Introducción
Si usted desea aumentar la resiliencia de Automation Service y garantizar la continuidad del servicio en caso de una interrupción o desastre, Bizagi ofrece un servicio de Recuperación ante Desastres. Este servicio está diseñado para minimizar el tiempo de inactividad y proteger los recursos críticos durante incidentes inesperados.
El servicio de Recuperación ante Desastres ofrece dos opciones:
•Réplica completa de la arquitectura, que consiste en la replicación del conjunto completo de recursos.
•Solo base de datos, que consiste en la replicación de datos.
Este servicio está disponible con un costo adicional, independiente a las tarifas estándar de Automation Service.
La infraestructura se aprovisiona en un sitio primario aislado, cuya región geográfica se selecciona según sus requisitos específicos, como cumplimiento normativo local o consideraciones de rendimiento.
Cuando el servicio de Recuperación ante Desastres está habilitado, Bizagi aprovisiona un sitio secundario o sitio de recuperación, el cual se activa si el sitio primario queda no-operativo debido a un desastre. Este sitio de recuperación se despliega en una región emparejada ubicada al menos a 300 millas del sitio primario, garantizando redundancia geográfica y mayor resiliencia.
|
Este servicio está disponible para el ambiente de producción |
Opción 1: Recuperación ante Desastres con Réplica Completa
Tanto el sitio primario como el sitio de recuperación permanecen completamente aprovisionados y en estado listo. Cada sitio incluye la Infraestructura Base, Automation Service y bases de datos sincronizadas. El sitio de recuperación replica la topología de red, controles de seguridad, almacenamiento y todos los componentes críticos del sitio primario para garantizar consistencia operativa.
Durante la operación normal, el sitio primario es el activo y atiende todas las interacciones de los usuarios. El sitio de recuperación permanece en modo pasivo y solo se activa cuando se declara oficialmente un desastre o una interrupción mayor. Una vez activado, el tráfico de usuarios se enruta al sitio de recuperación conforme a los procedimientos establecidos de conmutación por error.
Esta arquitectura activa/pasiva está diseñada para lograr un RTO reducido.
Dado que los servicios e infraestructura ya están preconfigurados y sincronizados continuamente, la conmutación por error puede ejecutarse rápidamente, minimizando el tiempo de inactividad y respaldando los objetivos de continuidad del negocio.
|
Si tiene una VPN configurada, debe adquirir una segunda VPN (adicional). Esto se configura en el onboarding. |
Objetivo de Punto de Recuperación (RPO)
•RPO de Base de Datos
Define la cantidad máxima de pérdida de datos aceptable, medida en tiempo, ante un desastre.
El RPO de la base de datos es de hasta 5 minutos, lo que asegura una pérdida mínima de datos gracias a la sincronización continua.
•RPO de Almacenamiento de Archivos
Define el punto en el tiempo al cual pueden restaurarse los archivos después de un desastre.
El RPO de archivos es de menos de 15 minutos. Este RPO difiere del de base de datos porque los archivos se almacenan en un Storage Account dedicado con un mecanismo de replicación independiente.
|
Es importante entender la diferencia entre la base de datos, y el almacenamiento de archivos. La base de datos contiene la información en tablas relacionales, mientras que los archivos, para mejorar el performance, se almacenan en un Storage Account. Ver Arquitectura de Automation Service. |
Objetivo de Tiempo de Recuperación del Ambiente (RTO)
El RTO de una réplica completa define el tiempo máximo requerido para restaurar el servicio completo después de una interrupción o desastre.
En esta configuración, el RTO es de hasta 3 horas, garantizando la recuperación oportuna de los servicios críticos.
