Introducción
El conector para Bizagi de Amazon Rekognition está disponible para descargar en el Connectors Xchange de Bizagi.
Con este conector puede conectar sus procesos de Bizagi a una cuenta de aws.amazon.com/rekognition para usar los servicios del API de Amazon Rekognition.
Para mayor información de las funcionalidades de este conector, visite el Connectors Xchange.
|
Este conector se encuentra actualmente en versión Beta. Úselo en ambientes de producción bajo su propio riesgo. |
Antes de empezar
Para probar y usar este conector necesitará:
1.Bizagi Studio previamente instalado.
2.Este conector previamente instalado mediante el Connectors Xchange, tal como se describe en https://help.bizagi.com/platform/en/index.html?Connectors_Xchange.htm o a través de una instalación manual como se describe en https://help.bizagi.com/platform/es/index.html?connectors_setup.htm
3.Siga los pasos descritos a continuación, usando su cuenta de Amazon Web Services (AWS):
•Vaya a https://aws.amazon.com/free/ e inicie sesión con su cuenta.
•En el panel de la izquierda haga cloc en la opción Usuarios y luego en Añadir usuario.
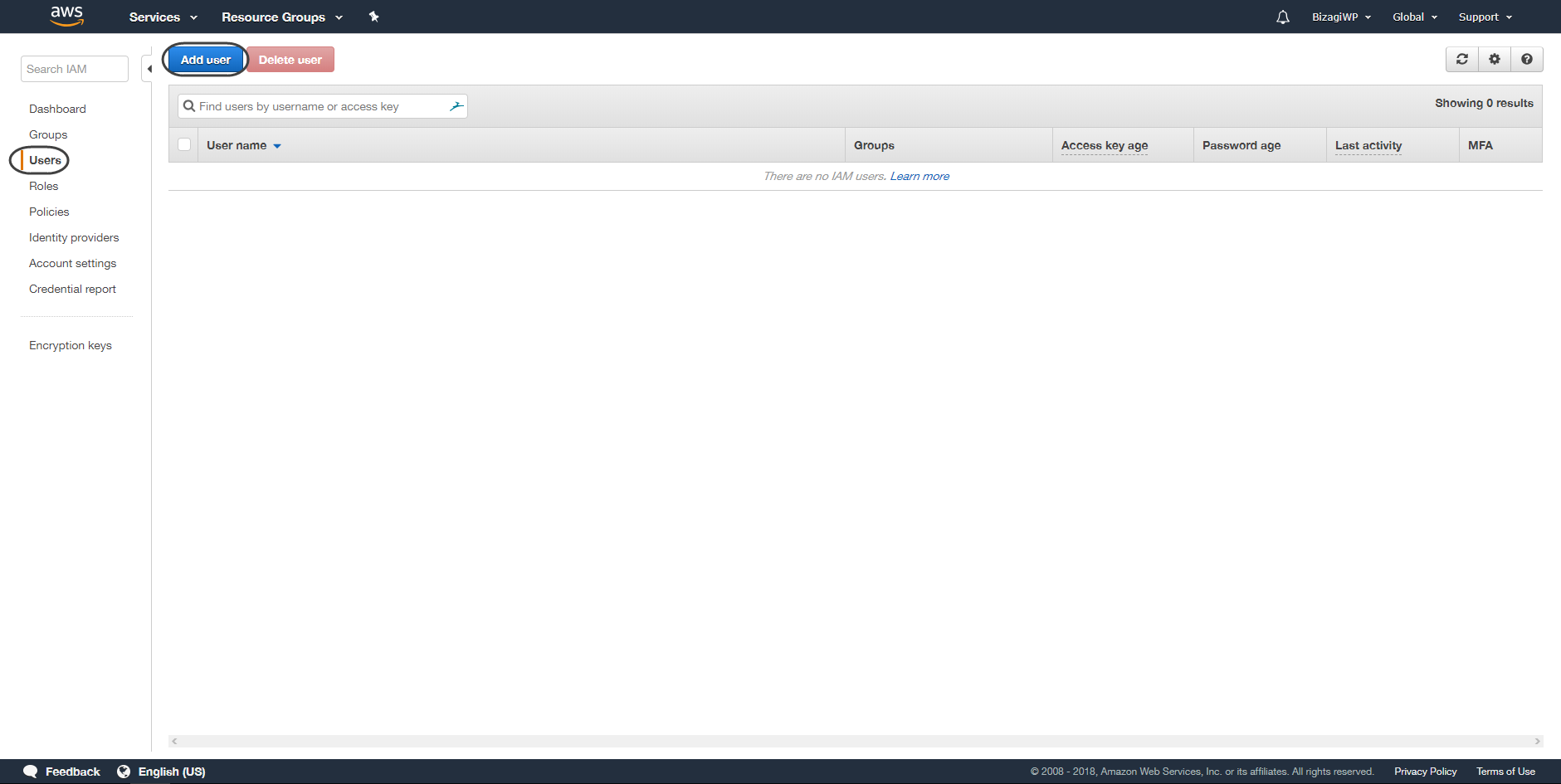
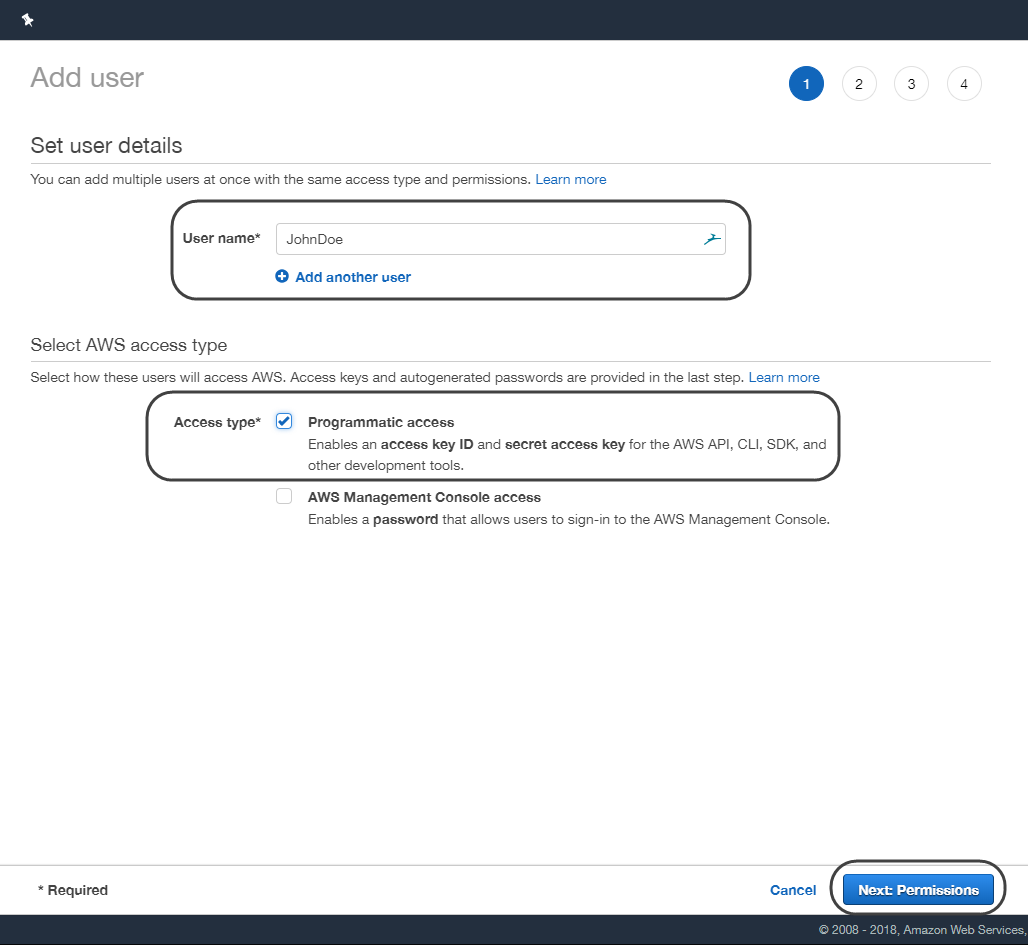
•Dele un nombre al usuario y asegúrese de seleccionar la opción de acceso programático, luego haga clic en siguiente.
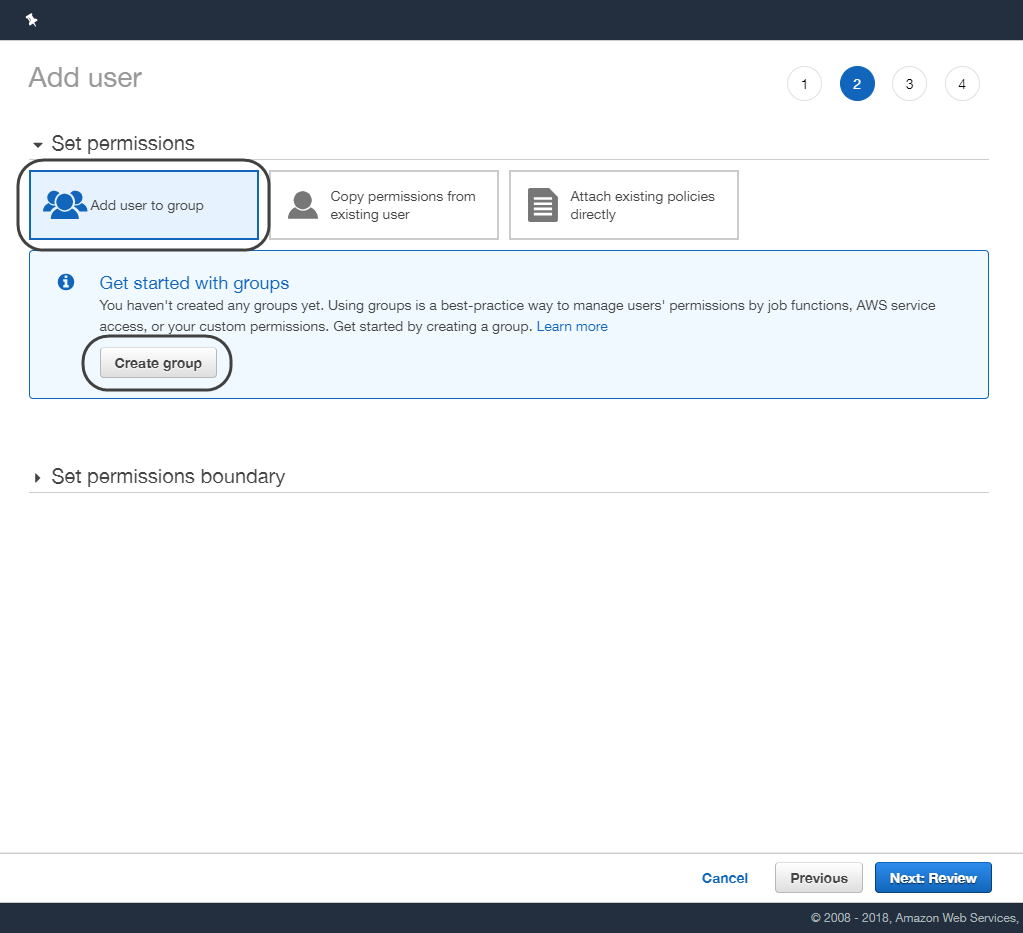
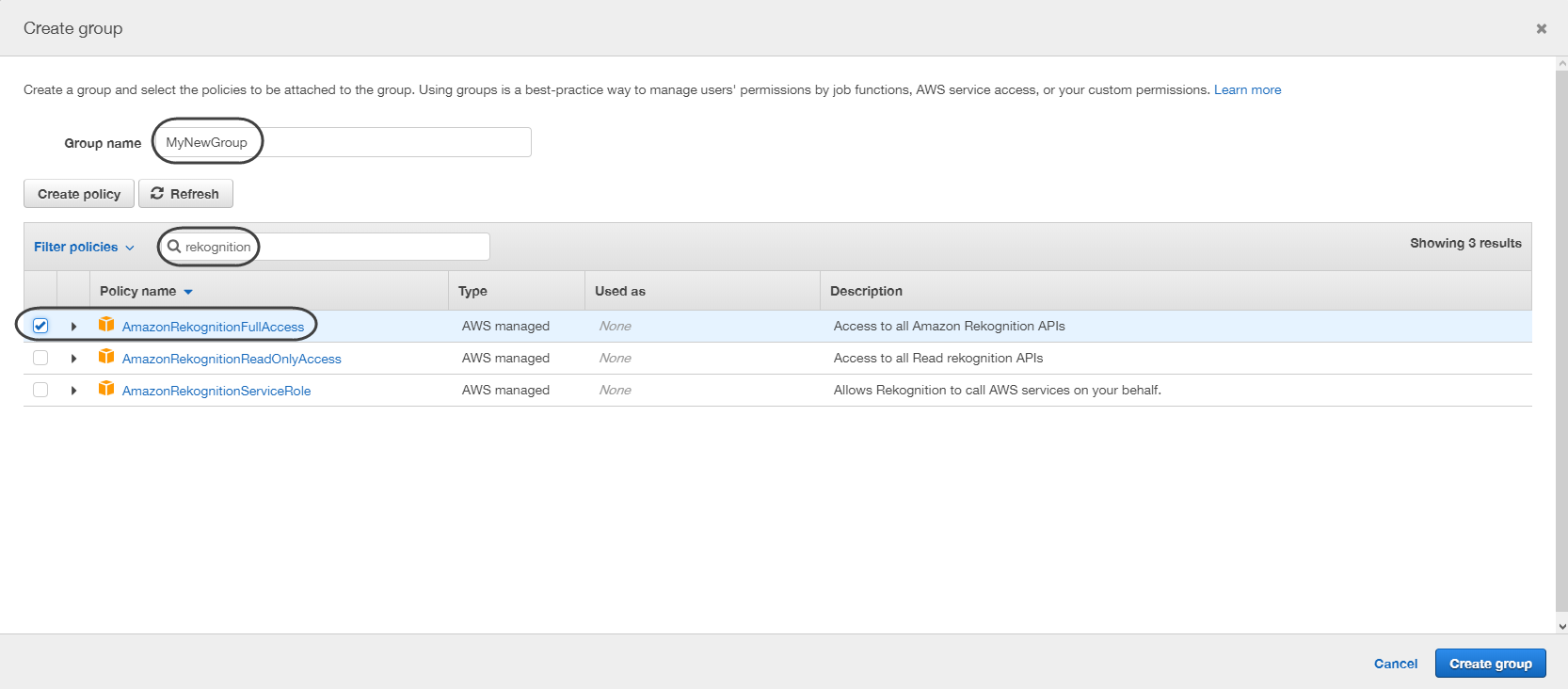
•Seleccione la opción de crear grupo, ingrese un nombre para su grupo y filtre las opciones de Rekognition asegurándose de seleccionar el elemento AmazonRekognitionFullAccess.
