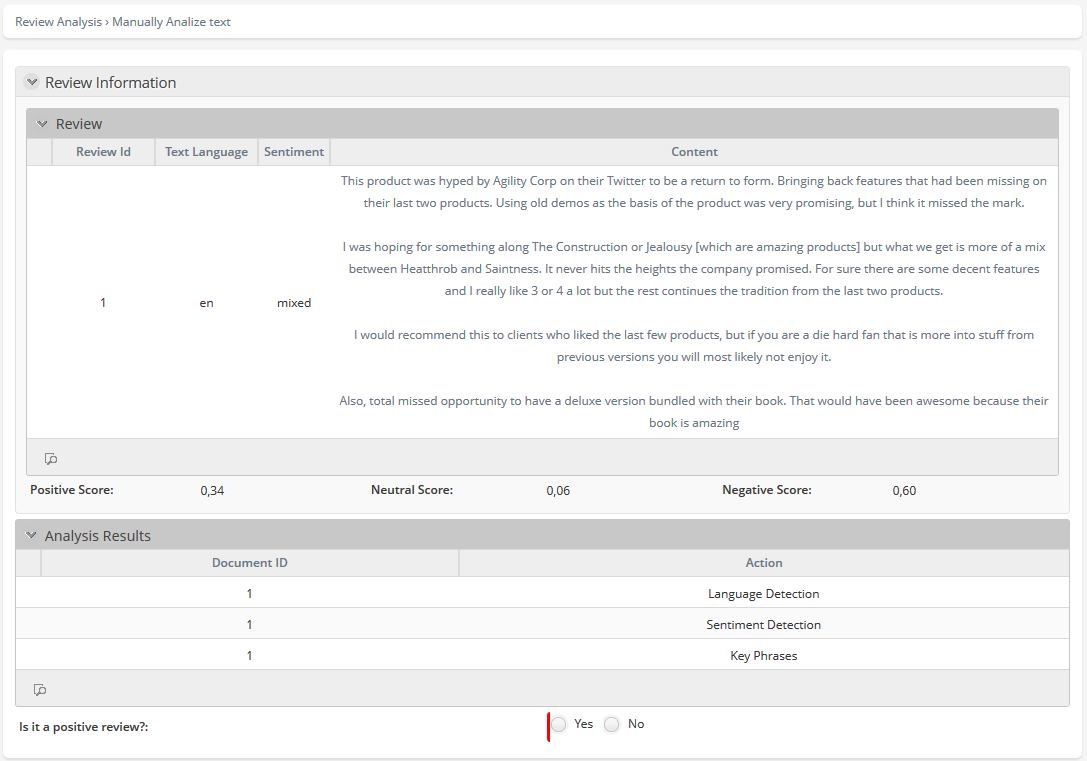
Con esta configuración, cuando una reseña tiene una calificación neutral, el usuario puede distinguir las respuestas entre sí en la tarea Analizar texto manualmente. La forma de la tarea muestra la reseña, junto con los sentimientos y lenguajes identificados, y el puntaje del sentimiento.
Cuando el usuario selecciona el análisis de resultados y ve el detalle de la forma, dependiendo de la acción, la forma muestra información distinta.
El siguiente es un ejemplo de los resultados de detección de lenguaje:
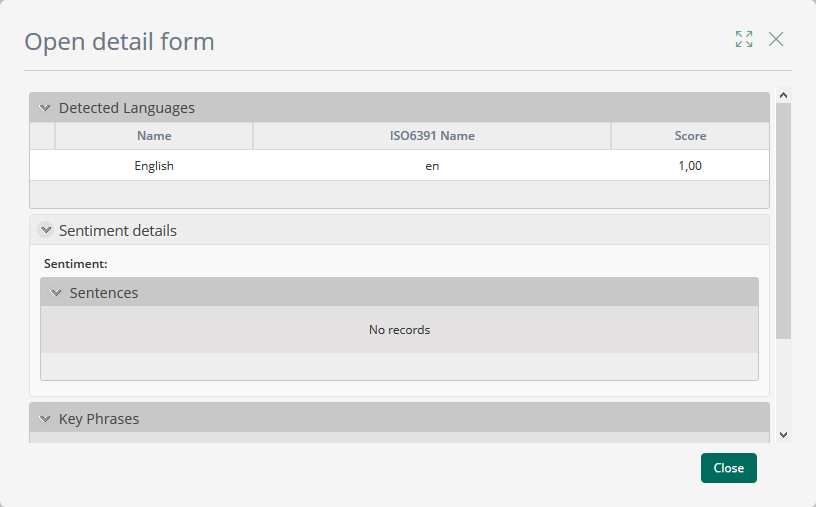
El usuario ve el nombre del lenguaje, el nombre corto del lenguaje (ISO6391) y el puntaje de certeza de la detección.