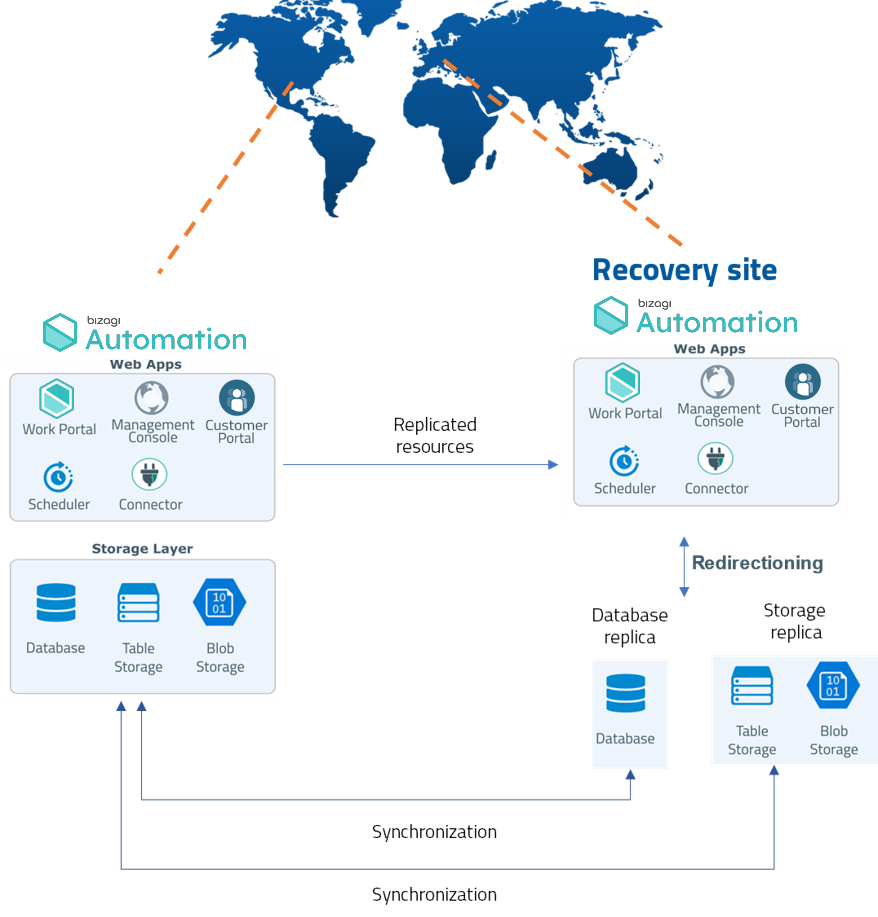
En caso de una interrupción importante, Bizagi declarará un desastre y activará el servicio de recuperación ante desastres. Como resultado, el sitio de recuperación se activará temporalmente y recibirá la operación de manera segura, aislada y confiable. El sitio de recuperación será redirigido a la base de datos replicada. Después de que se haya resuelto el evento de Desastre, Bizagi tomará la decisión de iniciar el plan alternativo para ejecutar el servicio en el sitio primario original. Durante la conmutación por error, los usuarios pueden experimentar un ligero impacto en el rendimiento, pero es temporal ya que el sitio de recuperación se ejecutará en el mismo Nivel de Rendimiento del sitio primario.
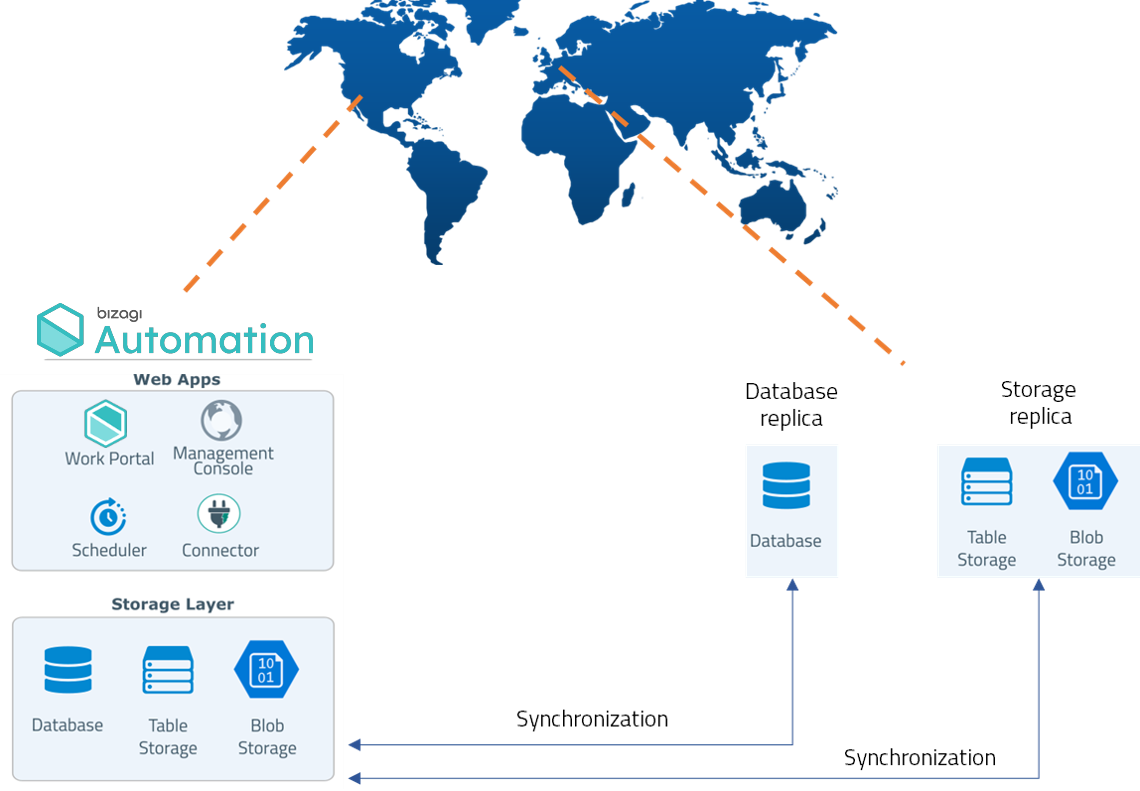
Opción 2: Recuperación ante desastres con Base de Datos
El ambiente está completamente desplegado y activo en la región primaria.
En la región secundaria, solo se aprovisionan los servicios de almacenamiento requeridos, la capa de seguridad y los recursos de red necesarios para habilitar la integración en caso de desastre. Ambos sitios mantienen sincronización continua de los contenidos de base de datos y almacenamiento.
En caso de un desastre declarado, la infraestructura base y la aplicación de Automation Service se despliegan en el sitio secundario, se conectan a los datos sincronizados en espera y finalmente se activan. Una vez activo, las solicitudes se redirigen al sitio de recuperación usando los datos replicados.
Debido a la replicación continua de datos, no se requieren tiempos de espera por procesos de restauración de backups o recuperación de archivos, lo cual reduce tiempos de recuperación y asegura una restauración más rápida conforme al RTO definido.
Objetivo de Punto de Recuperación (RPO)
•RPO de Base de Datos
El RPO de la base de datos en esta opción es de hasta 5 minutos, asegurando mínima pérdida de datos con sincronización continua.