•En este punto se le presenta un resumen. Revise toda la información ingresada y haga clic en Crear usuario una vez que se haya asegurado de que ningún cambio es necesario.
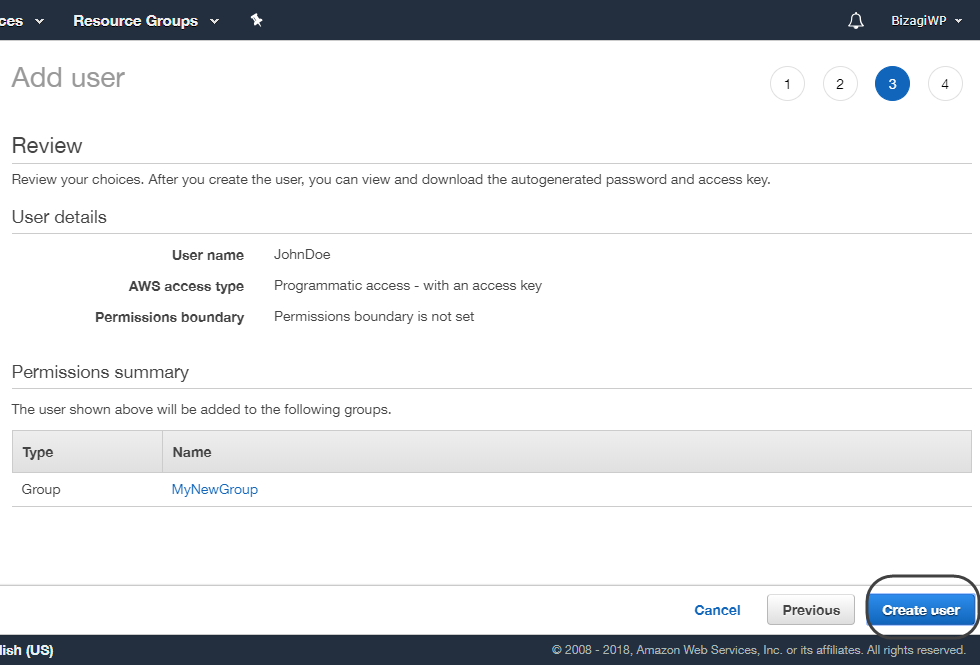
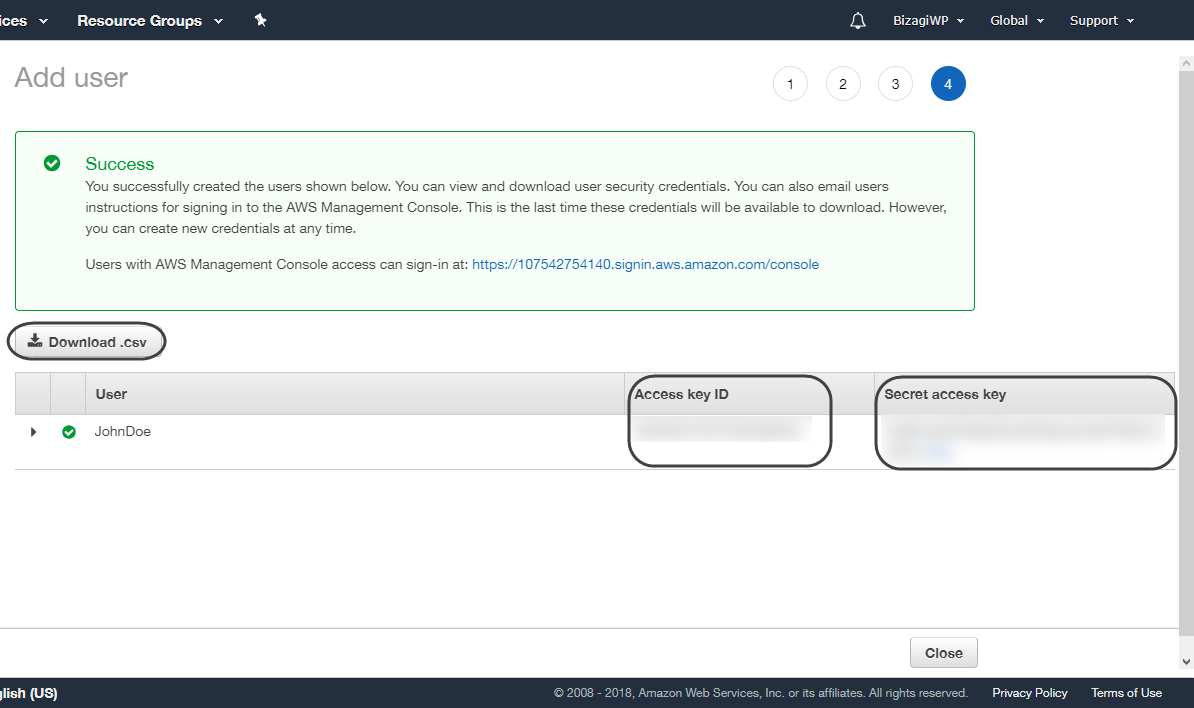
•Se le muestran los detalles del usuario creado, incluyendo un Access key ID (llave de acceso) y un Secret Access Key (llave secreta). Asegúrese de guardar esa información de manera segura, pues no será mostrada nuevamente. Para hacerlo puede tomar una captura de pantalla, escribirla en algún archivo o aprovechar la opción de Descarga de .csv para obtener un archivo que contiene dicha información.
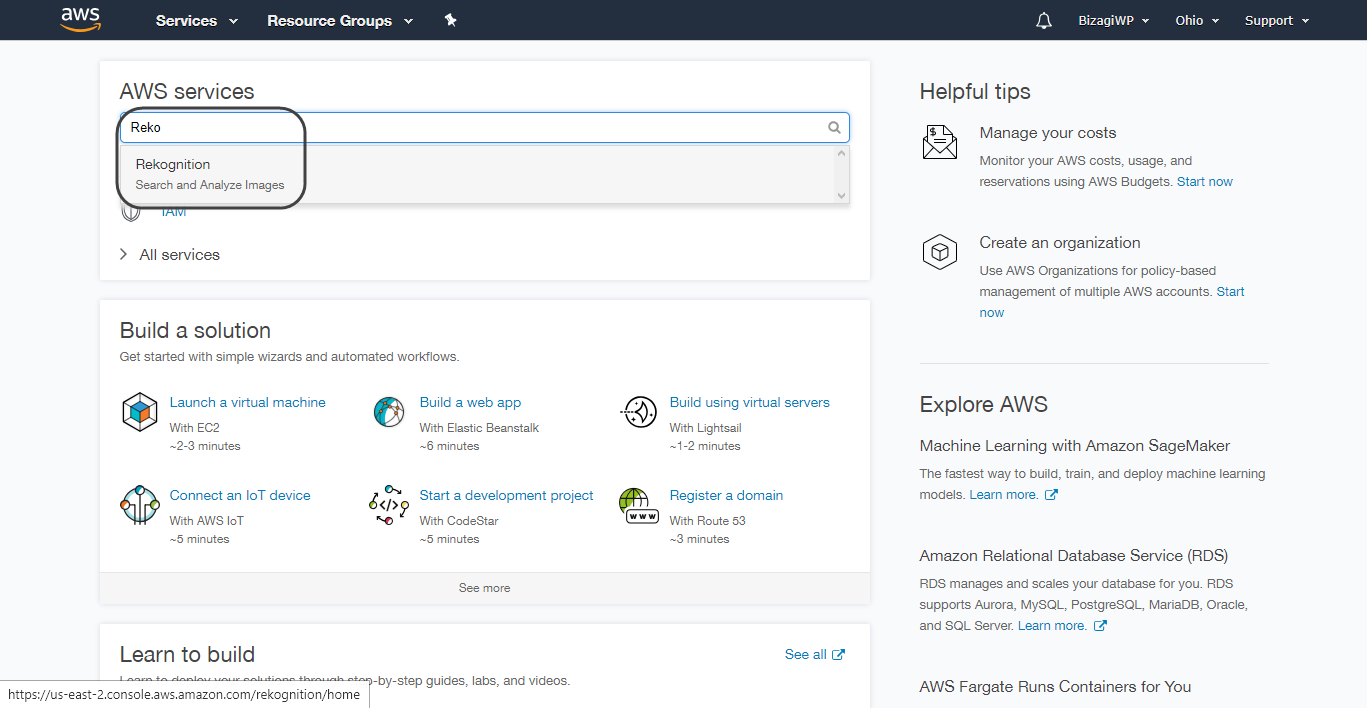
•Ahora puede acceder a la consola de AWS a través de el enlace https://us-east-2.console.aws.amazon.com/console/home?region=us-east-2. Allí, puede revisar los resultados de las acciones realizadas con el servicio.