Cuando el usuario ingresa a los detalles de la detección de sentimientos, ve lo siguiente:
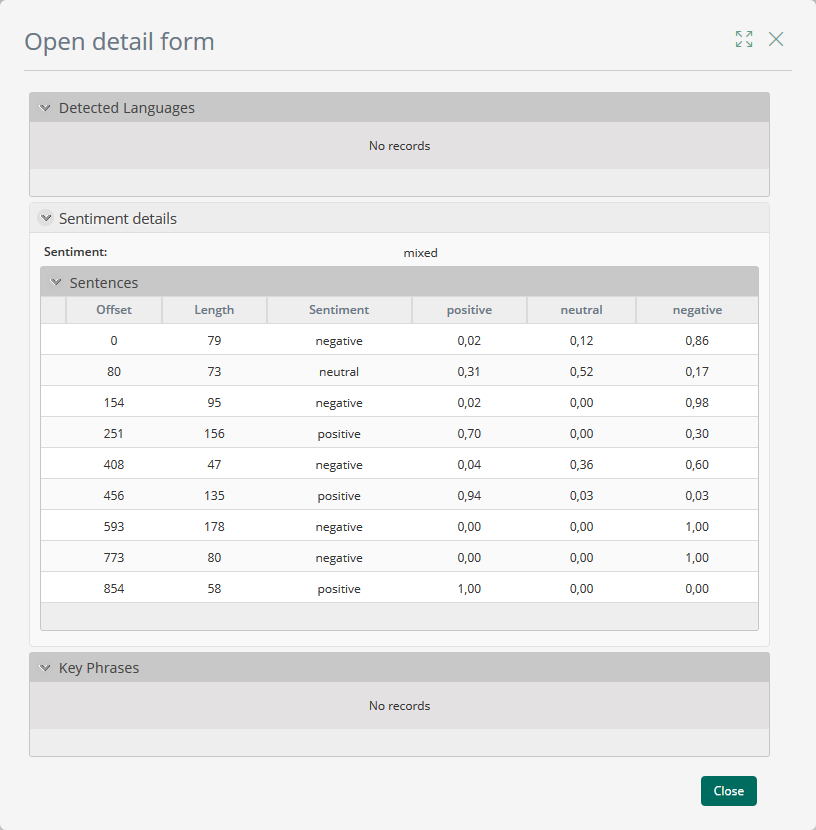
El sentimiento global del texto se muestra junto con el sentimiento y la puntuación de cada frase. El atributo de desplazamiento se refiere a la posición de la frase en el texto analizado y el atributo longitud se refiere a la longitud de la frase en caracteres.
El usuario puede también ver las frases clave detectadas. El detalle de estas se ve así:
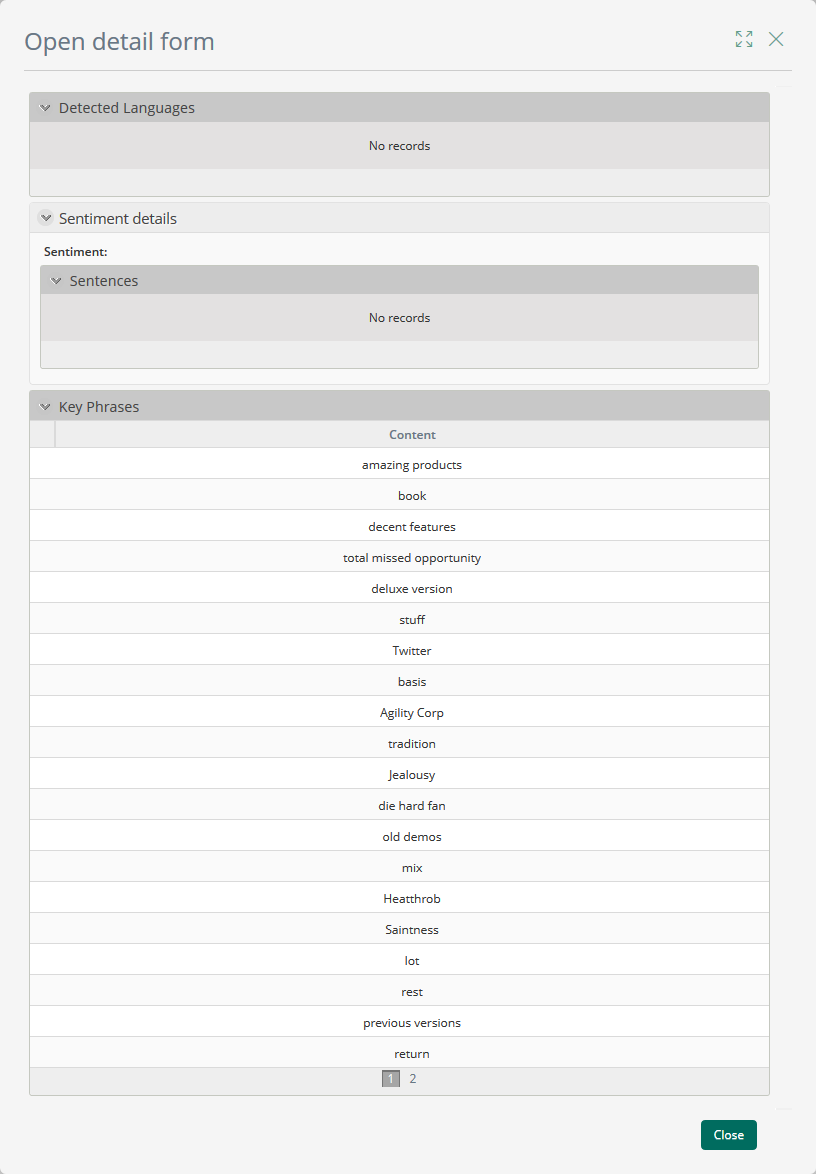
Estas frases pueden ser útiles para identificar las ideas principales del texto y el sentimiento del mismo. Así, el usuario puede decidir cuándo una reseña es positiva o negativa y continuar con el proceso.
De esta manera se ha configurado correctamente el conector de Text Analitycs provisto por Microsoft Cognitive Services en Bizagi.
Last Updated 1/29/2024 5:03:00 PM