•RPO de Almacenamiento de Archivos
El RPO de archivos es de menos de 15 minutos, debido al mecanismo de replicación independiente del Storage Account.
|
Es importante entender la diferencia entre la base de datos, y el almacenamiento de archivos. La base de datos contiene la información en tablas relacionales, mientras que los archivos, para mejorar el performance, se almacenan en un Storage Account. Ver Arquitectura de Automation Service. |
Objetivo de Tiempo de Recuperación (RTO)
El RTO del ambiente completo en esta configuración es de hasta 18 horas, garantizando la restauración oportuna de los servicios críticos.
Pruebas y Entrenamiento
Siguiendo las mejores prácticas de seguridad de la información, Bizagi ejecuta actividades continuas de desarrollo, validación y pruebas para asegurar que Automation Service siga siendo compatible y seguro con cada nuevo release. Cada versión se somete a pruebas controladas para validar compatibilidad con cambios de plataforma, nuevas funcionalidades y productos integrados.
Adicionalmente, cada modelo de recuperación ante desastres se prueba formalmente al menos una vez al año en ambientes internos similares a producción. Estas pruebas se documentan y evalúan para verificar la efectividad de los procedimientos, el estado de preparación y el cumplimiento de los objetivos de recuperación.
Escenarios de Respuesta ante Desastres
Escenario 1: Clientes con Recuperación de Desastres (DR) Adquirida
Para los clientes que han adquirido el servicio de Recuperación de Desastres (DR) de Bizagi, proporcionamos un nivel mejorado de protección y recuperación rápida en caso de desastre.
1.Respuesta Inmediata:
oDetección de Incidentes: Al detectar una interrupción del servicio, nuestros sistemas de monitoreo alertan a nuestro equipo de operaciones de DR inmediatamente.
oEvaluación: El equipo evalúa rápidamente la situación para confirmar el desastre y determinar el impacto en los servicios.