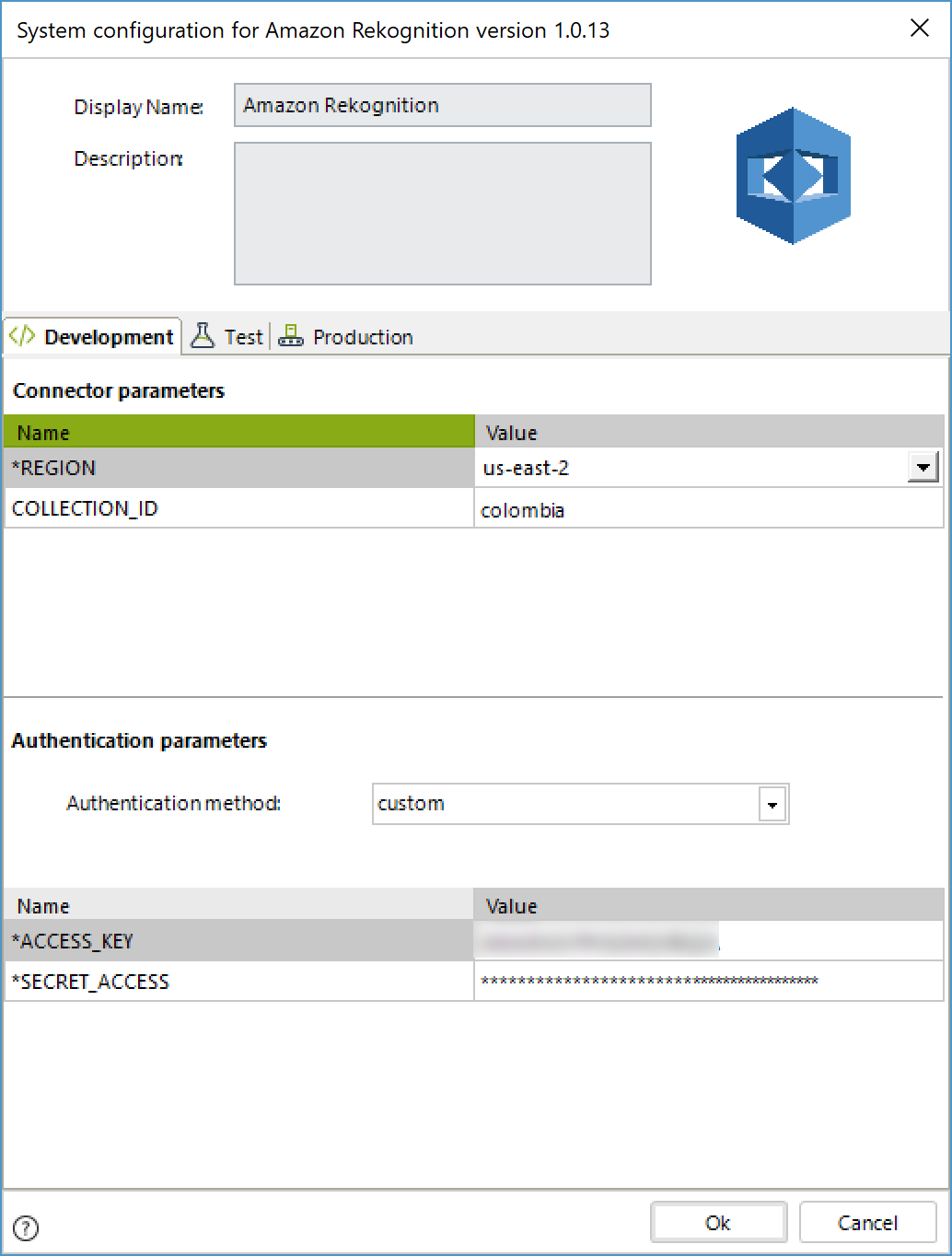
Configurar el conector
Para configurar el conector (esto es, sus parámetros de autenticación), siga los pasos presentados en el capítulo de configuración en https://help.bizagi.com/platform/es/index.html?connectors_setup.htm
Para esta configuración, considere los siguientes parámetros de autenticación:
•Método de autenticación: custom.
•ACCESS_KEY: Cadena de caracteres provista al crear el usuario (llave de acceso).
•SECRET_ACCESS: Cadena de caracteres provista al crear el usuario (llave secreta).
•REGION: Región donde se encuentra el servicio de Amazon Rekognition (por lo general es us-east-2). Se puede revisar en la URL de la consola de AWS.
•COLLECTION_ID: Colección por defecto a utilizar en las operaciones del conector.
Usar el conector
Este conector cuenta con 13 métodos disponibles de los servicios de Amazon Rekognition.
Para aprender cómo y dónde configurar el uso de un conector, refiérase a https://help.bizagi.com/platform/en/index.html?Connectors_Studio.htm.
Al usar el conector, tenga en cuenta que puede necesitar configurar entradas o salidas. Las siguientes imágenes muestran ejemplos de cómo mapear las entradas o salidas de un método.
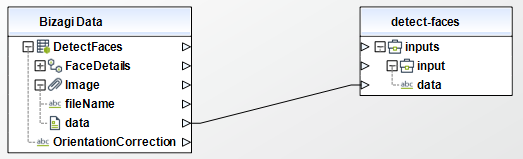
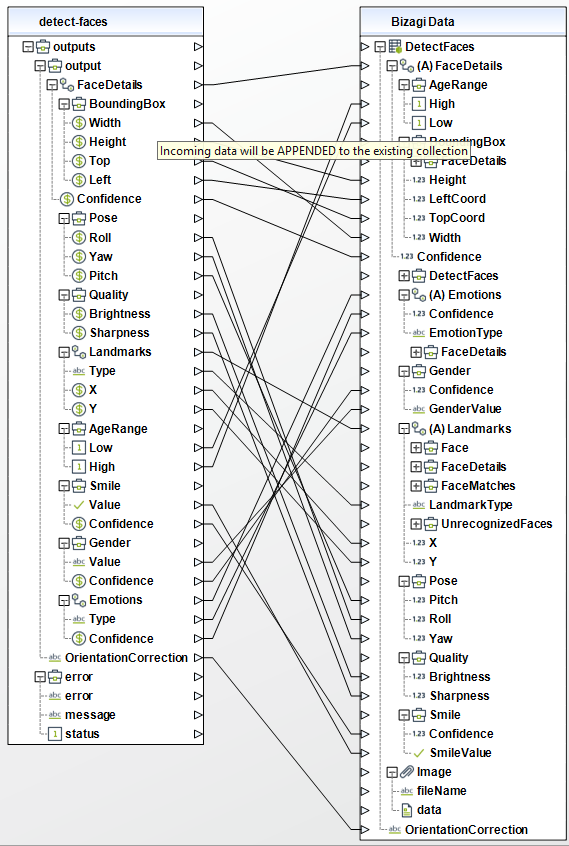
Acciones disponibles
Detectar caras (Detect faces)
Detecta caras dentro de una imagen provista como entrada.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•Data (Texto - Requerido): Imagen de entrada codificada en formato base64.
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•FaceDetails (Colección): si no detecta ninguna cara, este arreglo estará vacio.
oBoundingBox (Objeto): caja que enmarca la cara detectada.
▪Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen.
▪Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen.
▪Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen.
▪Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen.
oConfidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara.
oPose (Objeto): pose de la cara.
▪Roll (Flotante): valor que representa la rotación de la cara en el eje "roll".
▪Yaw (Flotante): valor que representa la rotación de la cara en el eje "yaw".
▪Pitch (Flotante): valor que representa la rotación de la cara en el eje "pitch".
oQuality (Objeto): calidad de la imagen procesada.
▪Brightness (Flotante): brillo de la cara. Valor entre 0 y 100. Entre más alto el valor, más brillante la cara.
▪Sharpness (Flotante): nitidez de la cara. Valor entre 0 y 100. Entre más alto el valor, mayor nitidez.
oLandmarks (Colección): ubicación de los puntos de referencia de la cara.
▪Type (Texto): tipo de Landmark. Ej: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. Básicamente son las diferentes partes que se pueden encontrar en una cara.
▪X (Flotante): coordenada x desde la esquina superior izquierda expresada como una proporción del ancho de la imagen. Ej: si la imagen es de 700x200 y la coordenada x del landmark está posicionado en 350px, este campo tendría el valor 0.5.
▪Y (Flotante): coordenada y desde la esquina superior izquierda expresada como una proporción del alto de la imagen. Ej: si la imagen es de 700x200 y la coordenada y del landmark está posicionado en 100px, este campo tendría el valor 0.5.
oAgeRange (Objeto): rango de edad de la cara.
▪Low (Entero): la edad más baja estimada.
▪High (Entero): la edad más alta estimada.
oSmile (Objeto): indica si la cara tiene una expresión de sonrisa o no, y su nivel de confianza en la determinación.
▪Value (boolean): true si está sonriendo, false si no.
▪Confidence (Flotante): nivel de confianza en la determinación de la sonrisa.
oGender (Objeto): indica el género de la cara, y su nivel de conrfianza en la deerminación.
▪Value (Texto): género de la cara. Posibles valores: "Male", "Female".
▪Confidence (Flotante): nivel de confianza en la determinación del género.
oEmotions (Colección): emociones que expresa la cara, y su nivel de confianza en la determinación.
▪Type (Texto): tipo de emoción detectada. Posibles valores: "HAPPY", "SAD", "ANGRY", "CONFUSED", "DISGUSTED", "SURPRISED", "CALM", "UNKNOWN".
▪Confidence (Flotante): nivel de confianza en la determinación de la emoción.
•OrientationCorrection (Texto): la orientación de la imagen. Posibles valores: "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". Si los metadatos de la imagen contienen la orientación, Rekognition no realiza corrección de orientación y el valor de este campo es NULL.
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#detectFaces-property.
Detectar texto (Detect text)
Detecta texto en la imagen de entrada y lo convierte en texto legible por máquinas.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•Data (Texto - Requerido): Imagen de entrada codificada en formato base64.
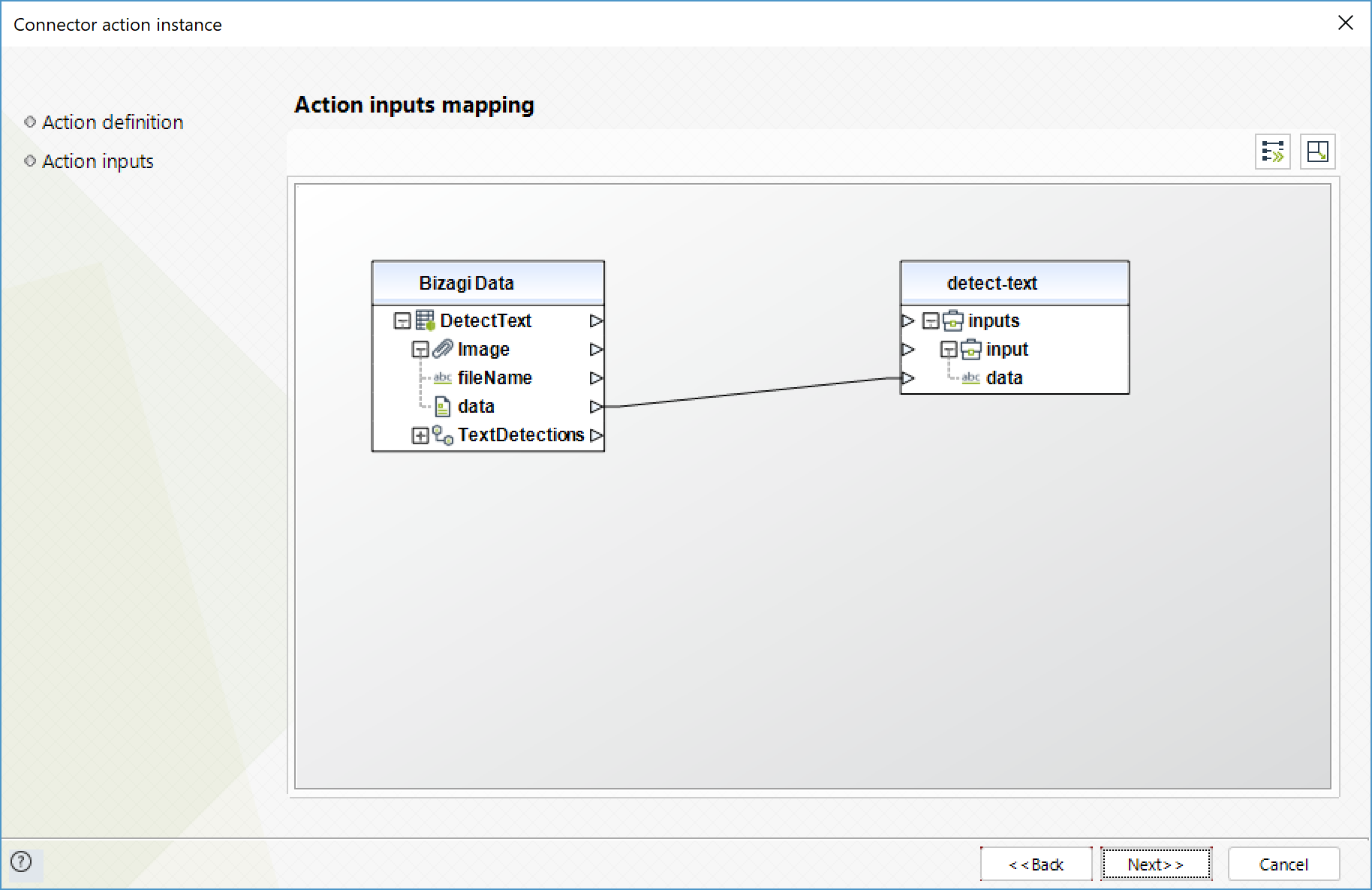
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•TextDetections (Colección): colección con los textos que se encontraron en la imagen.
oDetectedText (Texto): texto detectado.
oType (Texto): tipo del texto que fue detectado. Posibles valores: "LINE", "WORD".
oConfidence (Flotante): nivel de confianza sobre el texto identificado.
oID (Entero): el identificador del texto detectado.
oParentId (Entero): el identificador del parent del texto detectado por el valor de ID. Si el tipo de texto detectado es "LINE", el valor de ParentId es NULL.
oGeometry (Objeto): ubicación del texto en la imagen.
