Overview
Once you have created an AI experiment, generated the model, and are evaluating the accuracy of the prediction, you may switch to advanced options to modify the algorithm employed or explore other combinations.
These options generally assume a good degree of expertise in machine learning.
For information about generating the model to interpret results, refer to Working with AI experiments.
Advanced options
Switch to the advanced options by clicking Advanced View:

In the advanced view, you see a graphical display of how Bizagi Artificial Intelligence has determined the best treatment and algorithm for the predictive service.
The view presents the steps carried out (each step represented by a box) in process order from top to bottom.
1. The training flow.
This handles data treatment, algorithm choice and training of the model, as employed by Bizagi during the model generation step.

Interpreting the flows
You can explore the sequence of each flow and review the specific configuration for each of the steps by clicking its box.
To the right, you will see the configuration Bizagi Artificial Intelligence has applied as being best suited for the use case.
The image below shows an example of a training flow and how the first step is configured.
The step is of the type DataSource (typically the first one for a training flow), the step where data is obtained.
It is configured with indications of the target Dataset and the attributes to use (selected features):

For other steps, such as Clean Data, different settings are available.
The image below shows, as an example, that the upper Clean Data step applies for the pregnant, plasma, bpressure, skinthickness, 2h_insulin, BMI, and age attributes and that its clean policy for empty values replaces them by the average value of the set.
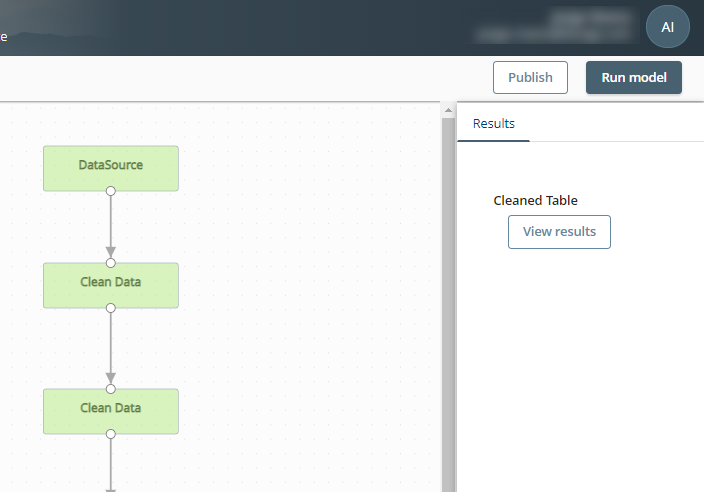
You may see more than one Clean Data step. Each step would provide a different treatment for empty values for the selected attributes.
You can replace empty values by editing the features selected in the experiment.
Click View results for both previous types of steps to see a sample of the data selected, not all the data is displayed.
There may be multiple sequence lines running to or from other steps.
In the case of Split Data, the model property Training data percentage (5% - 95%) indicates what fraction of data goes to one step (and by implication, the remaining fraction that goes to another step).
The image below shows how Split Data sends 70% of its data to the Train Model step (to achieve a best certainty for a prediction, a preselected model is used), and the remaining 30% goes to the Validate Model step (to verify test results).
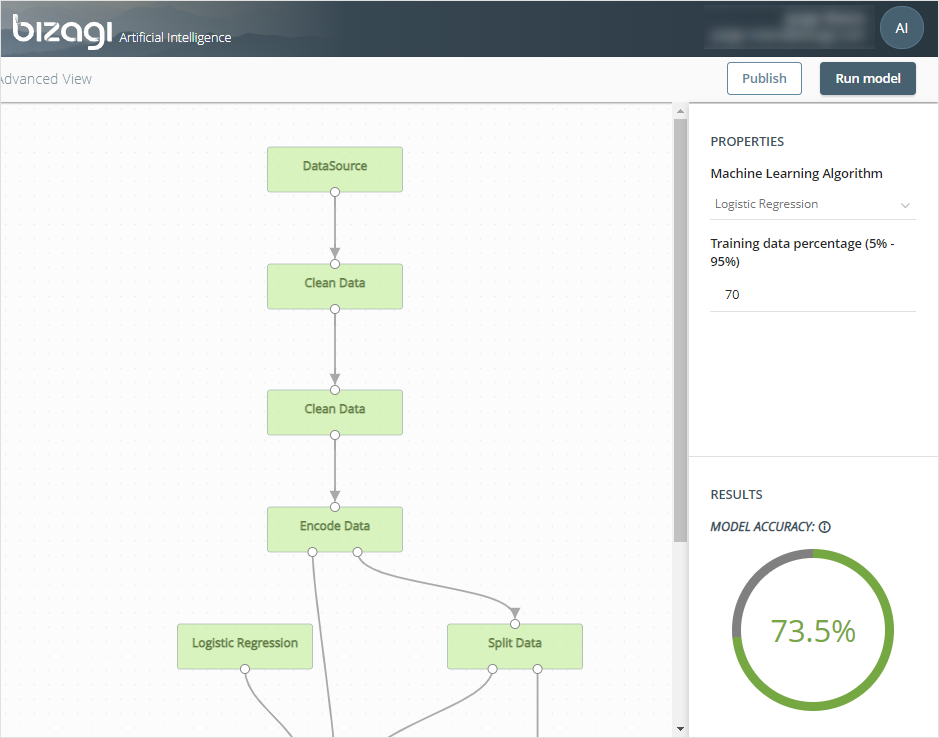
You also have a step indicating which algorithm is selected for the model. The image above shows Logistic Regression.
In a similar way and usually with fewer steps, a predictive flow is interpreted.
Click the Split Data step to see a sample of the data selected: click the View results button for either LeftTable or RightTable.
LeftTable has the data used to train the model and RightTable has the data used to test the model.
Changing Machine learning algorithm
You can use the model property Machine learning algorithms to change the algorithm to one of the following: Decision Tree Classifier, Decision Tree Binary, Linear SVM Classifier, Multiple Linear Regression or Logistic Regression:

Finally, when you are done, run the model, review its results and test it thoroughly. If the results are satisfactory, you can publish the experiment, as described in Publishing an AI experiment.