2.Notificación al Cliente:
oDeclaración de Desastre: Declaramos un desastre dentro de los 30 minutos a 1 hora después de la confirmación.
oComunicación: Los clientes son notificados vía correo electrónico dentro de las siguientes 4 horas, con actualizaciones y plazos estimados para la resolución.
3.Activación del Plan de DR:
oCambio a la Región Secundaria: Los servicios se cambian a una región de recuperación secundaria, asegurando un tiempo de inactividad mínimo.
oContinuidad del Servicio: Nuestro objetivo es cumplir con los Objetivos de Tiempo de Recuperación (RTO) y los Objetivos de Punto de Recuperación (RPO) especificados en el acuerdo de DR, asegurando una pérdida de datos mínima y una rápida restauración de los servicios.
4.Actualizaciones Continuas:
oInformes de Estado: Se proporcionan actualizaciones regulares a los clientes vía correo electrónico sobre el progreso de la recuperación y los tiempos de restauración esperados.
5.Post-Restauración:
oConfirmación: Los clientes son notificados tan pronto como los servicios estén completamente restaurados.
Escenario 2: Clientes Sin Recuperación de Desastres (Dependiendo de Alta Disponibilidad)
Para los clientes que no han optado por nuestro servicio de Recuperación de Desastres (DR), ofrecemos un Acuerdo de Nivel de Servicio (SLA) estándar con Alta Disponibilidad (HA) del 99.95%. Usted puede ampliar el porcentaje del SLA. Si consume más de 500 BPU mensuales tendrá un SLA del 99,99%. Si consume menos, puede adquirir un servicio de disponibilidad mejorada para aumentar su SLA al 99,99% pagando un costo adicional. Esto asegura la continuidad del negocio dentro de una única región de Azure. En el improbable caso de un desastre, nuestros procedimientos están diseñados para restaurar los servicios lo más rápidamente posible una vez que Azure haya resuelto el problema.
1.Respuesta Inicial:
oDetección de Incidentes: Nuestros sistemas de monitoreo alertan a nuestro equipo de operaciones ante cualquier interrupción del servicio.
oEvaluación: El equipo evalúa la situación para confirmar si es un desastre que afecta la región o centro de datos de Azure.
2.Notificación al Cliente:
oDeclaración de Desastre: Declaramos un desastre dentro de los 30 minutos a 1 hora después de la confirmación.
oComunicación: Los clientes son notificados vía correo electrónico dentro de las siguientes 6 horas, con actualizaciones y plazos estimados para la resolución.
3.Coordinación con Azure:
oMonitoreo: Trabajamos estrechamente con Azure para monitorear sus esfuerzos de restauración.
oRestauración del Servicio: Una vez que Azure restaura los servicios en la región afectada, nuestro equipo hace todo lo posible para restaurar nuestros servicios lo más rápido posible.
oComo no hay un Objetivo de Tiempo de Recuperación (RTO) o un Objetivo de Punto de Recuperación (RPO) definidos para los clientes sin DR, el tiempo de restauración dependerá del tiempo de resolución de Azure y los esfuerzos de recuperación subsiguientes de Bizagi.
oRestauración de Datos: Bizagi gestiona las copias de seguridad para minimizar las interrupciones en las operaciones normales, reducir el impacto general de interrupciones inesperadas del servicio y minimizar la pérdida de datos en caso de desastre. Las copias de seguridad son geo-replicadas. En caso de cualquier fallo, Bizagi puede restaurar la base de datos al punto de restauración más cercano basado en las copias de seguridad realizadas.
4.Post-Restauración:
oConfirmación de la Restauración del Servicio: Los clientes serán notificados tan pronto como los servicios estén completamente restaurados.
Resumen
Con DR Adquirido:
•Protección mejorada con una región de recuperación secundaria.
•Tiempo de inactividad mínimo con RTO y RPO específicos.
•Cambio rápido y actualizaciones continuas.
Sin DR (Alta Disponibilidad):
•Dependencia de la restauración de Azure.
•Sin RTO o RPO específicos.
•Esfuerzos para restaurar los servicios lo más rápido posible después de la recuperación de Azure.
Last Updated 1/16/2026 12:13:58 PM