▪BoundingBox (Objeto): caja que enmarca el texto detectado.
•Width (Flotante): ancho de la caja que rodea el texto como una proporción del ancho total de la imagen.
•Height (Flotante): alto de la caja que rodea el texto como una proporción del alto total de la imagen.
•Left (Flotante): coordenada (izquierda) de la caja que rodea el texto como una poporción del ancho total de la imagen.
•Top (Flotante): coordenada (arriba) de la caja que rodea el texto como una poporción del ancho total de la imagen.
▪Polygon (Colección): dentro del BoundingBox un poligono con mayor precision alrededor del texto detectado.
•X (Flotante): coordenada X de un punto del poligono.
•Y (Flotante): coordenada Y de un punto del poligono.
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#detectText-property.
Detectar etiquetas (Detect labels)
Detectar instancias de entidades del mundo real dentro de una imagen (JPEG o PNG) como entrada. Reconoce objetos, eventos y conceptos.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•Data (Texto - Requerido): Imagen de entrada codificada en formato base64.
•MaxLabels (Entero): Número máximo de etiquetas a ser retornadas.
•MinConfidence (Flotante): Nivel de confianza mínimo para que una etiqueta sea retornada. Su valor por defecto es 50%.
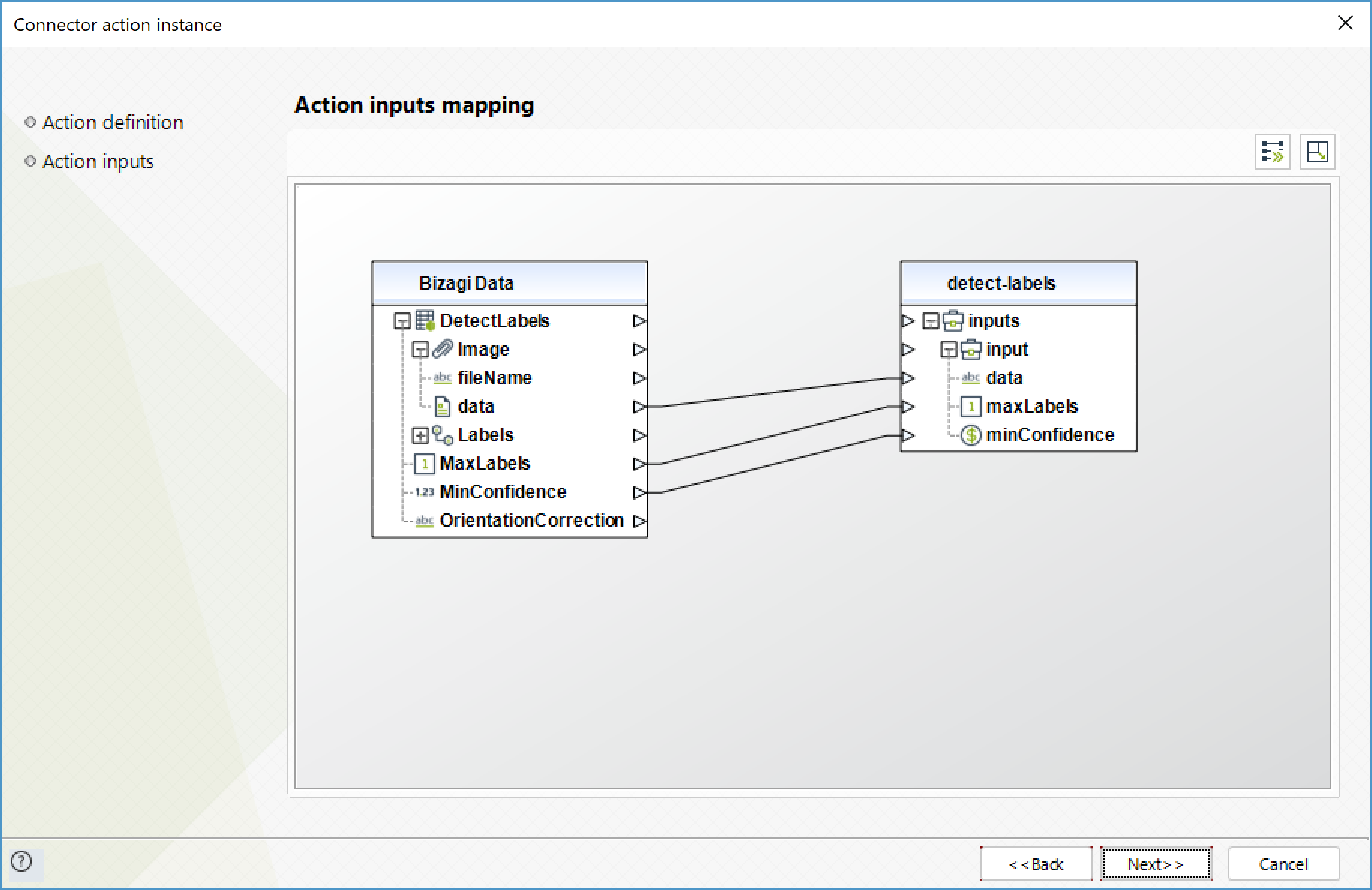
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•Labels (Colección): colección de las etiquetas encontradas.
oName (Texto): nombre (label) del objeto detectado
oConfidence (Flotante): nivel de confianza
•OrientationCorrection (Texto): la orientación de la imagen. Posibles valores: "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". Si los metadatos de la imagen contienen la orientación, Rekognition no realiza corrección de orientación y el valor de este campo es NULL.
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#detectLabels-property.
Reconocer famosos (Recognize celebrities)
Retorna una lista de los famosos reconocidos en la imagen de entrada.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•Data (Texto - Requerido): imagen de entrada codificada en formato base64.
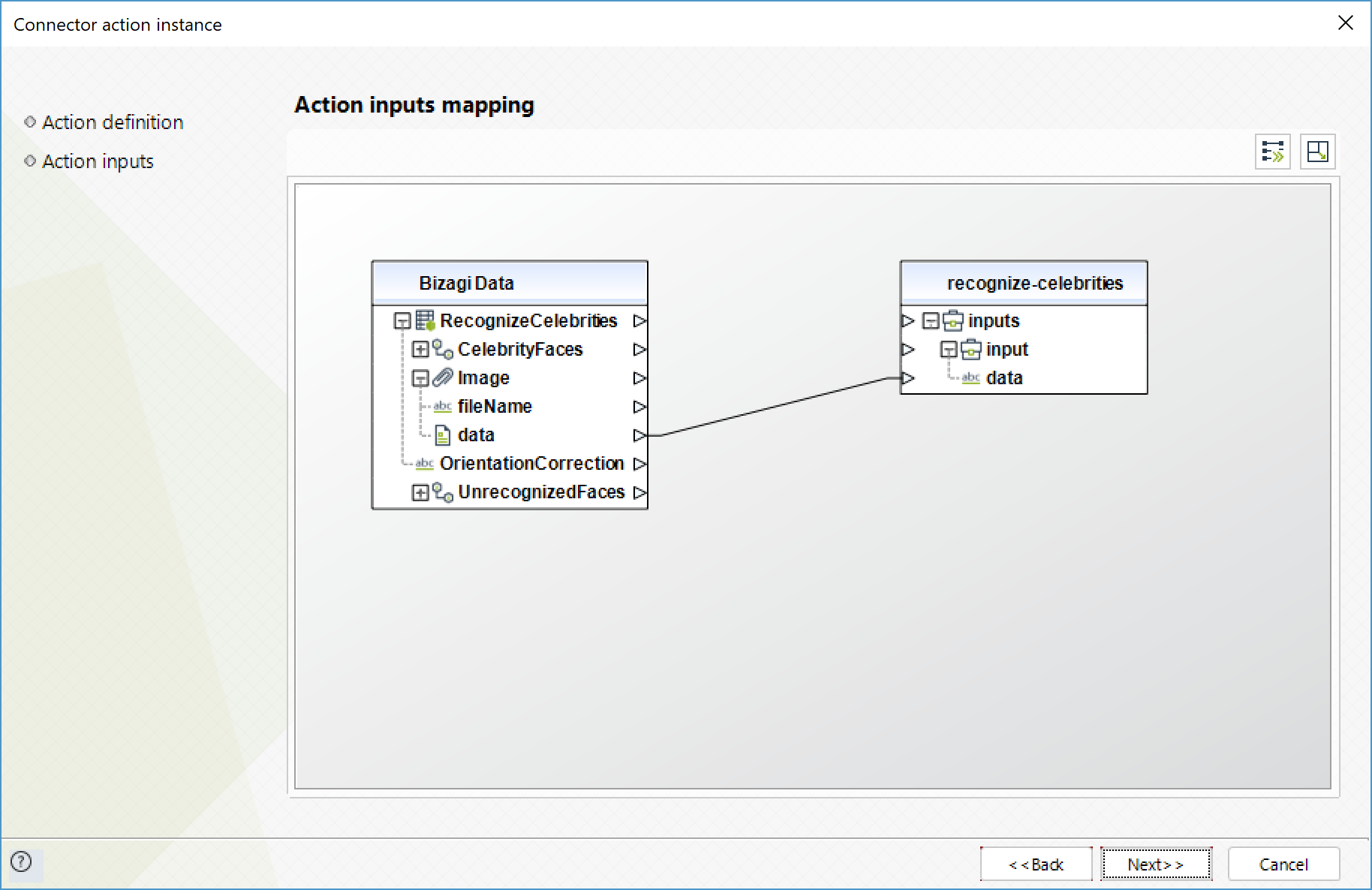
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•CelebrityFaces (Colección): arreglo de las celibridades identificadas. El método identifica máximo 15 celebridades.
oUrls (Colección): arrays de URLs que apuntan a información adicional sobre la celebridad reconocida. Si no hay información adicional de la celebridad, esta lista estará vacia.
oName (Texto): nombre de la celebridad
oId (Texto): identificador unico de la celebridad
oFace (Objeto): cara de la celebridad
▪BoundingBox (Objeto): caja que enmarca la cara detectada.
•Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
•Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
•Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
•Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
•Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
▪Pose (Objeto): pose de la cara.
•Roll (Flotante): valor que representa la rotación de la cara en el eje "roll"
•Yaw (Flotante): valor que representa la rotación de la cara en el eje "yaw"
•Pitch (Flotante): valor que representa la rotación de la cara en el eje "pitch"
▪Quality (Objeto): calidad de la imagen procesada.
•Brightness (Flotante): brillo de la cara. Valor entre 0 y 100. Entre más alto el valor, más brillante la cara.
•Sharpness (Flotante): nitidez de la cara. Valor entre 0 y 100. Entre más alto el valor, mayor nitidez.
▪Landmarks (Colección): ubicación de los puntos de referencia de la cara.
•Type (Texto): tipo de Landmark. Ej: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. Básicamente son las diferentes partes que se pueden encontrar en una cara.
•X (Flotante): coordenada x desde la esquina superior izquierda expresada como una proporción del ancho de la imagen. Ej: si la imagen es de 700x200 y la coordenada x del landmark está posicionado en 350px, este campo tendría el valor 0.5
•Y (Flotante): coordenada y desde la esquina superior izquierda expresada como una proporción del alto de la imagen. Ej: si la imagen es de 700x200 y la coordenada y del landmark está posicionado en 100px, este campo tendría el valor 0.5
▪MatchConfidence (Flotante): confianza, en porcentaje, que Rekognition ha reconocido que la cara es de una celebridad
•UnrecognizedFaces (Colección): colección con las caras que no fueron identificadas como celebridades.
oBoundingBox (Objeto): caja que enmarca la cara detectada.
▪Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
▪Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
▪Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
oPose (Objeto): pose de la cara.
▪Roll (Flotante): valor que representa la rotación de la cara en el eje "roll"
▪Yaw (Flotante): valor que representa la rotación de la cara en el eje "yaw"
▪Pitch (Flotante): valor que representa la rotación de la cara en el eje "pitch"
oQuality (Objeto): calidad de la imagen procesada.
▪Brightness (Flotante): brillo de la cara. Valor entre 0 y 100. Entre más alto el valor, más brillante la cara.
▪Sharpness (Flotante): nitidez de la cara. Valor entre 0 y 100. Entre más alto el valor, mayor nitidez.
oLandmarks (Colección): ubicación de los puntos de referencia de la cara.
▪Type (Texto): tipo de Landmark. Ej: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. Básicamente son las diferentes partes que se pueden encontrar en una cara.
▪X (Flotante): coordenada x desde la esquina superior izquierda expresada como una proporción del ancho de la imagen. Ej: si la imagen es de 700x200 y la coordenada x del landmark está posicionado en 350px, este campo tendría el valor 0.5
▪Y (Flotante): coordenada y desde la esquina superior izquierda expresada como una proporción del alto de la imagen. Ej: si la imagen es de 700x200 y la coordenada y del landmark está posicionado en 100px, este campo tendría el valor 0.5
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#recognizeCelebrities-property.
Comparar caras (Compare faces)
Compara una cara de la imagen de entrada con cada una de las 100 caras mas grandes detectadas en la imagen objetivo.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•SourceImage (Colección - Requerido): Imagen de entrada de una cara codificada en formato base64. De haber 2 o mas caras, la mas grande será considerada.
•TargetImage (Colección - Requerido): Imagen de entrada en la que la imagen anterior será buscada, codificada en formato base64.
•similarityThreshold (Flotante): Nivel de confianza mínimo para que una cara detectada sea incluida en la respuesta.
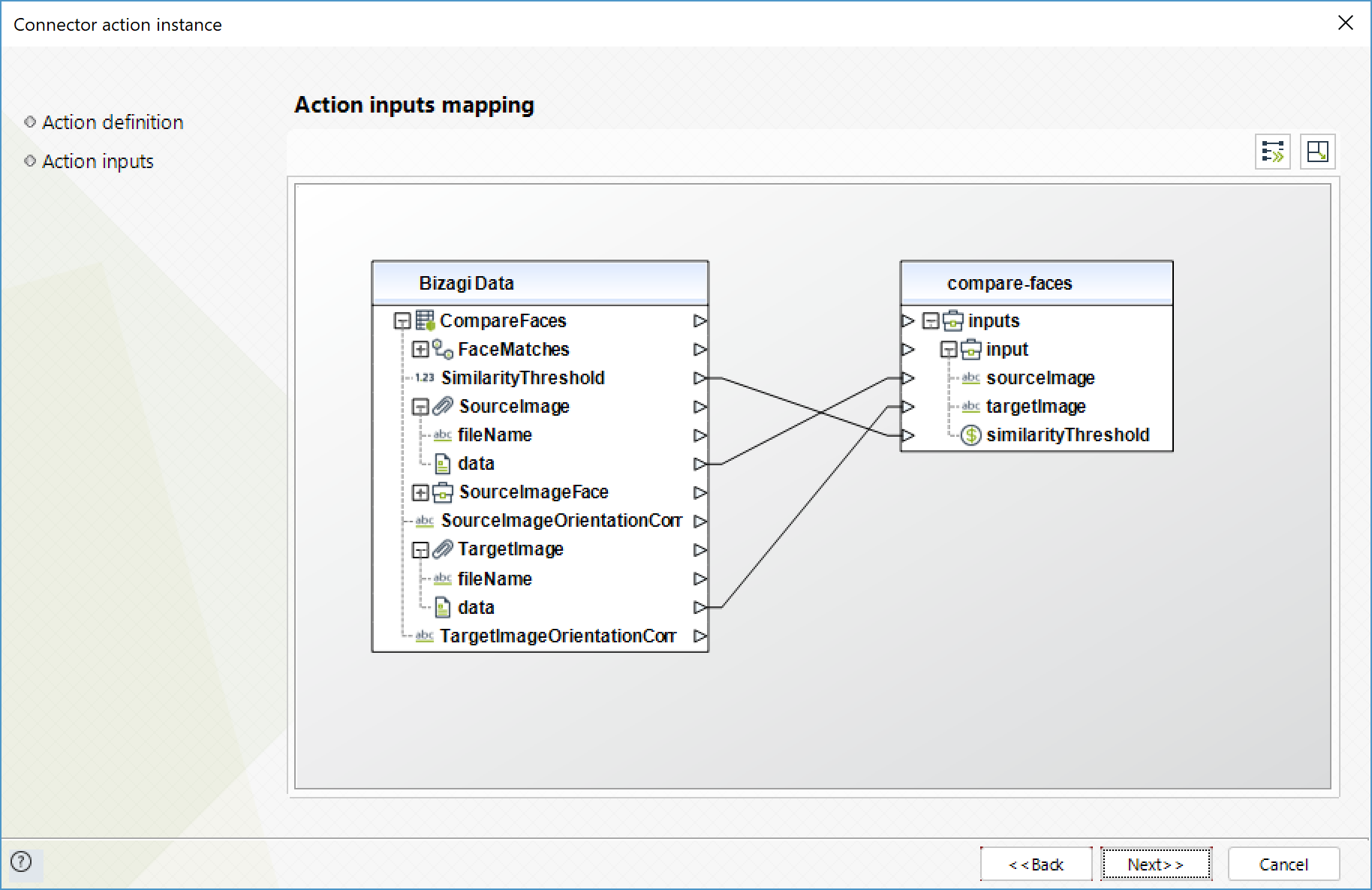
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•SourceImageFace (Objeto): cara detectada en la imagen principal utilizada para la comparación
oBoundingBox (Objeto): caja que enmarca la cara detectada.
▪Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
▪Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
▪Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
•FaceMatches (Colección): arreglo de caras encontradas en la imagen secundaria, que coinciden con la cara de la imagen primaria.
oSimilarity (Flotante): nivel de confianza que las caras hacen match
oFace (Objeto): cara detectada
▪BoundingBox (Objeto): caja que enmarca la cara detectada.
•Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
•Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
•Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
•Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
•Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
▪Pose (Objeto): pose de la cara.
•Roll (Flotante): valor que representa la rotación de la cara en el eje "roll"
•Yaw (Flotante): valor que representa la rotación de la cara en el eje "yaw"
•Pitch (Flotante): valor que representa la rotación de la cara en el eje "pitch"
▪Quality (Objeto): calidad de la imagen procesada.
•Brightness (Flotante): brillo de la cara. Valor entre 0 y 100. Entre más alto el valor, más brillante la cara.
•Sharpness (Flotante): nitidez de la cara. Valor entre 0 y 100. Entre más alto el valor, mayor nitidez.
▪Landmarks (Colección): ubicación de los puntos de referencia de la cara.
•Type (Texto): tipo de Landmark. Ej: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. Básicamente son las diferentes partes que se pueden encontrar en una cara.
•X (Flotante): coordenada x desde la esquina superior izquierda expresada como una proporción del ancho de la imagen. Ej: si la imagen es de 700x200 y la coordenada x del landmark está posicionado en 350px, este campo tendría el valor 0.5
•Y (Flotante): coordenada y desde la esquina superior izquierda expresada como una proporción del alto de la imagen. Ej: si la imagen es de 700x200 y la coordenada y del landmark está posicionado en 100px, este campo tendría el valor 0.5
•SourceImageOrientationCorrection (Texto): la orientación de la imagen source. Posibles valores: "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". Si los metadatos de la imagen contienen la orientación, Rekognition no realiza corrección de orientación y el valor de este campo es NULL.
•TargetImageOrientationCorrection (Texto): la orientación de la imagen target. Posibles valores: "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". Si los metadatos de la imagen contienen la orientación, Rekognition no realiza corrección de orientación y el valor de este campo es NULL.
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#compareFaces-property.
Crear colección (Create collection)
Crea una colección en una región de AWS. Puede añadir caras a la colección en la misma operaciones.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•CollectionID (Texto - Requerido): ID de la colección a crear, es sensible a mayúsculas y minúsculas.
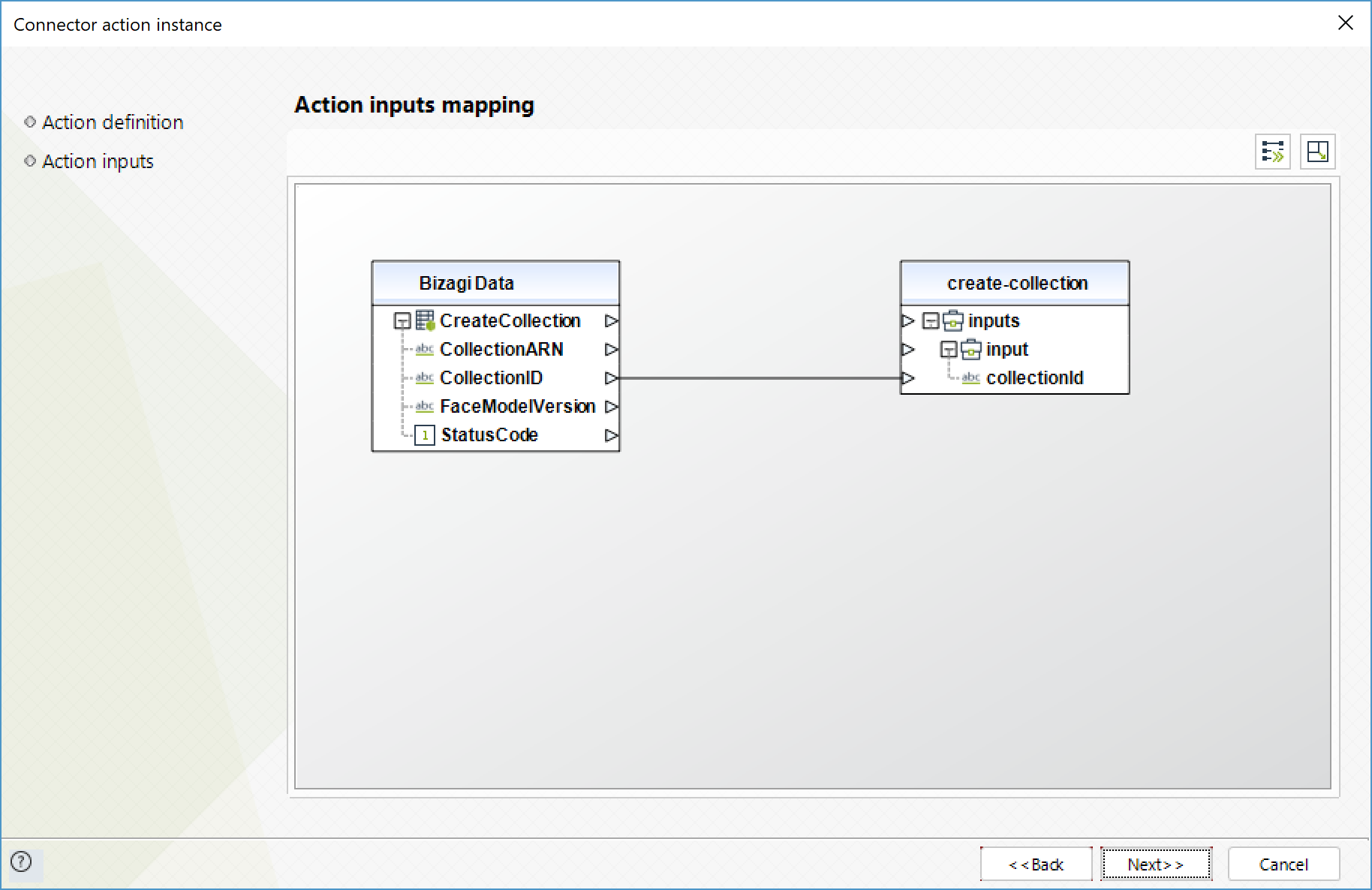
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•StatusCode (Entero): codigo HTTP indicando el resultado de la operación
•CollectionArn (Texto): el Amazon Resource Name (ARN) de la colección
•FaceModelVersion (Texto): número de la versión del modelo de detección de caras asociado a la colección que se creó
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#createCollection-property.
Listar colecciones (List collections)
Retorna una lista de IDs de colecciones pertenecientes a su cuenta. Si el resultado es truncado, la respuesta tambien provee un NextToken (Token siguiente) que puede usar en una petición sub-siguiente para traer la siguiente parte de la lista de IDs de colecciones.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•MaxResults (Entero): Cantidad máxima de resultados a traer.
•NextToken (Texto): Token de paginación del resultado previo.
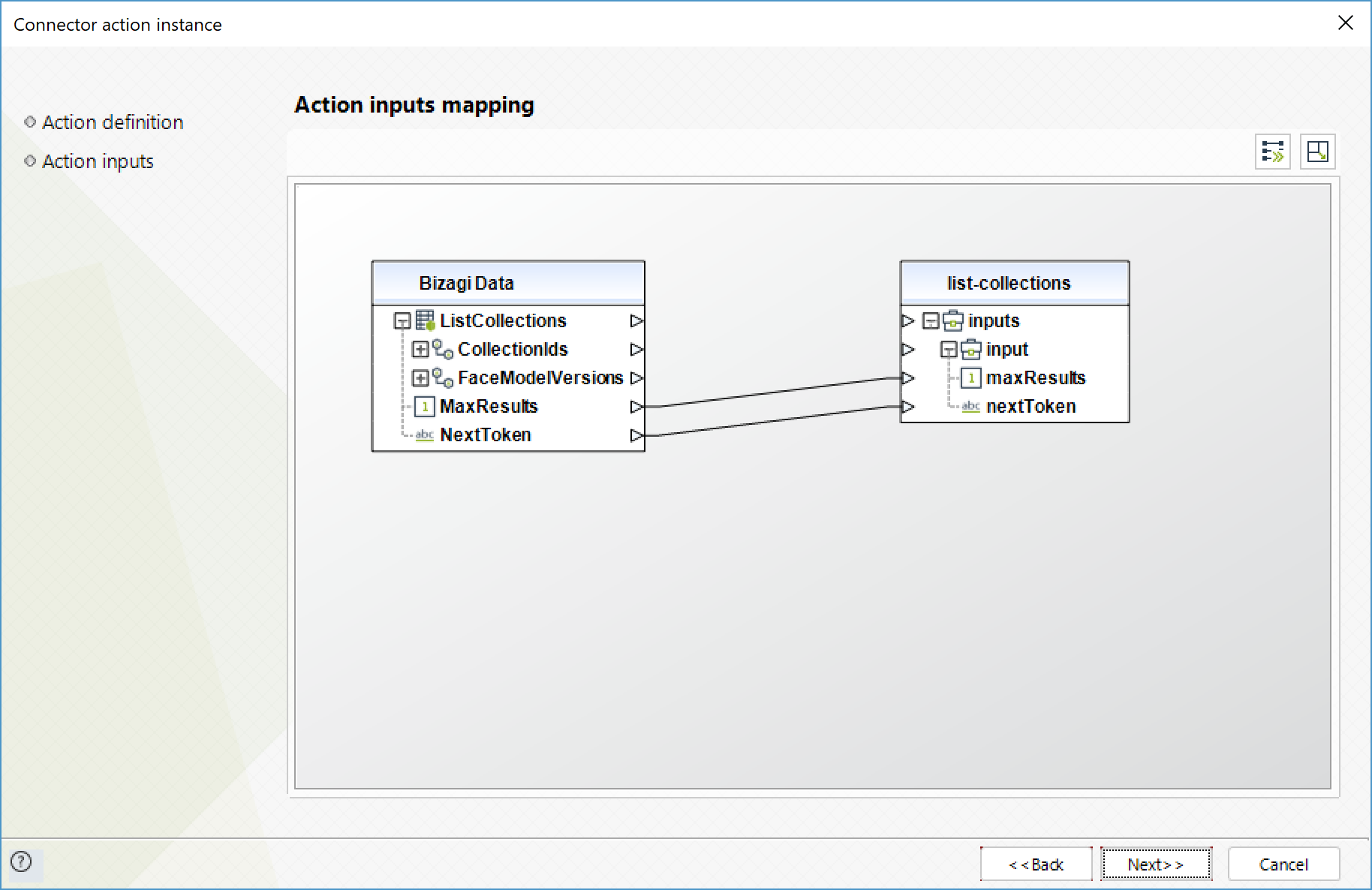
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•CollectionIds (Colección): un array de los IDs de las colecciones
•NextToken (Texto): si el resultado está truncado, la respuesta provee este valor para utilizarlo en peticiones subsecuentes para buscar el siguiente conjunto de IDs de colecciones
•FaceModelVersions (Colección): números de las versiones de los modelos de detección de caras asociados con las colecciones en el arreglo CollectionIds. Ej: el valor de FaceModelVersions[2] corresponde a la versión del modelo de detección utilizado por la colección CollectionIds[2]
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#listCollections-property.
Eliminar colección (Delete collection)
Elimina la colección especificada.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•CollectionID (Texto - Requerido): ID de la colección a eliminar.
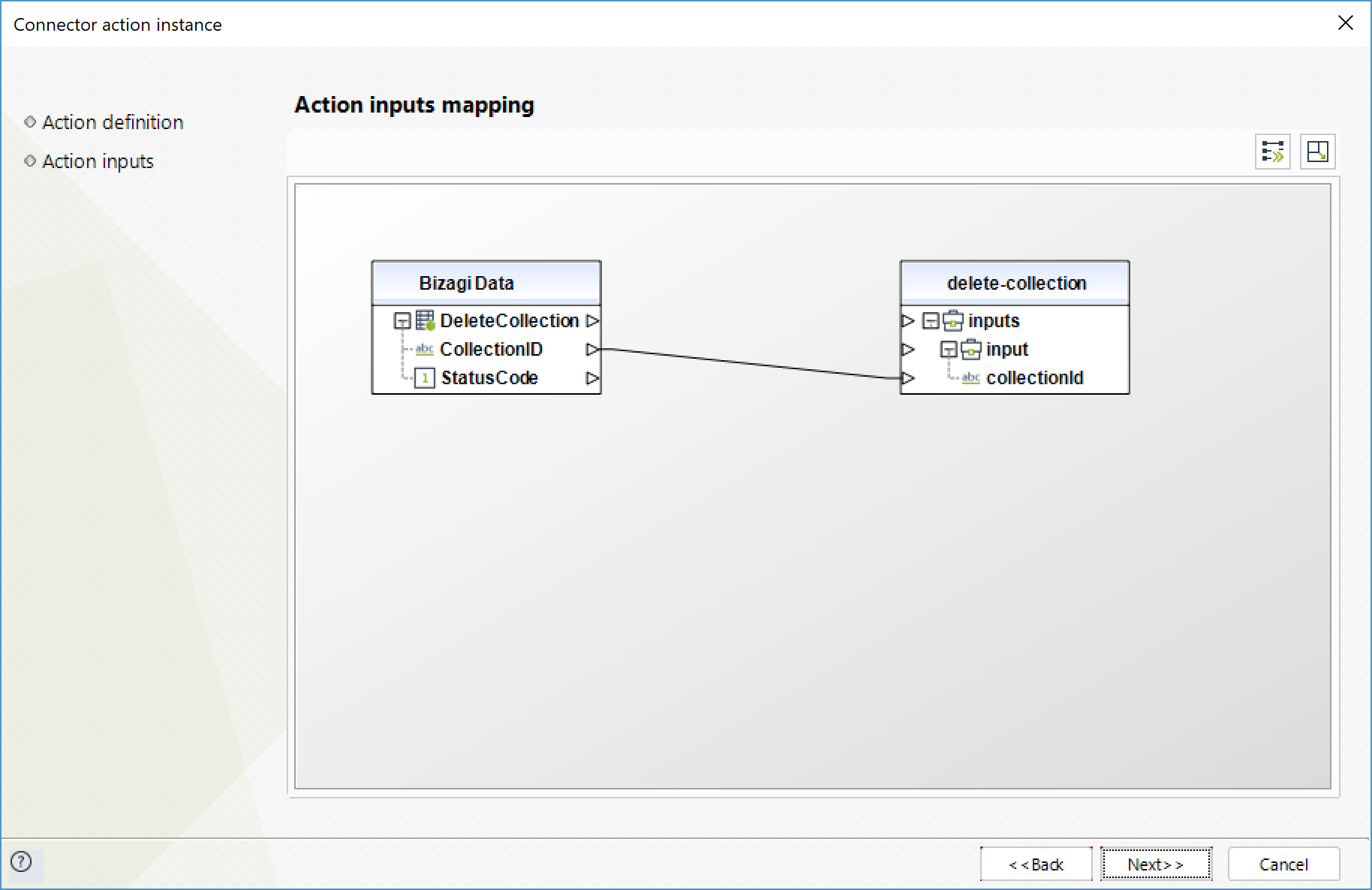
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•StatusCode (Entero): codigo HTTP indicando el resultado de la operación
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#deleteCollection-property.
Indexar caras (Index faces)
Detecta caras en la imagen de entrada y las añade a la colección especificada.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•CollectionID (Texto - Requerido): ID de la colección a la que se vana a añadir caras.
•Data (Texto - Requerido): imagen de entrada codificada en formato base64.
•ExternalImageId (Texto): ID a asignar a todas las caras detectadas.
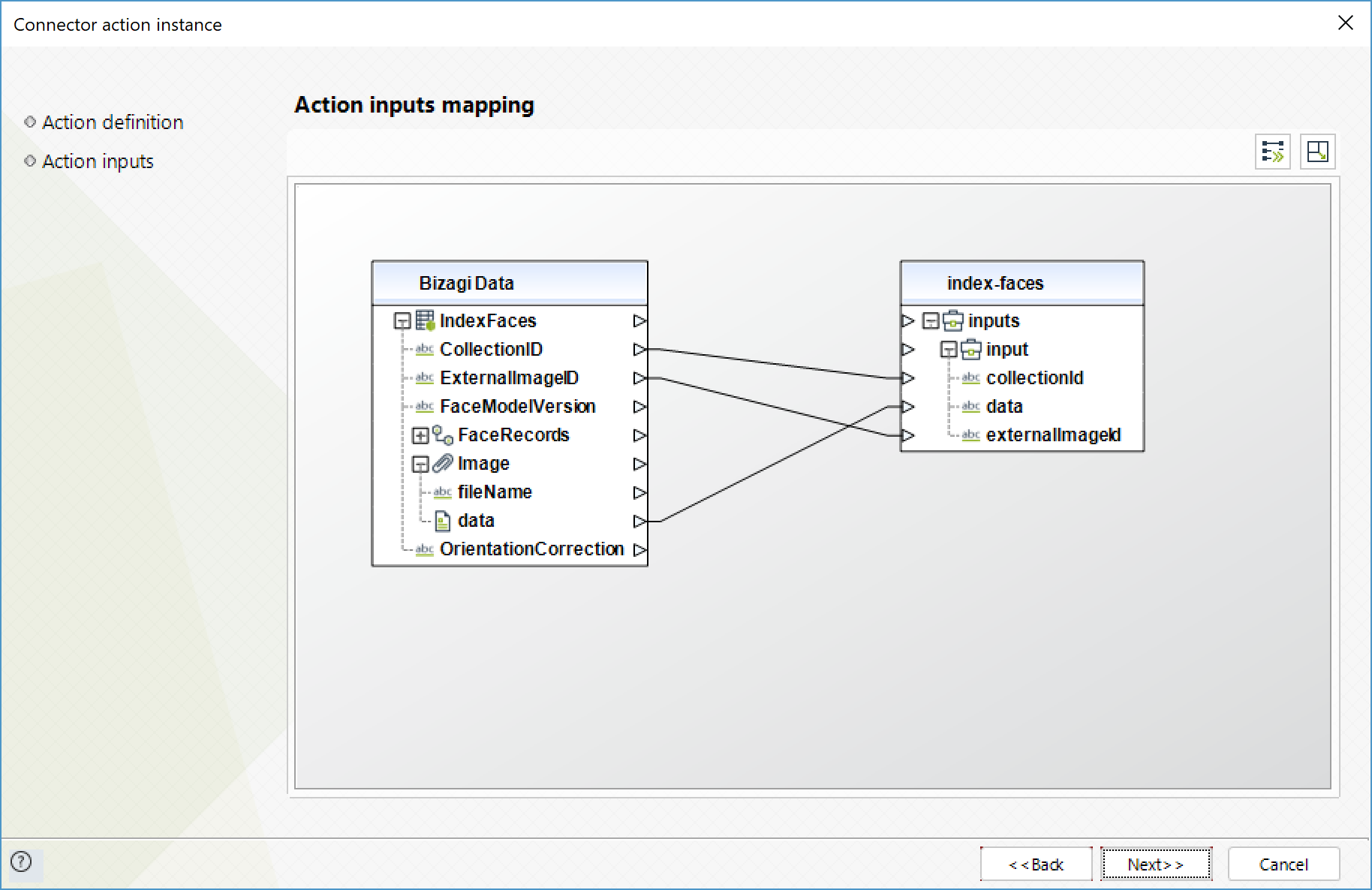
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•FaceRecords (Colección): colección de las caras detectadas y agregadas a la colección.
oFace (Objeto): cara detectada.
▪FaceId (Texto): identificador unico que Amazon Rekognition le asigna a la cara
▪ImageId (Texto): identificador unico que Amazon Rekognition le asigna a la imagen de entrada
▪ExternalImageId (Texto): identificador que se asigna a todas las caras de la imagen de entrada (si se especificó la entrada externalImageId)
▪Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
oFaceDetails (Colección): si no detecta ninguna cara, este arreglo estará vacio
▪BoundingBox (Objeto): caja que enmarca la cara detectada.
•Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
•Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
•Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
•Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
▪Pose (Objeto): pose de la cara.
•Roll (Flotante): valor que representa la rotación de la cara en el eje "roll"
•Yaw (Flotante): valor que representa la rotación de la cara en el eje "yaw"
•Pitch (Flotante): valor que representa la rotación de la cara en el eje "pitch"
▪Quality (Objeto): calidad de la imagen procesada.
•Brightness (Flotante): brillo de la cara. Valor entre 0 y 100. Entre más alto el valor, más brillante la cara.
•Sharpness (Flotante): nitidez de la cara. Valor entre 0 y 100. Entre más alto el valor, mayor nitidez.
▪Landmarks (Colección): ubicación de los puntos de referencia de la cara.
•Type (Texto): tipo de Landmark. Ej: "eyeLeft", "nose", "leftEyeBrowLeft", "mouthUp", etc. Básicamente son las diferentes partes que se pueden encontrar en una cara.
•X (Flotante): coordenada x desde la esquina superior izquierda expresada como una proporción del ancho de la imagen. Ej: si la imagen es de 700x200 y la coordenada x del landmark está posicionado en 350px, este campo tendría el valor 0.5
•Y (Flotante): coordenada y desde la esquina superior izquierda expresada como una proporción del alto de la imagen. Ej: si la imagen es de 700x200 y la coordenada y del landmark está posicionado en 100px, este campo tendría el valor 0.5
▪AgeRange (Objeto): rango de edad de la cara.
•Low (Entero): la edad más baja estimada
•High (Entero): la edad más alta estimada
▪Smile (Objeto): indica si la cara tiene una expresión de sonrisa o no, y su nivel de confianza en la determinación.
•Value (boolean): true si está sonriendo, false si no.
•Confidence (Flotante): nivel de confianza en la determinación de la sonrisa
▪Gender (Objeto): indica el género de la cara, y su nivel de conrfianza en la deerminación.
•Value (Texto): género de la cara. Posibles valores: "Male", "Female".
•Confidence (Flotante): nivel de confianza en la determinación del género
▪Emotions (Colección): emociones que expresa la cara, y su nivel de confianza en la determinación.
•Type (Texto): tipo de emoción detectada. Posibles valores: "HAPPY", "SAD", "ANGRY", "CONFUSED", "DISGUSTED", "SURPRISED", "CALM", "UNKNOWN".
•Confidence (Flotante): nivel de confianza en la determinación de la emoción
oOrientationCorrection (Texto): la orientación de la imagen. Posibles valores: "ROTATE_0", "ROTATE_90", "ROTATE_180", "ROTATE_270". Si los metadatos de la imagen contienen la orientación, Rekognition no realiza corrección de orientación y el valor de este campo es NULL.
oFaceModelVersion (Texto): número de la versión del modelo de detección de caras asociado a la colección de entrada (collectionId)
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#indexFaces-property.
Listar caras (List faces)
Retorna la metada de las caras de la colección especificada.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•CollectionID (Texto - Requerido): ID de la colección de las caras que se van a listar.
•MaxResults (Entero): Número máximo de resultados retornados.
•NextToken (Flotante): Token de paginación de la respuesta anterior.
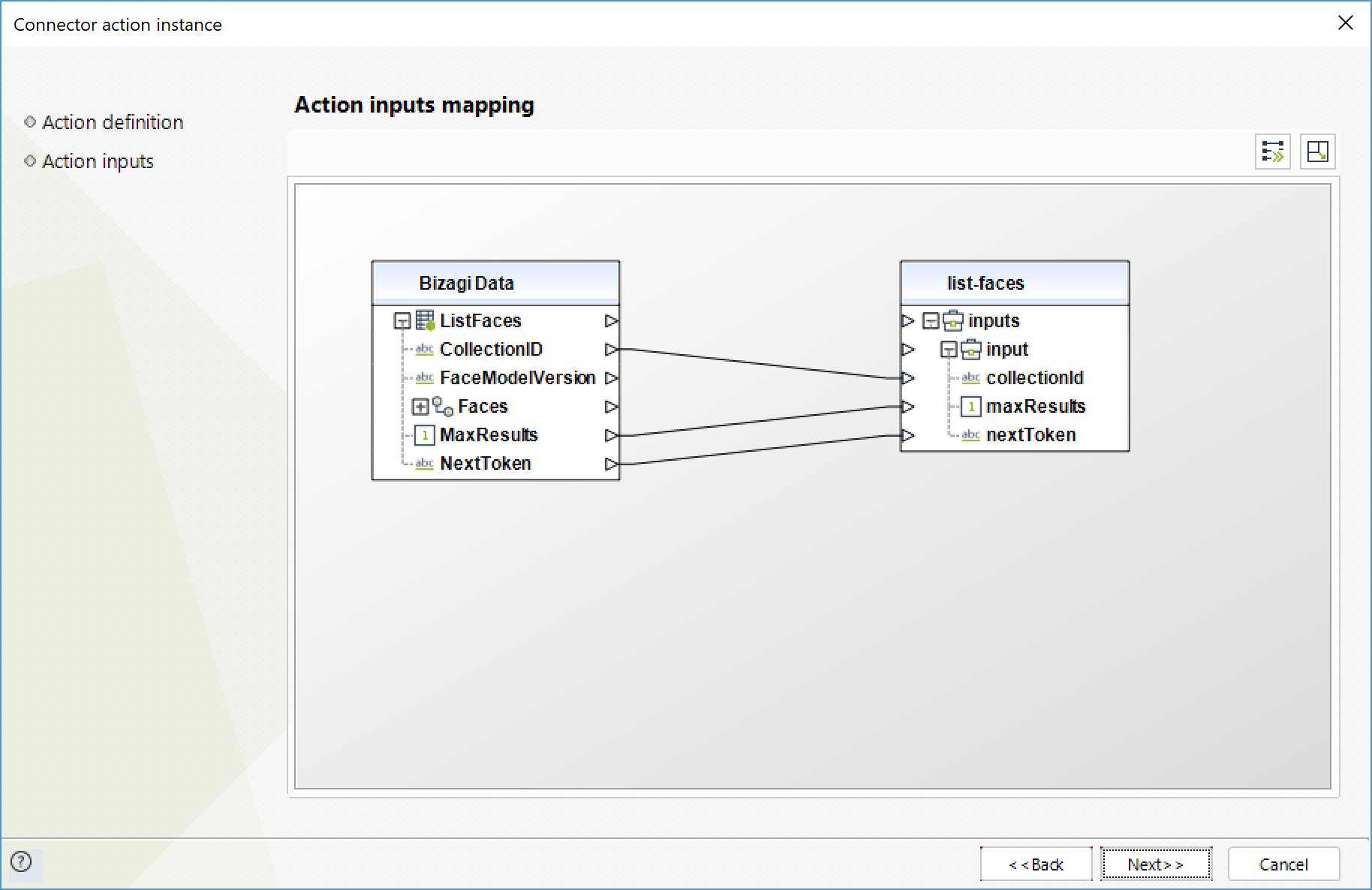
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•Faces (Colección):
oFaceId (Texto): identificador unico que Amazon Rekognition le asigna a la cara
▪BoundingBox (Objeto): caja que enmarca la cara detectada.
•Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
•Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
•Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
•Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪ImageId (Texto): identificador unico que Amazon Rekognition le asigna a la imagen de entrada
▪ExternalImageId (Texto): identificador que se asigna a todas las entradas de la imagen de entrada
▪Confidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
oNextToken (Texto): si el resultado está truncado, la respuesta provee este valor para utilizarlo en peticiones subsecuentes para buscar el siguiente conjunto de IDs de colecciones
oFaceModelVersion (Texto): número de la versión del modelo de detección de caras asociado a la colección de entrada
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#listFaces-property.
Buscar caras (Search faces)
Para un ID de una cara dado, busca las caras que coincidan en la colección a la que la cara pertenece.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•CollectionID (Texto - Requerido): ID de la colección de la que se obtendrán las caras.
•FaceID (Texto - Requerido): ID de la cara a buscar.
•MaxFaces (Entero): Número máximo de resultados a retornar.
•faceMatchThreshold (Flotante): Nivel mínimo de confianza para que un resultado se tenido en cuenta en la respuesta.
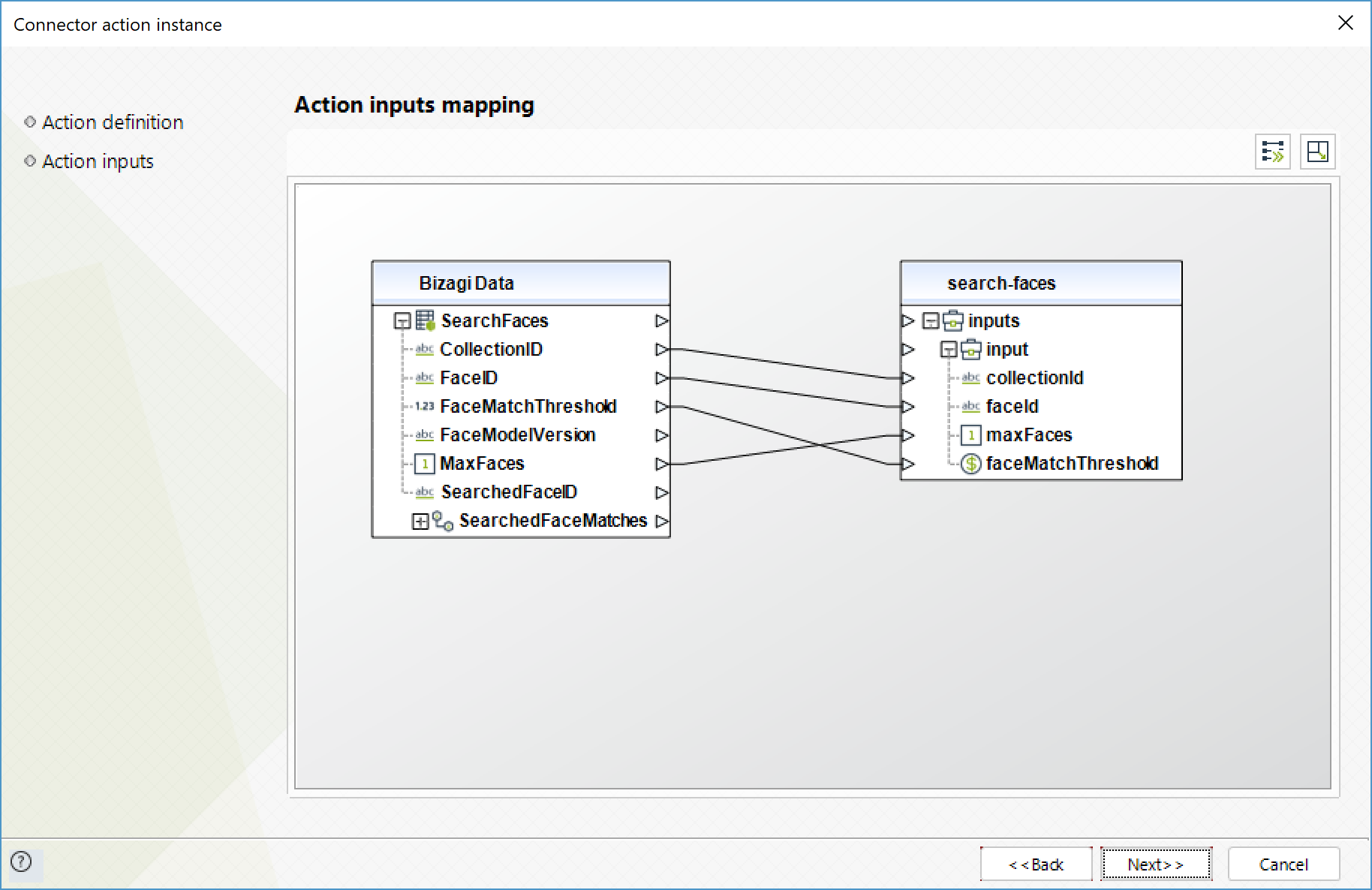
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•SearchedFaceId (Texto): ID de la cara de la cual se buscaron matches en la coleccion
•FaceMatches (Colección): colección de las caras encontradas según la búsqueda realizada.
oFace (Objeto): cara detectada.
oFaceId (Texto): identificador unico que Amazon Rekognition le asigna a la cara
oBoundingBox (Objeto): caja que enmarca la cara detectada.
▪Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
▪Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
▪Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
oImageId (Texto): identificador unico que Amazon Rekognition le asigna a la imagen de entrada
oExternalImageId (Texto): identificador que se asigna a todas las entradas de la imagen de entrada
oConfidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
oSimilarity (Flotante): confianza en el match de esta cara con la cara de entrada
•FaceModelVersion (Texto): número de la versión del modelo de detección de caras asociado a la colección de entrada
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#searchFaces-property.
Buscar caras por imagen (Search faces by image)
Para una imagen de entrada, detecta la cara mas grande y luego busca en la colección especificada las caras que concuerdan.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•CollectionID (Texto - Requerido): ID de la colección de la que se obtendrá las caras.
•Data (Texto - Requerido): Imagen de la cara a buscar codificada en formato base64.
•MaxFaces (Entero): Número máximo de resultados a retornar.
•faceMatchThreshold (Flotante): Nivel de confianza mínimos para que un resultado sea incluido en la respuesta.
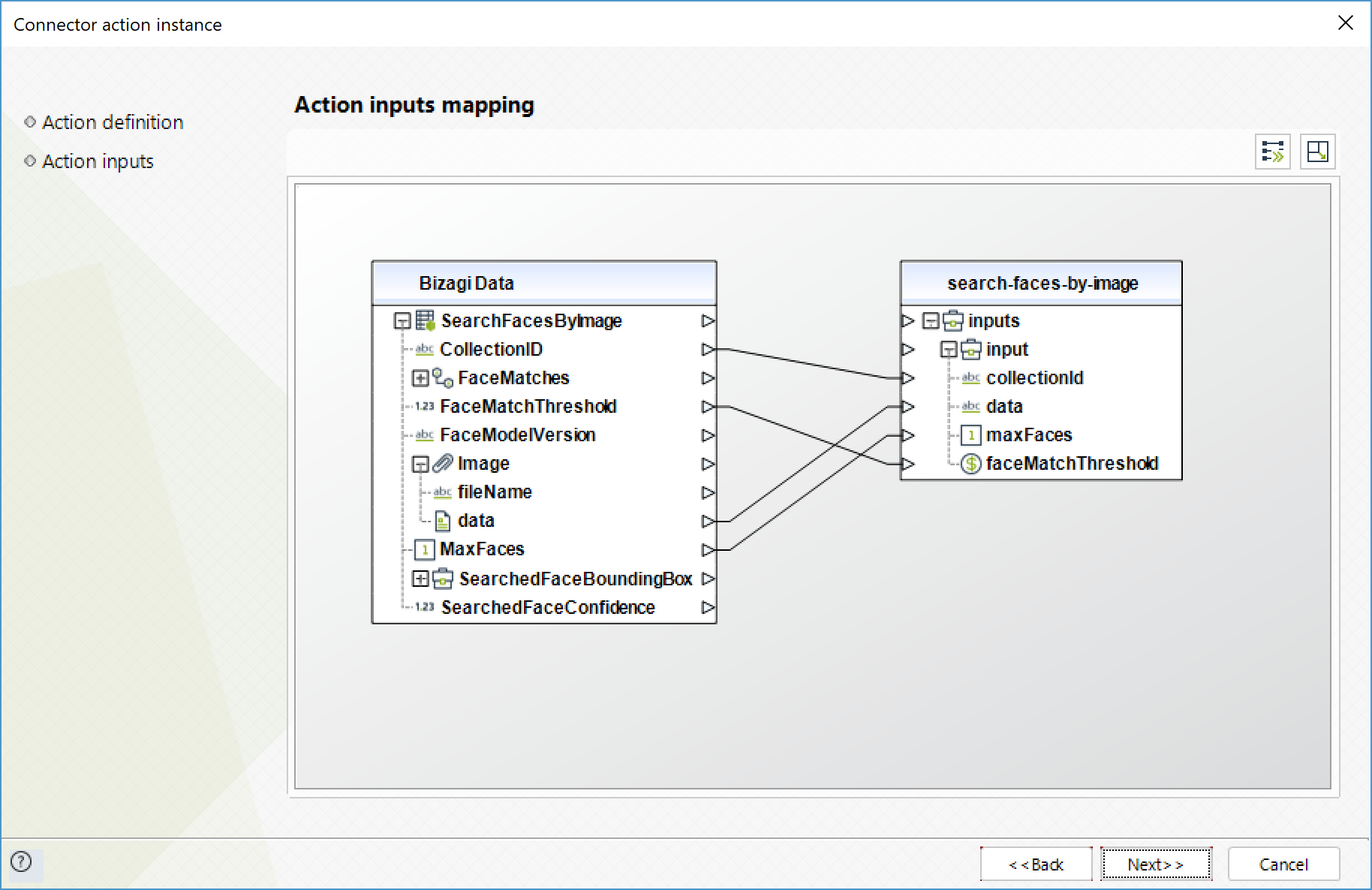
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•SearchedFaceBoundingBox (Objeto): el bounding box alrededor de la cara en la imagen de entrada que Amazon Rekognition utiliza para la busqueda. Rekognition primero detecta la cara mas grande en la imagen y luego busca en la colección las caras que hagan match
oWidth (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
oHeight (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
oLeft (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
oTop (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
•SearchedFaceConfidence (Flotante): nivel de confianza que el SearchedFaceBoundingBox contiene una cara
•FaceMatches (Colección): colección de las caras encontradas según la búsqueda realizada.
oFace (Objeto): cara detectada.
oFaceId (Texto): identificador unico que Amazon Rekognition le asigna a la cara
oBoundingBox (Objeto): caja que enmarca la cara detectada.
▪Width (Flotante): ancho de la caja que rodea la cara como una proporción del ancho total de la imagen
▪Height (Flotante): alto de la caja que rodea la cara como una proporción del alto total de la imagen
▪Left (Flotante): coordenada (izquierda) de la caja que rodea la cara como una poporción del ancho total de la imagen
▪Top (Flotante): coordenada (arriba) de la caja que rodea la cara como una poporción del ancho total de la imagen
oImageId (Texto): identificador unico que Amazon Rekognition le asigna a la imagen de entrada
oExternalImageId (Texto): identificador que se asigna a todas las entradas de la imagen de entrada
oConfidence (Flotante): nivel de confianza que indica que lo que contiene el BoundingBox es una cara
oSimilarity (Flotante): confianza en el match de esta cara con la cara de entrada
•FaceModelVersion (Texto): número de la versión del modelo de detección de caras asociado a la colección de entrada
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#searchFacesByImage-property.
Eliminar caras (Delete faces)
Elimina las caras especificadas de una colección dada.
Para configurar las entradas, tenga en cuenta los siguientes parámetros:
•FaceIDs (Texto - Requerido): IDs de las caras para eliminar de la colección.
•CollectionID (Texto - Requerido): ID de la colección de la que se eliminarán las caras.
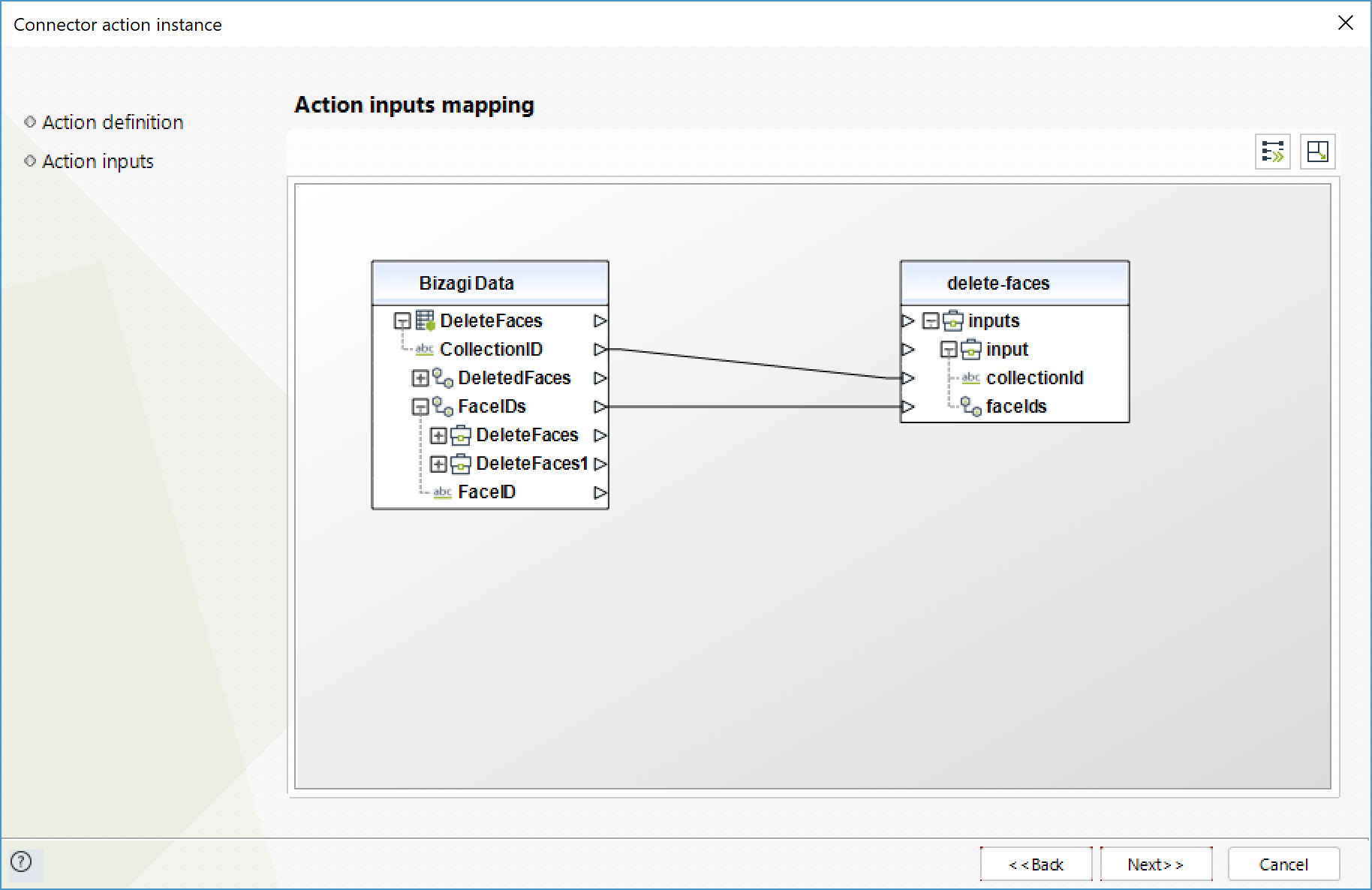
Para configurar las salidas de la acción, puede mapear el objeto de salida con la entidad correspondiente en Bizagi. Asegúrese de mapear los atributos correctamente.
•DeletedFaces (Colección): arreglo de strings con los IDs de las caras que fueron eliminadas
Para mas información sobre estos métodos, refiérase a la documentación oficial de Amazon Rekognition en https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Rekognition.html#deleteFaces-property.
Last Updated 10/28/2022 4:06:11 PM